
多くのデータがありませんか? それが起こるように。 Avinash Koshikが完全に定式化したデータのパラドックスを思い出してください。 データが不足していると意思決定はできませんが、豊富な情報では何が起こっているのかわかりません。
それでは、答えを探し始めましょうか? 結論を導き、情報を扱うことに大きな喜びをもたらす普遍的な方法についてお話します。 インターネットマーケティングやWeb分析から遠く離れたユーザーが退屈しないように、たとえば、日常の現実からトピックを取り上げました。
データを扱う主な段階
データの操作はいくつかの段階で構成されていますが、厳密な順序に従う必要はありません。前の段階に戻って先に進む必要があります。
1.準備する
-質問の文言。
-ソースの選択。
-データ収集。
-研究。
-データのクレンジングと仮定。
2.分析
-提起された質問への回答を検索します。
-パターンを検索します。
-依存関係を検索します。
3.結果のデモンストレーション
-データの視覚化。
-ソリューションのデモ、回答。
行こう!
準備する
質問の文言
データは心のtrapです。 彼らは森に数字を誘い込み、簡単に迷子になります。 目標から逸脱しないように、答えを知りたい質問をしてください。 それを自由形式で定式化し、紙に書きます。 簡単な質問にしましょう。「私のサイトは良いものか悪いものを売っていますか?」または「買い手はどこからサイトから消えたのですか?」。 次に、一般的な質問をサブ質問に分割し、リストに追加します。 たとえば、サイトでの販売の質問には、どの製品がよく売れていて、どれが悪いかというサブ質問が適切です。 用紙に空のスペースを残すことを忘れないでください。後続の手順でリストに追加する可能性があります。
私の質問は:
近年のロシアの外交政策とは何ですか?
(実生活からデータを取得すると警告しました)。
サブ質問:
- 過去数年間のロシアの外交政策における活動は何ですか?
- ロシアはどの国と最も積極的に交流していますか?
- 他の国との交流における選好はどのように変化しましたか?
2007年2月から2014年9月までのミュンヘン会議後の外交政策プロセスに興味があります。質問を定式化したので、今から情報源を検索します。
データソースの選択
ソースの重要な要件:ソースを構成するデータは、関連性があり均質である必要があります。
関連性とは、提示された質問に答えるために必要かつ十分な最小限の情報が含まれており、元の情報源に近いことを意味します。
歴史科学には、ソーススタディと呼ばれる業界全体があります。 彼女は、情報源の分類と分析に従事しており、一次情報源と二次情報源の概念を操作しています。 最も信頼性の高い結果を得るには、主要なソース(外部の人によって処理されていない直接のメッセージ)を使用することが重要です。 たとえば、外交政策のイベントに関するウィキペディアのデータは、主要なソースではありません。 主な情報源は、会議の日付と参加者のリストを含む最高幹部会議の議事録です。
2番目のデータ要件は均一性です。 オブジェクトのセット全体で性質が変わらない共通のプロパティの存在が前提条件です。 言い換えれば、データの構成は質的に均一でなければなりません。 Yandex.MetricaとGoogle Analyticsのメトリックを比較して追加するのは正しくありません。それらの処理方法は異なる可能性があるためです。 反対の写真をよく見ますが。
外交政策に戻りましょう。 データソースについては、サイトkremlin.ruからロシアの参加を得て、重要な外交政策イベントに関する公式レポートを取りました。 公式のプレスリリースは主要な情報源ではないという事実にもかかわらず、私たちは仕事でそれらを使用することができます。 それらは可能な限りソースに近い。 出版物は、一方では、クレムリンのコンテンツマネージャーとPRサービスの仕事の質を反映し、他方では、イベントに直接関連しています。
1) 外交政策セクションのアーカイブからのデータ
2) 「外交政策」というタグに関するニュース (2008/08/08〜2014/10/14)
先に進み、最初のソースの使用を放棄しなければならないと言います。 2009年9月以降、アーカイブにはニュースが補充されなくなりました。さらに、最初と2番目のケースでは、ニュースを説明するためのさまざまな原則が使用されました。
ソースを決定したら、作業の最も複雑で重要な部分であるデータ収集に進みます。
収集、研究、清掃、仮定
後でExcelでレコードを操作するのに便利になるように、サイトのセクションをCSVテーブルに解析するようにプログラマーに依頼しました。 便利なデータ分析ツールを自由に選択できます。
重要な詳細:リレーショナルデータ組織モデルを使用する必要があります。
簡単に言えば、新しいレコードはそれぞれ新しい行に配置され、属性は列に配置され、1つのデータ型(日付、テキスト、番号など)に属する必要があります。 均質で高品質のデータベースの作成に努めています。
私の例では、行のエントリは外交政策イベントのトピックに関するユニークな出版物です。 Excelでは、イベントの日付、イベントの種類、イベントの参加者/参加者などの属性を持つ行のエントリのように見えます。
2つのセクションを解析するのは簡単ではありませんでした。このサイトではエラー402支払いが必要でした。 データの0.18%の損失を許容できる場合、異なるソースから異なる属性を持つ2つのテーブルが手元にあるという事実は無視できません。 それらを組み合わせると、データの均一性の原則に違反するため、両方のソースからの交差する期間をさらに比較する必要があり、最終的に最初のソースを削除することにしました。 最終的に、2008年5月8日から2014年10月14日までの期間に3326件のイベントレコードを受け取りました。
次に、受信したデータを調査する必要があります。 Excelには、グループ化、フィルター、並べ替え、ピボットテーブルなどのシンプルで便利なツールがあり、ほとんどのタスクに十分です。 興味を持ってセルの内容を調べ、見出しのイベントの繰り返し名に注目しました。 会議、電話での会話、文書の署名、および式典に関する出版物は、うらやましいほどの不変の条件で満たされました。 レコードに対して新しい属性「イベントタイプ」が要求されたため、別の列を作成し、対応する値を入力しました。

すべてのイベントが明確に解釈されたわけではないことに注意することが重要です。 たとえば、会議の開始に関するメッセージと、会議での交渉に関するメッセージは、1つのタイプの「会議」イベントに起因しました。つまり、データベースには1つのイベントに関する複数のレコードが存在する可能性があります。 仮定は記録され、すべてのデータに適用されました。
2008年5月8日から2014年10月14日までの調査期間は、V.V。 プーチン大統領とD.A. メドベージェフ。 日付を思い出させてください:
V.V. プーチン-2000年7月5日-2008年5月7日
D.A. メドベージェフ-2008年5月7日-2012年5月7日
V.V. プーチン-2012年5月7日-プレゼント
この作業段階は最も長く、最も責任がありました。 フィルター、グループ化されたレコードを介してデータを複数回実行し、値の正確性、データ型を確認した結果、必要な均一性と正確性を達成しました。
データ分析
データを準備した直後に、休憩を取って最初に戻ることが重要です-私たちが定式化した質問に。 この時点で思考が現在の研究の範囲をはるかに超えていることがよくあるので、最初に戻ることが重要なことを見逃さないための最良の方法になります。
現在、結論を出しつつあります。 分析段階では、バイアスを回避することが重要です。 既成の仮説を証明したいという願望を持って研究に着手することは可能ですが、可能な選択肢の存在を忘れないでください。 トラフィックが少ないために直帰率が増加したことを証明しようとしても、最近のリリース後にサイトの読み込み速度が低下することはありません。
別の注意点は、依存関係とパターンを見つけることです。 私たちの日常的な見方では、原因と結果は対になっているため、ある値が別の値にどのように影響するかを本当に知りたいのです。 しかし、社会現象、およびサイトでのユーザーの行動もそれらに適用され、原因と結果の多様性が特徴です。 1つの現象の異なる兆候を反映する2つの類似した曲線をグラフに表示しても、それらの間に関係はありません。 値間の相関関係の存在に関する結論は常に確率的です。
それでは、外交政策に関する質問への答えに取り掛かりましょう。
結果のデモンストレーション
過去数年間の外交政策におけるロシアの活動は何ですか。

2010年に、外交政策問題に関するニュースの最大数が公開されました。
ロシアが最も頻繁に交流した国のリストは何ですか。 調査期間中のメッセージの最大数が蓄積された上位5か国のリストをまとめました。 国際関係の主要な参加者に注目します。 後続の段階でサンプルから誰かが突然姿を消した場合、これはデータを再度確認したり、新しい質問をするためのシグナルとして機能します。

ニュースで言及されているイベントの中で最も人気のあるタイプは何ですか?また、期間中の機能や変更はありますか?
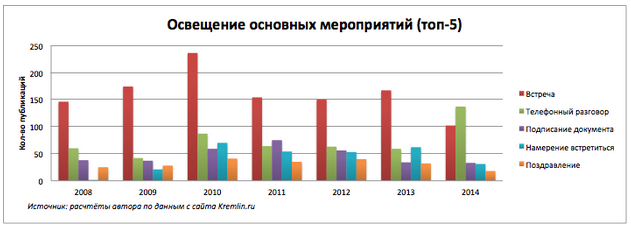
2010年の会議に関するプレスリリースの数は最大です。 2014年には、電話での会話に関するメッセージの数が急増しました。
ロシアの政治家はより多くの話をし、会うことを少なくし始めた。 業務上および緊急のタスクでは、必要なセレモニーが少なくなります。
2014年に電話での会話が増えた国や組織はどれかと思います。 2014年の電話会話の最大数を持つ参加者を選択しました。
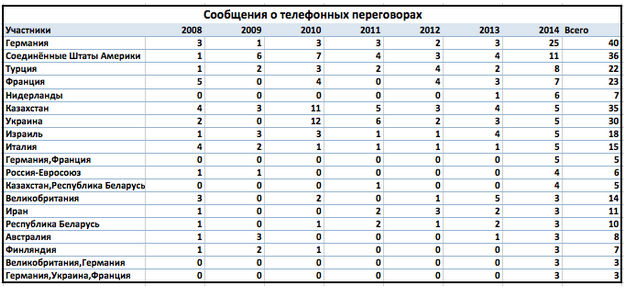
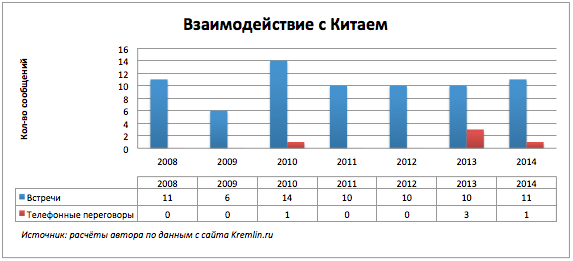
2014年には、電話での会話の参加者のユニークなグループと、多くの国との直接的な接触の増加を観察しています。 国際関係の主要な参加者の中で、中国はリストに載っていません。これが何に関係しているのかを後で調べます。
多国間電話での会話を考慮して、国ごとにメッセージ数をプロットします。
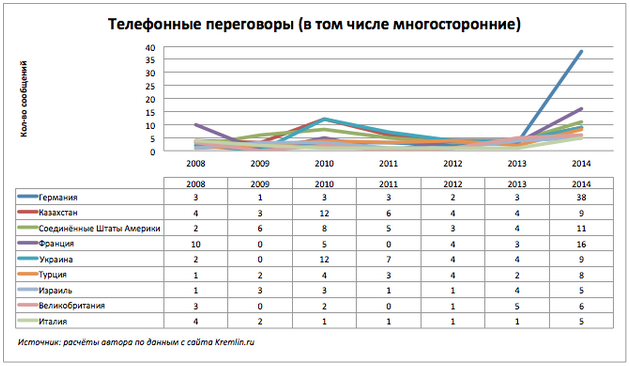
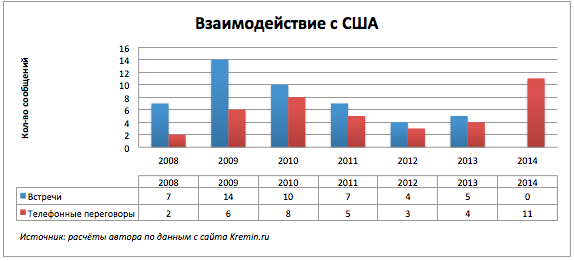
ドイツ、フランス、および米国との電話での会話の顕著な増加。
会議はどうですか? 会議をリードする国々を取り上げ、全体像を見てください。
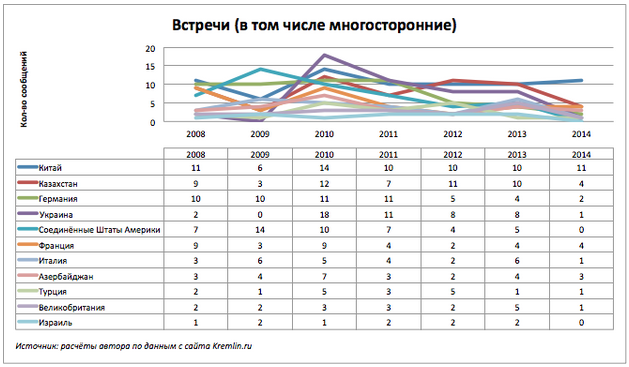
スケジュールは最も示唆的なものではありませんが、データ表は、2014年10月14日には米国およびイスラエルとのロシア会議の報告がないことを示しています。
ロシアと特定の国との相互作用の性質は興味深いです。 会議の2つの重要なイベントと国ごとの電話について引き続き検討します。
東の隣人は電話で話すのが嫌いです。

今年度の電話はすべての記録を破った。
すでに年末で、会議はありません。
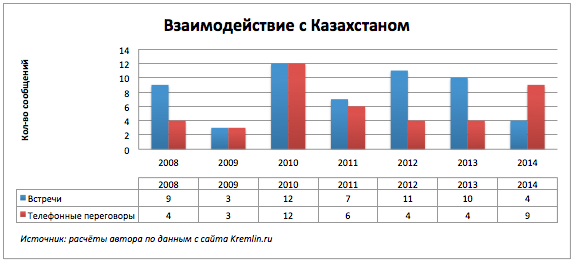
ホッピングの変更。
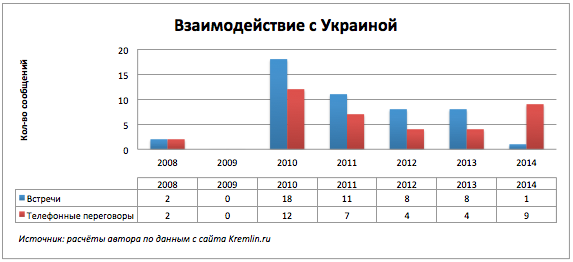
2009年、その年は完全に穏やかです。 コミュニケーションの欠如は、おそらく2008年から2009年のロシアとウクライナ間のガス紛争によるものです。
「参加者」列には、カンマで区切られた1つまたは複数の国、または国と組織を示すいくつかのタイプの値があります。
政治家間の会議は二国間および多国間です。 ロシアが二国間交渉で、多国間交渉でより頻繁に会う国を見るのは興味深い。
これを行うために、データに別の属性を追加しました。これは、会議の総数と二国間の数の比率に等しい係数です。 平均を下回っている国々は、主に二国間会議で交渉しています。 平均以上の人々は多国間で積極的に参加しています。
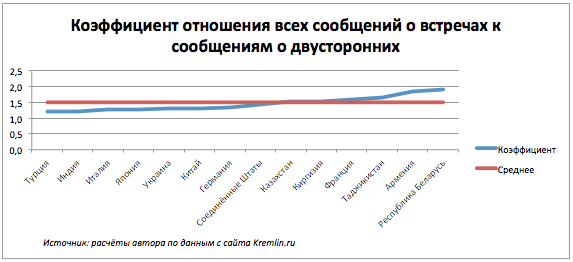
CIS諸国が交点に近く、平均以上であったという事実には驚くべきことはありません。彼らは共同フォーラムやサミットに参加しています。 しかし、フランスは彼らの会社で何を忘れていましたか? 期間全体にわたってフランスが関与したすべての出来事の要約表を作成したところ、フランスは2008年のグルジア南オセチア紛争を解決するための交渉の第三者であることが判明しました。
***
もちろん、このデータから多くの興味深いことが得られますが、質問に対する答えは得られました。つまり、目標は達成されました。 さらに:今、私は常に外交政策の現在の状況をより深く理解するための情報を手元に持っています。 ご覧のように、数値の収集を停止して特定の質問を開始すると、データは有用で興味深い結論の言語で回答します。
最後に、Avinash Koshikの仕事の最初の場所についての私のお気に入りの話をします。 Web分析の分野における将来の世界的専門家は、200のレポートが構成された会社に来ました。 アビナッシュ・コシクが到着してから一ヶ月後、彼らは全員を切り離した。 2週間が経過し、誰もその損失に気付きませんでした。
更新しました。 約束のファイル
1. ソース
2. 処理
パスワードを開く:habr2014