内容
ABBYY FineReader(別名「理論的部分」)の仕組みについての短い話をした後、得られた知識の適用に移りましょう。 そして、はい、猫の下にアザラシはありません:すべてが非常に深刻です。
ユーザーはどのようにドキュメント処理に参加できますか?
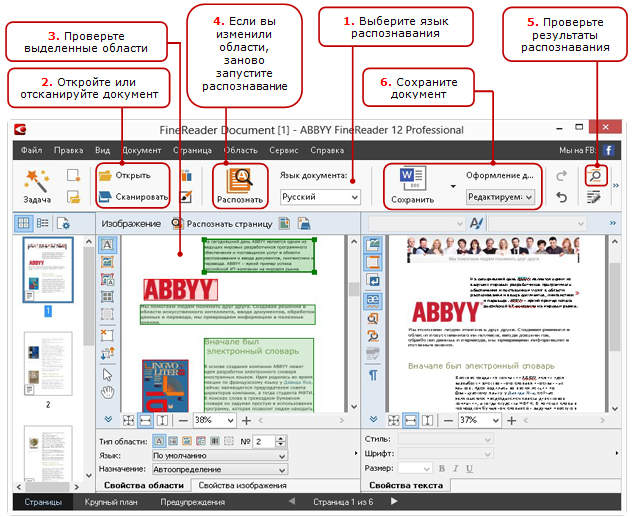
車輪を再発明しないために、ヘルプからのシンプルで理解しやすい図から始めます(右の図を参照)。
さて、すべての操作のリストがわかったので、例を見てみましょう-何が間違っているのか、どのように対処するのか。
良好な画像のみが認識されます。
また、画像はあるが、あまり良い画像ではない場合はどうしますか? FineReaderで可能なすべてを改善し、改善できない場合は、画像を再度取得して、問題を解消します。 このトピックは非常に広範囲に及ぶため、FineReaderで直接自動および手動の画像処理ツールを使用して友だちを作る方法についての別の投稿があります。 それまでは、次の場合にイメージがより良く処理されるという観察に限定します。
- (スキャン後)顕著な幾何学的な歪みはありません-2ページ見開きの背での厚い本のページのゆがみまたは顕著な曲がり、
- (前のものに加えて、写真撮影後)非線形の幾何学的歪み(「枕」、「台形」)がなく、領域全体に均一な焦点(好ましくは明るさ)があり、不十分な照明によるノイズがなく、はっきりした照明がないフラッシュから(特に光沢紙の場合)。
ドキュメント/プロジェクトのセットアップ手順
テキストの言語、画像前処理パラメータ、一部の分析および認識パラメータをすぐに示すことが可能であり、必要です。 これは、設定ダイアログのいずれかのタブのスクリーンショットです。
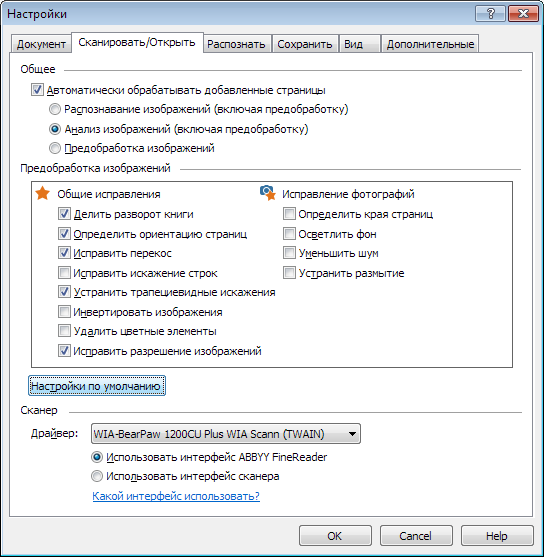
これらの設定およびその他の設定については、ヘルプで詳しく説明されています。
分析段階
プログラムは、認識の観点からさまざまなタイプの領域を自動的に識別します。 この段階で、エリアに個別にマークを付け、分析モジュールを見つけたエリアを(必要に応じて)修正できます。
地域を操作するためのツールについてあまり書き過ぎないように、ヘルプセクションを参照し、ここで何が「何が良い、何が悪い」(領域に関して)、そして悪い結果を修正する方法を説明します。
異なるタイプのエリアを割り当てる
FineReaderユーザーインターフェースにはいくつかのタイプの領域があります。それらには、非表示のプロパティパネル(「画像」ウィンドウの下部)とコンテキストメニュー(右クリックによる)の異なるオプションがあります。
- 「認識ゾーン」 (デフォルトでは灰色のフレーム)-この名前はユーザーインターフェイスで使用されます。私の意見では、「自動分析の領域」と呼ぶ方が正しいでしょう。 このような領域の目的は、一般的にページのどこで有用なものを探す必要があるかを示すことです。 したがって、後続の分析または分析+認識の結果として、各「認識ゾーン」内で、他のタイプのゼロ以上の領域を見つけることができます。 認識ゾーンは、ブロックテンプレートで特に役立ちます(ヘルプで詳しく説明します)。
正しく描画された認識ゾーンの例トルストイデジタル化プロジェクトの実際の例は、ページの一部に行番号(10の倍数の番号を持つ行に番号が付けられている)があることです。これは結果として必要ではなく、自動分析が列のテキスト領域にこれらの番号を含めた場合、テキストの読み取り/編集が困難になります スキャン後にページがほぼ均等に配置されているか、スキャン後に定性的に切断されている場合、分析前に、ブロックテンプレートをページの目的のグループに適用できます。この場合、認識領域には必要のないページの部分が含まれていません:
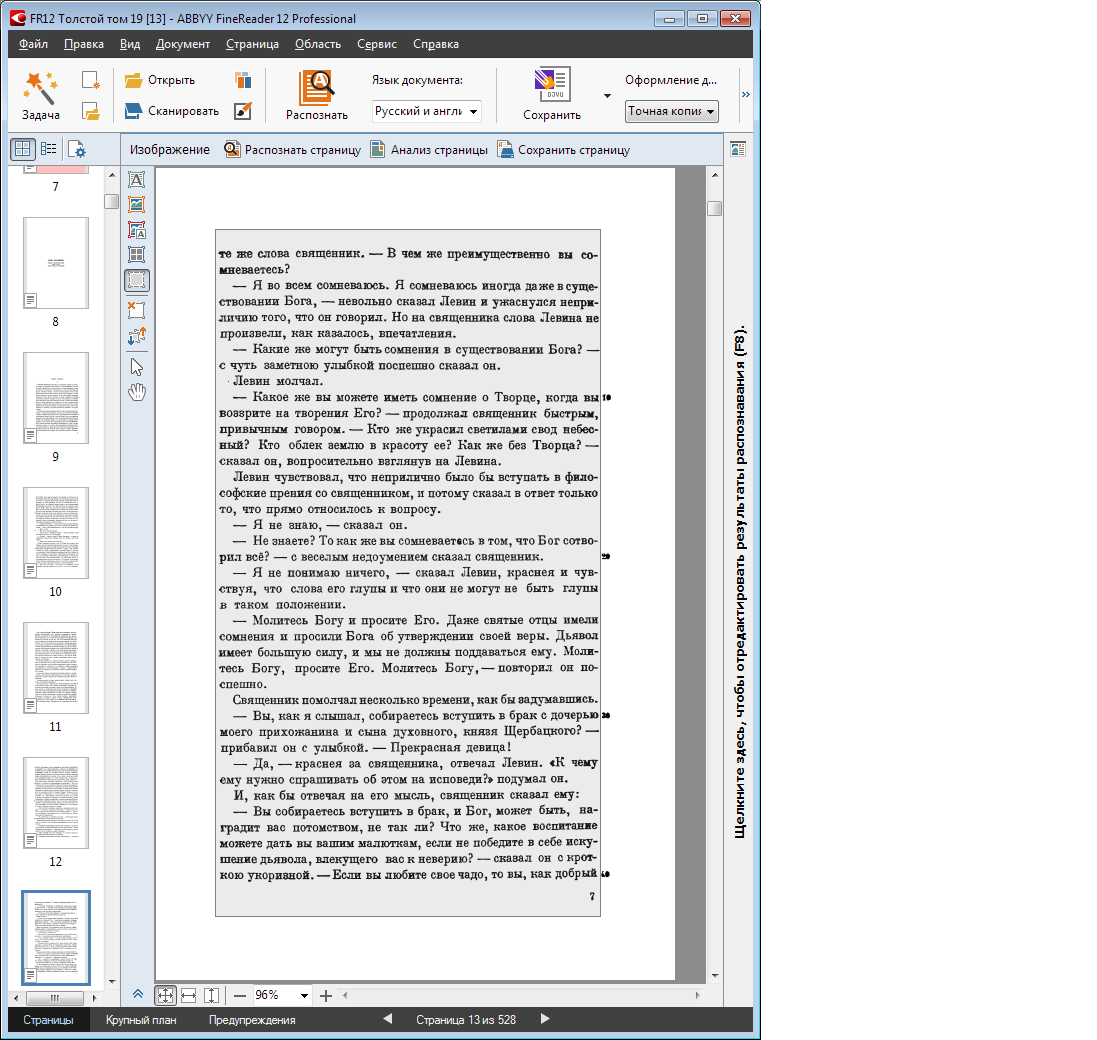
テキスト領域とは異なり、認識領域は異なる種類の領域に変わる可能性があり、これもこのプロジェクトで必要だったことを思い出してください。
- テキスト領域-1つ以上の行のテキストが含まれ、各行には論理的に接続されたテキストが含まれているため、1つのブロックで2列を選択することは非常に悪い考えです。 非長方形の形状を持つ場合があります。 自動分析による誤った分析の後、テキストの方向を「反転」に設定または修正する必要が生じることがあります(反転:明るい背景の暗いテキストは「プレーンテキスト」、暗い背景の明るいテキストは「逆」テキスト、デフォルトは「自動」で、ほとんどが修正は不要です)。
これらのパラメーターはブロックごとに設定されるため、1つのブロック内で異なる方向または異なる反転のテキストを選択することは別の悪い考えです。
ページの本文の方向についてヨーロッパ言語では、テキストの通常の向きでは、行は上から下に(テキストが論理的に上から論理的に下に変わるブロックで)読み取られますが、象形文字言語の場合、すべてがはるかに楽しいです-1ページでも一部の領域にはテキストが水平方向に含まれる場合があり、他の列は列にあり、象形文字はこれらのすべての領域で同じ向きを持っています(極東および中東の言語のトピックが興味深い場合-地元の鐘やwについての別の投稿を依頼してください)。
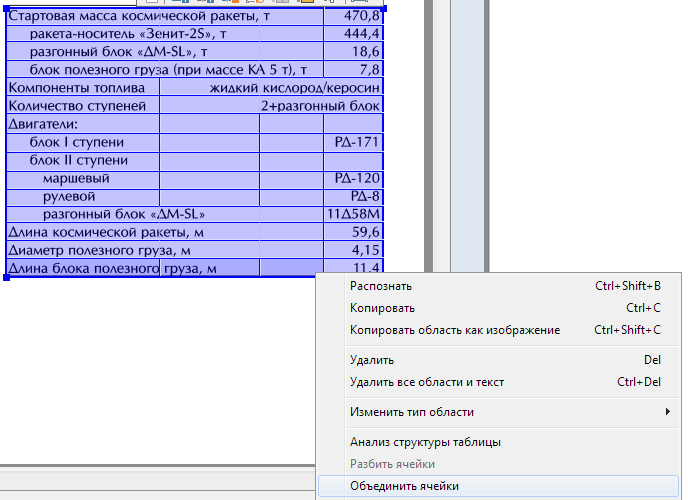 表領域 -行と列の区切りが表示され、非表示(部分的またはすべて)の表が含まれます。 テーブルの形状は長方形のみで、各セルも長方形ですが、セルグループまたは行グループの組み合わせを使用すると、非常に複雑なテキスト設定を転送できます。
表領域 -行と列の区切りが表示され、非表示(部分的またはすべて)の表が含まれます。 テーブルの形状は長方形のみで、各セルも長方形ですが、セルグループまたは行グループの組み合わせを使用すると、非常に複雑なテキスト設定を転送できます。
各セルには、認識可能なテキスト(おそらく空白)または画像を含めることができます。 セル内のテキストを認識したい場合は、特別な認識パラメーターを設定できますが、そうでない場合は「フルセル内の画像」を指定する必要があります。 ところで、テーブルセルの長方形のグループをすぐに選択して、目的のプロパティを一度に変更できます。
テーブルは、特に部分的にまたはどこでも目に見えない区切り文字を使用した自動分析のための複雑なオブジェクトです。 最初の認識または繰り返し認識の前にテーブルのレイアウトとレイアウトを手動で修正することは、認識後-FineReaderまたはターゲットアプリケーションで保存した後でも、誤ったテキスト構造を修正するよりも常に簡単であることが非常に重要です。 したがって、「ワークショップ」セクションでは、自動テーブルレイアウトのエラー修正の実例を数多く紹介します。
- 画像領域 -長方形ではない場合があります。 通常(列テキストを押しつぶす)と背景(列テキストを押しつぶさない)の2種類があり、描画時にわずかな違いがあります(たとえば、背景画像を引き伸ばしても、それで覆われているテキスト領域は削除されません)。
- バーコード領域 —自動検出可能または明示的に指定されたタイプのバーコードが含まれます。 絵のように、長方形でなくてもかまいませんが、これはほとんど必要ありません。
重要な考慮事項
- 認識と合成は、テーブルのテキスト領域またはテキストセルで強調表示されているテキストのフラグメントにのみ表示されます。 テキストがブロックで選択されていない場合、認識されません。
- 同様に、画像の場合-画像の一部が領域外にある場合、または画像全体が複数の領域に分割されている場合-おそらく、処理の結果として問題が発生します。
- FineReaderの認識言語は目盛りに設定されていません-分析から始まる多くのメカニズムに影響します:たとえば、象形文字(中国語、日本語、韓国語)またはアラビア語のテキストには、適切な言語を選択する場合にのみ考慮されない多くの機能があります認識。
近くまたは交差するエリアの相互作用の特徴
次のルールは、プログラムシェルの領域を正しく処理するため、および認識と結果の保存でそれらに何が起こるかを理解するために重要です。
- テキストブロックとテーブルブロックの相互の交差 、複数のブロックに現れる文字またはそれらの一部がある場合、ほとんどの場合エラーです 。このような分析結果は、特に複数のマウスの動きで行われるため、特に修正する必要があります。
画像領域の相互の交差は、ほとんど常に間違いですが、テキストの処理にはそれほど重要ではありません。 そのような場合も修正することが望ましい。
- 大きなテキスト領域の背景にある画像領域は、合法であり、しばしば要求される組み合わせです。 主な用途は、フラグメント(ピクトグラム、式、またはその一部など)が行内で発生する場合(FineReaderで使用されるテキストモデルでは認識されないか、まったく認識されない)いわゆるインラインイメージの処理です。


表内の画像の適切な使用例領域のプロパティパネル(下)のチェックマークを使用すると、表の左列のセルが写真で作成されます。
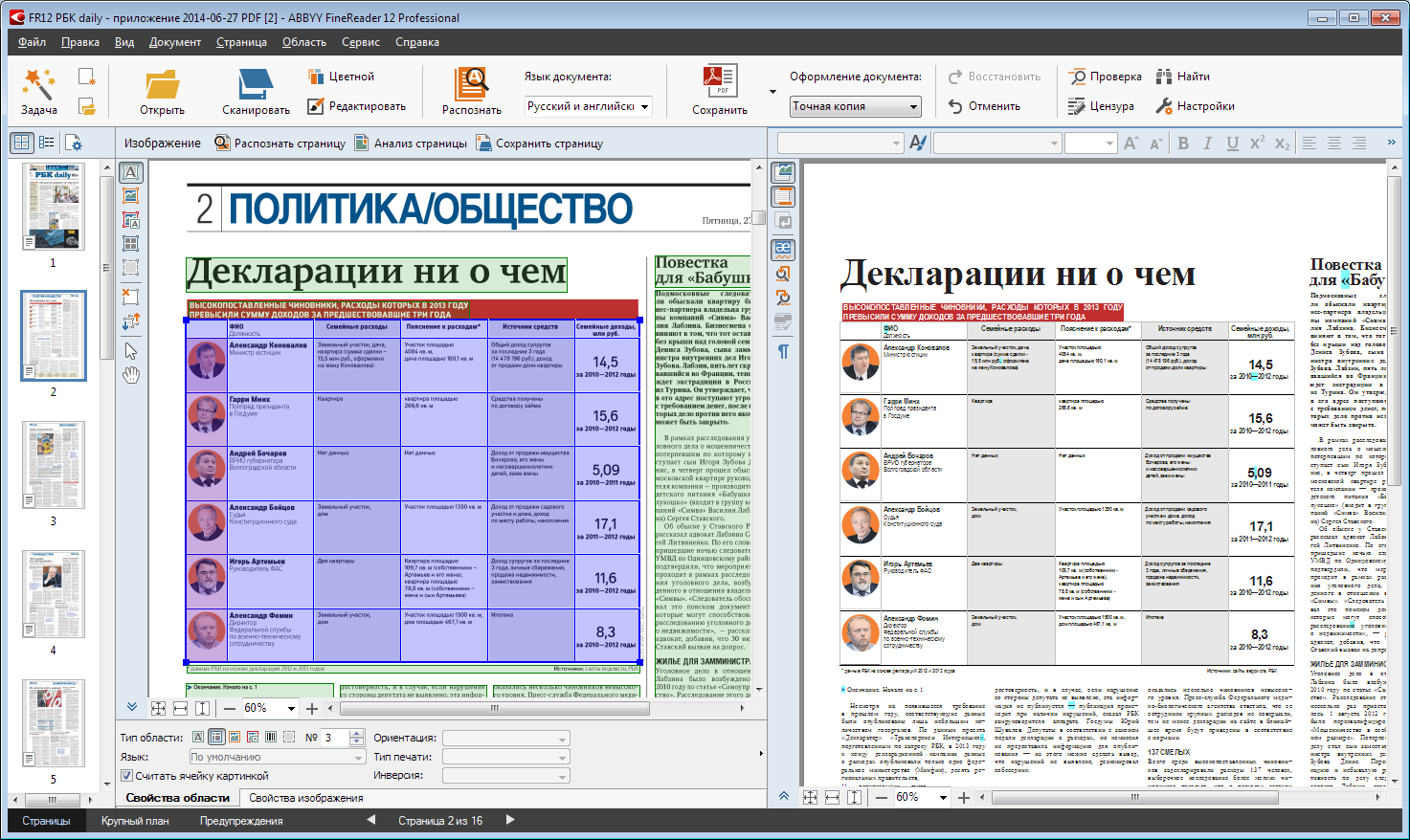
「画像」領域の背景にあるテキスト領域も重要なツールです。通常の画像領域の背景には、署名があります。「背景」画像領域には、ドキュメントのメイン(「列」)テキストとテーブルを配置できます。
写真の背景のテキスト領域の正しい使用例
ブロックの操作を簡単にするための小さなコツ
説明されている規則は、ブロックエディターの動作に反映されます。 たとえば、新しいブロックを描画したり、既存のブロックを他のブロックと完全またはほぼ完全に重複するように引き伸ばしたりすると、これらの他のブロックは自動的に削除されます。
ロジック/一貫性のない領域の割り当て
ここで考える時間です-処理の結果として受信するドキュメントの目的と形式は何ですか。 複雑な場合のブロックレイアウト修正の数と性質に影響する考慮事項を次に示します。
オプション1:テキストのみが必要です(おそらくこれを理解していないかもしれませんが、これは事実です)
元の文書のページの画像を含むPDFで文書を保存し、「非表示」の認識済みテキスト(検索およびコピー用)を追加する必要がある場合、主なことは、テキストおよび表ブロックのテキストを適切に選択することです。 「合理性」とは、次のことを意味します。
- 写真の要素やページデザイン要素がテキストまたはテーブルとして(ゴミとして)認識される「ゴミ」領域はありません。
- 領域は論理的に行を強調表示し、文字が複数の領域に入ることを防ぎ、不当に行を複数の領域に分割します。
- それは、人間の観点から、元のテーブルであり、テーブル領域で強調表示される必要があるということです。 これは、認識の品質(たとえば、異なるセルの行のベースラインが垂直に整列されない場合がある)と、出力ドキュメント内のテキストフラグメントを検索およびコピーする利便性の両方に影響します。
個々の画像を出力PDFドキュメントからコピーする必要がない場合、そのような領域はドキュメントからまったく除外できます(新しい領域を作成せず、自動的に見つかった領域を残さないでください。少なくとも論理的に見つからない画像を削除します。
文書の保存に関する記事の中で、画像の「合理性」のトピックをより広く、より深く広げたいと思っています。
オプション2:一度にすべてが必要
複数のテキストコンテンツ(1つまたは2つの列)を含むドキュメントを、電子書籍としてさらに編集および作成するために、FB2 / e-pub形式または中間の編集可能な形式(WordまたはHTML)で電子書籍として直ちに保存することになっている場合、テーブルと写真の意味のある選択が特に重要になります。
とりわけ、隣接する画像のグループをどうするか、および画像のキャプションをどうするかを決定する必要があります。両方とも並んでいて、画像と重なっています。 実際の例を使用して、「ワークショップ」でこのトピックをより詳細に分析します。
この部分の結論のようなもの
そのため、不正に割り当てられたブロックをどのように処理するかを想像します。これは、私たちのテクノロジーの観点から見ると非常に困難な場合に、本当に人生を複雑にします。
もちろん、FineReaderはすばらしいので、ユーザーは少なくともその中に何かを知らない。 したがって、別の「ワークショップ」でこのトピックに戻ります。 読者が興味を示したら、もちろん:)