メソッドの概要
(数学が好きではなく、式が怖い人は、すぐに「メソッドの比較」に行くことができます)。マルコフランダムフィールドまたはマルコフネットワーク(マコフチェーンと混同しないでください)は、いくつかのランダム変数のセットの共同分布を表すために使用されるグラフモデルです。 正式には、マルコフランダムフィールドは次のコンポーネントで構成されます。
- 無向グラフまたは因子グラフG =(V、E)、各頂点
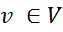 ランダム変数Xおよび各エッジ
ランダム変数Xおよび各エッジ 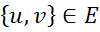 確率変数uとvの関係を表します。
確率変数uとvの関係を表します。 - 潜在的な機能または要因のセット
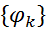 、グラフ内の各クリークに1つ(クリークは無向グラフの完全なサブグラフG)。 機能
、グラフ内の各クリークに1つ(クリークは無向グラフの完全なサブグラフG)。 機能 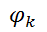 クリーク要素の各可能な状態に、非負の実数値を関連付けます。
クリーク要素の各可能な状態に、非負の実数値を関連付けます。
隣接していない頂点は、条件付きで独立したランダム変数に対応する必要があります。 隣接する頂点のグループはクリークを形成し、頂点状態のセットは対応する潜在的な関数の引数です。
一連のランダム変数の共同分布
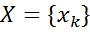 マルコフランダムフィールドでは、次の式で計算されます。
マルコフランダムフィールドでは、次の式で計算されます。
(1)
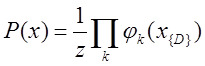 、
、
どこで
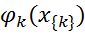 -k番目のクリークの確率変数の状態を記述する潜在的な関数。 Z-正規化係数は次の式で計算されます:
-k番目のクリークの確率変数の状態を記述する潜在的な関数。 Z-正規化係数は次の式で計算されます:
(2)
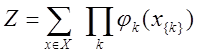 。
。
多くの入力トークン
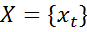 および多くの関連タイプ
および多くの関連タイプ 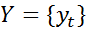 集合的に多くのランダム変数を形成します
集合的に多くのランダム変数を形成します 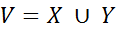 。 テキストから情報を抽出する問題を解決するには、条件付き確率P(Y | X)を決定すれば十分です。 可能な関数の形式は次のとおりです。
。 テキストから情報を抽出する問題を解決するには、条件付き確率P(Y | X)を決定すれば十分です。 可能な関数の形式は次のとおりです。
 どこで
どこで 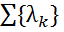 実数値のパラメトリックベクトル、および
実数値のパラメトリックベクトル、および
 -機能のセット。 線形条件付きランダムフィールドは、次の形式の確率分布です。
-機能のセット。 線形条件付きランダムフィールドは、次の形式の確率分布です。
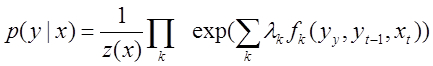 。
。
正規化係数は、次の式で計算されます:Z(x):
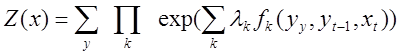 。
。
メソッド比較
MERFメソッド(最大エントロピーマルコフモデル)と同様に、CRFメソッドは、HMM(隠れマルコフモデル)やNaive Bayesメソッドなどの生成的メソッドとは対照的に、判別確率論的メソッドを指します。
MEMMとの類推により、観測値が存在する状態間の遷移の確率を設定するための因子係数の選択
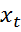 特定のデータの詳細に依存しますが、同じMEMMとは異なり、
特定のデータの詳細に依存しますが、同じMEMMとは異なり、
CRFは、ソースデータの機能と相互依存性を考慮できます。 記号ベクトル
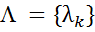 トレーニングサンプルに基づいて計算され、各潜在的な関数の重みを決定します。 モデルのトレーニングとアプリケーションには、HMMアルゴリズムに類似したアルゴリズムが使用されます。Viterbiとそのバリアント-前方後方アルゴリズム。
トレーニングサンプルに基づいて計算され、各潜在的な関数の重みを決定します。 モデルのトレーニングとアプリケーションには、HMMアルゴリズムに類似したアルゴリズムが使用されます。Viterbiとそのバリアント-前方後方アルゴリズム。
隠れマルコフモデルは、線形条件付きランダムフィールド(CRF)の特殊なケースと見なすことができます。 同様に、条件付きランダムフィールドは、一種のマルコフランダムフィールドと考えることができます(図を参照)。

図 HMM、MEMM、およびCRFメソッドのグラフ画像。 塗りつぶされていない円は、モデルで確率変数の分布が考慮されていないことを示します。 矢印は依存ノードを示します。
条件付きランダムフィールドでは、いわゆる ラベルバイアス問題-単一の確率分布が構築され、正規化(式(5)からの係数Z(x))が全体として実行されるため、遷移が少ない状態が優先される状況。 もちろん、これはこの方法の利点です。アルゴリズムは、観測された変数の独立性の仮定を必要としません。 さらに、任意の要因を使用することで、決定されるオブジェクトのさまざまな機能を説明できるため、トレーニングサンプルの完全性とボリュームの要件が軽減されます。 解決される問題に応じて、実際には、数十万から数百万の用語で十分です。 さらに、精度はサンプルサイズだけでなく、選択した要因によっても決定されます。
CRFアプローチの欠点は、トレーニングサンプルの分析の計算の複雑さであり、これにより、新しいトレーニングデータが到着したときにモデルを絶えず更新することが難しくなります。
CRFメソッドとコンピューター言語学で使用される他のいくつかのメソッドとの比較は、[3]にあります。 この論文では、提案された方法がさまざまな言語問題を解決する際に他の方法(F1による)よりも優れていることが示されています。 たとえば、テキスト内の名前付きエンティティを自動的に検索するタスクでは、CRFはMEMMメソッドと比較してわずかに低い精度を示しますが、同時に完全性においてもかなり勝ちます。
CRFアルゴリズムの実装の速度が速いことを追加する必要があります。これは、大量の情報を処理する場合に非常に重要です。
今日では、テキストからオブジェクトを抽出する最も一般的で正確な方法はCRFメソッドです。 たとえば、スタンフォード大学の名前付きエンティティ認識ツールのスタンフォード大学プロジェクトで実装されました。 また、このメソッドは、さまざまな種類の言語テキスト処理用に正常に実装されています。
参照資料
- Lafferty J.、McCallum A.、Pereira F.「 条件付きランダムフィールド:シーケンスデータのセグメント化とラベル付けのための確率モデル 」。 第18回機械学習に関する国際会議の議事録。 282-289。 2001年。
- Klinger R.、Tomanek K。:古典的確率モデルと条件付きランダムフィールド。 アルゴリズムエンジニアリングレポートTR07-2-013。 コンピュータサイエンスの。 ドルトムント工科大学。 2007年12月。ISSN1864-4503。
- アントノバA.Yu.、ソロビエフA.N. ロシア語テキストの処理の問題における条件付きランダムフィールドの方法。 「情報技術とシステム-2013」、カリーニングラード、2013。
http://itas2013.iitp.ru/pdf/1569759547.pdf - Stanford Named Entity Recognizer // http://www-nlp.stanford.edu/software/CRF-NER.shtml