この記事では、負荷の高いEMSシステムでデータベース内のテーブルのサイズが急速に増大する問題にどのように取り組んだかについて説明します。 ハイライトは、OracleとPostgreの2つのデータベースで問題が解決されたことです。 猫の下で興味を持ってください。
初期条件
そのため、ネットワーク要素からメッセージを受信して処理する特定のEMSシステムがあります。 各メッセージのレコードは、データベーステーブルに入力されます。 顧客の要件によると、着信メッセージの数(したがって、テーブル内のエントリの数)は1秒あたり平均100個ですが、ピーク負荷は最大1500まで増加する可能性があります。
1日あたり平均800万件を超えるレコードが入力されることは簡単に計算できます。 この問題は、2,000万行を超えるデータボリュームで、一部のシステム要求が遅くなり始め、顧客が要求した制限時間を超えることが明らかになったときに現れました。
挑戦する
したがって、情報が失われず、クエリが迅速に機能するように、データの処理方法を把握する必要がありました。 同時に、システムは当初Postgreで機能していましたが、近い将来、Oracleに切り替える予定であり、移行中の機能の移行に関する問題を最小限に抑えたいと考えています。
パーティショニングを使用するオプションはすぐに消えました。なぜなら、 Oracle Partitioningはライセンスに絶対に含まれないことがわかっていたため、別のパーティションに再分割したくなかったため、ある種の自転車の実装を検討し始めました。
問題を大幅に促進したのは、システムでの表示に数日より古いログが必要ないことです。 問題の大部分を調査するには、2日前に十分なメッセージがあったはずです。 ただし、「消防士の場合に備えて」それらを保存する必要があります。 その後、テーブル内のデータを定期的に「回転」させる手順を実装するというアイデアが生まれました。 それらをテーブルから転送して、いくつかの履歴テーブルに表示します。
ソリューションと実装
表示のために最も関連性の高いデータを持つ2つのテーブルを保持することにしました(それらをテーブルと呼びましょう-メインとテーブル_セカンダリ-追加)。 表示用のデータが取得されたtable_viewビューは、これら2つのテーブルに掛けられました。UIへのデータ転送の瞬間の後、すべてのレコードが急激に消えないようにするために必要です。 古いレコードは、H $ table_NUMなどの名前の履歴テーブルに転送されます。NUMは履歴テーブルの番号です(データが古いほど、数値が大きくなります)。 メインテーブルスペースを詰まらせないように、履歴テーブルも定期的に「コールド」テーブルスペースにドラッグされます。このテーブルスペースは低速ディスクに保存できます。 この操作は、一般的に言えば困難であるため、別の手順として行われることはあまりありません。 さらに、同じ手順で「コールド」テーブルスペースから古すぎるテーブルを削除します。
データの転送方法について:テーブル上のインデックスの数が多いため、挿入を使用してレコードを直接転送するのは時間がかかり、テーブルの名前を変更してインデックスとトリガーを再作成するアプローチが選択されました。
概略的に、手順の作業を図に示します。
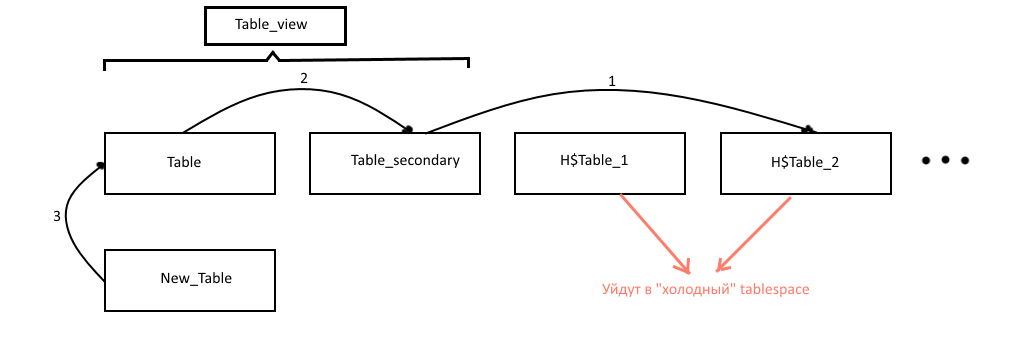
そのため、操作アルゴリズムは次のようになりました(postgreの場合はgithubを参照できますが、oracleのアルゴリズムとプロシージャコードの例を示します)。
プロシージャrotate_table(primary_table_name)。 たとえば、1時間ごとに実行します。
- メインテーブルの行数が特定の制限を超えていることを確認します。
- 「コールド」テーブルスペースがあることを確認します。
SELECT COUNT(*) INTO if_cold_ts_exists FROM USER_TABLESPACES WHERE tablespace_name = 'EMS_HISTORICAL_DATA';
- 現在のメインテーブルに基づいて、空の補助テーブルnew_tableを作成します。 このため、postgreには便利なCREATE TABLE ...(LIKE ... INCLUDING ALL)機能がありますが、Oracleには独自の類似物-create_tbl_like_include_all(primary_table_name、new_table_name、new_idx_trg_postfix、new_idx_trg_prefix)を記述する必要がありました。
SELECT replace(dbms_metadata.get_ddl('TABLE', primary_table_name), primary_table_name, new_table_name) INTO ddl_query FROM dual; ddl_query := substr(ddl_query, 1, length(ddl_query) - 1); EXECUTE IMMEDIATE ddl_query;
また、それに対するトリガーとインデックス:
FOR idx IN (SELECT idxs.index_name FROM user_indexes idxs WHERE idxs.table_name = primary_table_name) LOOP ddl_query := REPLACE( REPLACE(dbms_metadata.get_ddl('INDEX', idx.index_name), primary_table_name, new_table_name), idx.index_name, new_idx_trg_prefix || idx.index_name || new_idx_trg_postfix); ddl_query := substr(ddl_query, 1, length(ddl_query) - 1); EXECUTE IMMEDIATE ddl_query; END LOOP;
- テーブルの名前を変更します。
EXECUTE IMMEDIATE 'alter table ' || secondary_table_name || ' rename to ' || history_table_name; EXECUTE IMMEDIATE 'alter table ' || primary_table_name || ' rename to ' || secondary_table_name; EXECUTE IMMEDIATE 'alter table ' || new_table_name || ' rename to ' || primary_table_name;
- トリガーとそれらのインデックスの名前を変更します。
- コールド表領域が存在しない場合、履歴データを保存する必要はないとみなし、対応する表を削除します。
EXECUTE IMMEDIATE 'drop table ' || history_table_name || ' cascade CONSTRAINTS';
- ビューを再構築します(oracleのみ):
EXECUTE IMMEDIATE 'select * from ' || view_name || ' where 1=0';
プロシージャmove_history_logs_to_cold_ts(primary_table_name)。 たとえば、1日に1回実行されます。
- 「コールド」テーブルスペースが存在する場合、このテーブルスペースにないすべての履歴テーブルを探します。
EXECUTE IMMEDIATE 'select table_name from user_tables where table_name like ''' || history_table_pattern || ''' and (tablespace_name != ''EMS_HISTORICAL_DATA'' or tablespace_name is null)' BULK COLLECT INTO history_tables;
- 各テーブルをコールドテーブルスペースに移動します。
EXECUTE IMMEDIATE 'ALTER TABLE ' || history_tables(i) || ' MOVE TABLESPACE ems_historical_data';
- 移動したテーブルのトリガーとインデックスを削除します。
- 「コールド」テーブルスペースから古すぎるテーブルを削除します。
スケジュールされた手順は、Postgreの場合はQuartz Shedulerを使用し、Oracleの場合はOracle Schedulerを使用して開始されました。構成のスクリプトもソースにあります。
おわりに
スケジューラの設定手順とスクリプトの完全なソースコードは、 GitHubで表示できます。
ご清聴ありがとうございました!