
有名な闇市場であるシルクロードは、約1年前に閉鎖されました。 最近まで、私は彼が死んだと思っていました。 これにより、記事を書くのが簡単になりますが、すべてがうまくいくとは限りません。 彼がネットワークに戻ってきたことを読んだばかりです。
次に、サイトの「古い」バージョンのキャプチャを読み取るためのメカニズムを解析するために、数年前に書いたコードを詳しく調べたいと思います。
やる気
私はグウェルンの記事で最初にシルクロードについて聞いた。 Torを接続した後、私はこのサイトを見る機会を得ました。
私の最初の考えはこれです。プログラムでアクセスするのが難しい興味深いリアルタイムの市場データがたくさんあります。
実際に価格が更新されたドラッグウォーズですか?
MJ ▲0.21
を示すインデックス
MJ ▲0.21
、
COKE ▼3.53
?
しばらくして、これらすべての製品の価格変更の履歴を収集できました。
私はすでに
Sr::Listing
のグラフ、スキーム、およびケースを想像し始めました。 まず、承認プロセスを自動化する必要があります。
この記事のすべてのコードはRubyで表示されますが、次の2つの理由でAPIを公開しません。
- ほとんどの場合、それはもう機能しません。
- きちんと装飾されたことはありません。
Tor
Silk Roadは、隠れたTORサービスに作り直されました。 したがって、APIはTorにアクセスする必要があります。
Vidaliaは、起動時にSOCKS5プロキシをローカルで開きます。 有効なHTTP要求用にクライアントを構成する必要があります。 幸いなことに、 socksify gemを使用してこれを行うことができます。 このトリックにより、
auto_configure
アプリケーションでSOCKSリクエストを変換できます。
require 'socksify' require 'socksify/http' module Sr class TorError < RuntimeError; end class Tor # Loads the torproject test page and tests for the success message. # Just to be sure. def self.test_tor? uri = 'https://check.torproject.org/?lang=en-US' begin page = Net::HTTP.get(URI.parse(uri)) return true if page.match(/browser is configured to use Tor/i) rescue ; end false end # Our use case has the Tor SOCKS5 proxy running locally. On unix, we use # `lsof` to see the ports `tor` is listening on. def self.find_tor_ports p = `lsof -i tcp | grep "^tor" | grep "\(LISTEN\)"` p.each_line.map do |l| m = l.match(/localhost:([0-9]+) /) m[1].to_i end end # Configures future connections to use the Tor proxy, or raises TorError def self.auto_configure! return true if @configured TCPSocket::socks_server = 'localhost' ports = find_tor_ports ports.each do |p| TCPSocket::socks_port = p if test_tor? @configured = true return true end end TCPSocket::socks_server = nil TCPSocket::socks_port = nil fail TorError, "SOCKS5 connection failed; ports: #{ports}" end end end
すべて準備完了です。 かなり単純なプロセスを作成しました。
キャプチャ
次に、記事のトピックであるSilkRoad captcha bypassに進みます。
これをやったことがないので、面白いはずです。 上記のコードはすべて、6時間の作業の結果です。
アプリケーションがすべてのコードの3分の1の精度でテキストを認識する場合、プロジェクトを成功と呼ぶことにしました。
その結果、計画以上のことが行われました。
シルクロードの作者は自分自身で妄想を展開しなければならなかったという事実のために、彼らはreCAPTCHAのようなサービスを使用できませんでした。 彼らのソリューションが最終的に自作であることが判明したかどうかはわかりませんが、いくつかの例を見てみましょう。




このキャプチャのいくつかの明らかな機能があります。
- 標準形式:0〜999の数字とともに5文字に切り捨てられた辞書の単語。
- フォントは変更されません。
- sivolは、X軸に沿った任意の位置に配置できます。
- 任意のシボルを回転できますが、わずか数度です。
- 背景には、スパイラルのようなものがありますが、テキストと痛烈に対照的ではありません。
- それらはすべてひどくピンク色で、色情報の1つのチャネルを提供します。
Mechanizeを作成し 、2秒の間隔で2,000個のキャプチャの例をサイトからダウンロードしました。 それらを手動で解決した後、形式(テキスト)
.jpg
で呼び出します。 とても悲しかった、信じて。
しかし、利点もあります。新しいアプリケーションでテスト用のサンプルをたくさん入手しました。
背景を削除します
私の意見では、最も適切な開始ステップです。 この段階では、(できれば)シンボルのみを含むグレーの濃淡の画像を取得し、画像のすべての「ノイズ」をふるいにかけたかった。
Gimpを使用して、いくつかのエフェクトとシーケンスを試しました。 エラーが発生しましたが、最終的には次のようになりました。
オリジナル:
修正済み:

グレースケール、0.09:
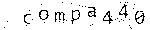
結果は、 RMagickの次のコードで取得されました 。
# Basic image processing gets us to a black and white image # with most background removed def remove_background(im) im = im.equalize im = im.threshold(Magick::MaxRGB * 0.09) # the above processing leaves a black border. Remove it. im = im.trim '#000' im end
これにより、不必要な詳細からイメージが解放されましたが、それでも「ゴミ」、つまり文字間に小さな黒い点がありました。 それらを取り除きましょう:
# Consider a pixel "black enough"? In a grayscale sense. def black?(p) return p.intensity == 0 || (Magick::MaxRGB.to_f / p.intensity) < 0.5 end # True iff [x,y] is a valid pixel coordinate in the image def in_bounds?(im, x, y) return x >= 0 && y >= 0 && x < im.columns && y < im.rows end # Returns new image with single-pixel "islands" removed, # see: Conway's game of life. def despeckle(im) xydeltas = [[-1, -1], [0, -1], [+1, -1], [-1, 0], [+1, 0], [-1, +1], [0, +1], [+1, +1]] j = im.dup j.each_pixel do |p, x, y| if black?(p) island = true xydeltas.each do |dx2, dy2| if in_bounds?(j, x + dx2, y + dy2) && black?(j.pixel_color(x + dx2, y + dy2)) island = false break end end im = im.color_point(x, y, '#fff') if island end end im end
そこで、次のようなものを得ました。
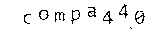
いいね
セグメンテーション
次に、キャプチャをラスターイメージにカットして、それぞれに1つの文字が含まれるようにします。 画像を左から右に移動して、白い余白を探します。
# returns true if column "x" is blank (non-black) def blank_column?(im, x) (0 ... im.rows).each do |y| return false if black?(im.pixel_color(x, y)) end true end # finds columns of white, and splits the image into characters, yielding each def each_segmented_character(im) return enum_for(__method__, im) unless block_given? st = 0 x = 0 while x < im.columns # Zoom over to the first non-blank column x += 1 while x < im.columns && blank_column?(im, x) # That's now our starting point. st = x # Zoom over to the next blank column, or end of the image. x += 1 while x < im.columns && (!blank_column?(im, x) || (x - st < 2)) # slivers smaller than this can't possibly work: it's noise. if x - st >= 4 # The crop/trim here also removes vertical whitespace, which puts the # resulting bitmap into its minimal bounding box. yield im.crop(st, 0, x - st, im.rows).trim('#fff') end end end
これにより、キャプチャが次のように分割されます。
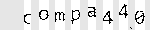
次に、各ピースが文字の付いた個別の正方形に変わり、それによって他のピースから分離されます。
以前に準備した多くのキャプチャに対してこのコードを実行しましたが、場合によっては次のようになりました。

ヒストグラムと考えてください。 暗い領域は、アルゴリズムが画像をカットする場所です。 変位を観察できます...
また、文字の回転が結果の明瞭さにどのように影響するかを確認します。 シンボルが大きな角度で回転した場合、タスクは非常に複雑になります。
したがって、各文字は非常に読みやすくなっています。 文字は英語の辞書から取得されるため、より頻繁に使用される文字がより明確に表示されます。 この問題については後で検討します。
しかし、Jが使用されることはめったにありませんでした!
文字認識のためのニューラルネットワーク
AI4Rと呼ばれるRuby用のクールなgemがあります。
Ai4r::Positronic
常に利用できると
Ai4r::Positronic
限らなかったため、ニューラルネットワークを使用することにしました。
空のビット配列から始めます。 よく知られているソリューションからの図面で彼を訓練します。
- 「このようなモデルはAを表します。」、
- 「そして、このモデルはAにもあります。」
- 「このモデルはVにあります。」
多くの例をチェックした後、いくつかの適切な候補文字が表示され、ネットワークは独自のデータベースを使用して適切なオプションを通知します。
しかし、困難もあります。 使用する文字が多く、指定する認識パラメーターが多いほど、アルゴリズムのトレーニングに時間がかかります。
各シンボルを正方形に取り、サイズを20x20にし、モノクロ効果を適用して、トレーニングを開始しました。
require 'ai4r' require 'RMagick' module Sr class Brain def initialize @keys = *(('a'..'z').to_a + ('0'..'9').to_a) @ai = Ai4r::NeuralNetwork::Backpropagation.new([GRID_SIZE * GRID_SIZE, @keys.size]) end # Returns a flat array of 0 or 1 from the image data, suitable for # feeding into the neural network def to_data(image) # New image of our actual grid size, then paste it over padded = Magick::Image.new(GRID_SIZE, GRID_SIZE) padded = padded.composite(image, Magick::NorthWestGravity, Magick::MultiplyCompositeOp) padded.get_pixels(0, 0, padded.columns, padded.rows).map do |p| ImageProcessor.black?(p) ? 1 : 0 end end # Feed this a positive example, eg, train('a', image) def train(char, image) outputs = [0] * @keys.length outputs[ @keys.index(char) ] = 1.0 @ai.train(to_data(image), outputs) end # Return all guesses, eg, {'a' => 0.01, 'b' => '0.2', ...} def classify_all(image) results = @ai.eval(to_data(image)) r = {} @keys.each.with_index do |v, i| r[v] = results[i] end r end # Returns best guess def classify(image) res = @ai.eval(to_data(image)) @keys[res.index(res.max)] end end end
Mechanizeツールを変更して、新しいキャプチャをロードしました。 今回、キャプチャはアルゴリズムを解決し、システムで認証を実行しました。
正しく推測されたコードは、自動的に記号的に正方形に分割され、サンプルデータベースに追加されて、アプリケーションの知識が向上しました。
認証の試行が失敗すると、キャプチャは別のフォルダーを送信して、自分で解決できるようにしました。 キャプチャの名前をその答えに変更するとすぐに、アルゴリズムは画像を取得し、それを正方形に分割してベースを補充しました。 時々、私は数十の例を解決しなければなりませんでした。
数時間のトレーニングの後、正常に完了したタスクの割合は90%でした。
残念ながら、キャプチャの長さは通常8文字に等しいため、成功するソリューションの確率は0.90 ** 8、つまり43%でした。 私の当初の目標は達成されましたが、もっと欲しかったです。
語彙と文字の使用頻度を使用する
時々、私たちのネットワークは間違った奇妙な候補ソリューションを発行しました。 フォーマットに合わない奇妙なもの。 彼女はキャラクターを独立して認識し、それ以上のコンテキストなしで結果を組み合わせました。
しかし、キャプチャの「言語」部分はランダムな文字ではなく、実際の単語の一部でした。 特別なリストから単語をトリミングしました。 シートがあれば、論理的な推論のチェーンを構築して、文字認識の結果を改善できます。 これは私が単語のリストを生成する方法です:
cat /usr/share/dict/words *.txt | tr AZ az | grep -v '[^az]' \ | cut -c1-5 | grep '...' | sort | uniq > dict5.txt
その後、
dict5.txt
にはcaptchaに含まれる可能性のあるすべてのオプションが含まれると想定できます。
# Returns the "word" and "number" part of a captcha separately. # "word" takes the longest possible match def split_word(s) s.match(/(.+?)?(\d+)?\z/.to_a.last(2) rescue [nil, nil] end def weird_word?(s) w, d = split_word(s) # nothing matched? return true if w.nil? || d.nil? # Digit in word part?, Too long? return true if w.match /\d/ || w.size > 5 # Too many digits? return true if d.size > 3 # Yay return false end def in_dict?(w) return dict.bsearch { |p| p >= w } == w end
しかし、辞書にない奇妙な単語を修正する方法は?
最初に考えたのは、システムの候補のリストを調べることでしたが、ポイントは異なりました。 残念ながら、このスクリプトは低品質のセグメンテーションを実行しました
この興味深いテーブルを見てみましょう。
# az English text letter frequency, according to Wikipedia LETTER_FREQ = { a: 0.08167, b: 0.01492, c: 0.02782, d: 0.04253, e: 0.12702, f: 0.02228, g: 0.02015, h: 0.06094, i: 0.06966, j: 0.00153, k: 0.00772, l: 0.04025, m: 0.02406, n: 0.06749, o: 0.07507, p: 0.01929, q: 0.00095, r: 0.05987, s: 0.06327, t: 0.09056, u: 0.02758, v: 0.00978, w: 0.02360, x: 0.00150, y: 0.01974, z: 0.00074 }
貧しくてめったに使用されないJに再び気付きましたか?
Peter Norvigが興味深い記事「発音補正の書き方」を書きました 。 辞書と、おそらくスペルミスの単語があります。 それを修正しましょう:
# This finds every dictionary entry that is a single replacement away from # word. It returns in a clever priority: it tries to replace digits first, # then the alphabet, in z..e (frequency) order. As we're just focusing on the # "word" part, "9" is most definitely a mistake, and "z" is more likely a # mistake than "e". def edit1(word) # Inverse frequency, "zq...e" letter_freq = LETTER_FREQ.sort_by { |k, v| v }.map(&:first).join # Total replacement priority: 0..9zq..e replacement_priority = ('0'..'9').to_a.join + letter_freq # Generate splits, tagged with the priority, then sort them so # the splits on least-frequent english characters get processed first splits = word.each_char.with_index.map do |c, i| # Replace what we're looking for with a space w = word.dup; w[i] = ' ' [replacement_priority.index(c), w] end splits.sort_by!{|k,v| k}.map!(&:last) # Keep up with results so we don't end up with duplicates yielded = [] splits.each do |w| letter_freq.each_char do |c| candidate = w.sub(' ', c) next if yielded.include?(candidate) if in_dict?(candidate) yielded.push(candidate) yield candidate end end end end
大きなトリックは置き換えです。 文字の使用頻度のテーブルと、ネットワークによって提案されたオプションと1文字だけ異なる可能性のある単語のリストを使用して、文字を「typo」を修正するために必要な文字に置き換えます。
このステップにより、成功したソリューションの割合が43%から56%に増加しました。 目標が実際に達成されたことを実感しました。
新しい(2番目の)SilkRoadキャプチャの解除に関する記事が間もなく公開されます。 お見逃しなく!
記事ilusha_sergeevichのアイデアをありがとう