
画像ソース
だから、もう一度あなたが達成したいものと幸福の邪魔になるものについて。
なぜ
既に実行中のモニターを実行している別の仮想マシンモニターを実行することを誰が考えますか? 実際、純粋に学術的な好奇心に加えて、これには、モニターの既存の実装によってサポートされる実用的なアプリケーションもあります[3、5]。
- ハイパーバイザーの安全な移行。
- 開始する前に仮想環境をテストします。
- ハイパーバイザーのデバッグ。
- ビルトインモニターを使用したゲストスクリプトのサポート。たとえば、Windows XP Modeを搭載したWindows 7、またはHabrに記載されているWindows Phone 8の開発スクリプト。
あるコンピューターの別のコンピューターの操作の模倣としての仮想化の理論的な可能性は、コンピューター技術の父によって示されました。 効果的であるための十分な条件、すなわち 急速な仮想化も理論的に正当化されました。 実際の実装では、特別なプロセッサモードを追加しました。 仮想マシンモニター(L0と呼びましょう)は、それらを使用して、ゲストシステムを管理するオーバーヘッドを最小限に抑えることができます。
ただし、ゲストシステム内に表示される仮想プロセッサのプロパティを見ると、実際の物理プロセッサのプロパティとは異なります。仮想化のハードウェアサポートはありません。 そして、2番目のモニター(L1と呼びましょう)を起動すると、L0がハードウェアから直接持っていたすべての機能をプログラムでシミュレートしなければならず、パフォーマンスが大幅に低下します。
ネストされた仮想化
私が説明したスクリプトは、ネストされた仮想化-ネストされた仮想化と呼ばれていました。 以下のエンティティが参加しています。
- L0は、機器で直接起動される最初のレベルのモニターです。
- L1は、L0内でゲストとして実行される組み込みモニターです。
- L2は、L1の下で実行されるゲストシステムです。
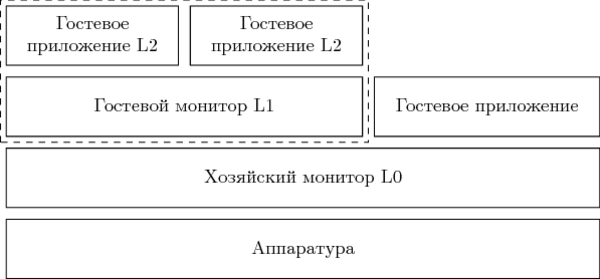
L0とL1は「官僚的な」コードであり、その実行は望ましくありませんが避けられません。 L2はペイロードです。 L2内で費やされる時間が長くなり、L1とL0での時間、およびそれらの間の遷移状態では、コンピューティングシステムはより効率的に機能します。
次の方法で効率を上げることができます。
- ルートモードと非ルートモード間の移行の遅延を減らします。 新しいIntelマイクロアーキテクチャでは、このような移行の期間はゆっくりですが確実に減少しています。
- VM出口を生成せずにより多くの操作を実行できるようにすることで、L2からの出口の数を減らします。 当然、これにより、単純な単一レベルの仮想化シナリオも高速化されます。
- 出口の数をL1からL0に減らします。 後で見るように、ネストされたモニターの操作の一部は、L0に移動せずに直接実行できます。
- L0、L1が互いに「ネゴシエート」するように指導します。 これは、ゲスト環境の変更を伴う準仮想化のアイデアにつながります。 この記事ではこのシナリオを(「スポーツマンらしくない」ように)考えませんが、そのような解決策は存在します[4]。
そのため、この機器はL2を直接サポートせず、すべての加速機能を使用してL1の動作を保証しました。 解決策は、ゲストL1とL2からフラットな構造を作成することです。

この場合、L1とL2の両方のゲストを管理するタスクはL0に割り当てられます。 後者の場合、出力がL0で正確に発生するように、ルートモードと非ルートモードの間の遷移を制御する制御構造を変更する必要があります。 これは、システムで何が起こっているかについてのL1のアイデアとはまったく一致しません。 一方、記事の次の段落で示すように、L1はモード間の遷移を直接制御できません。したがって、フラット構造が正しく実装されている場合、ゲストは誰も置換に気付かないでしょう。
シャドウ構造
いいえ、これは犯罪と陰謀理論の領域のものではありません。 アーキテクチャ状態の要素の形容詞「影」は、仮想化に関するあらゆる種類の文献やドキュメントで常に使用されています。 その考え方は次のとおりです。 ゲスト環境によって変更された通常のGPR(英語の汎用レジスタ)レジスタは、モニターの正しい動作に影響を与えることはできません。 したがって、GPRでのみ機能するすべての命令は、ゲストによって直接実行できます。 ゲストを離れた後に保持される値が何であれ、モニターは、必要に応じて、常に新しい事後値をレジスタにロードできます。 一方、CR0システムレジスタは、とりわけ、すべてのメモリアクセスの仮想アドレスがどのように表示されるかを決定します。 ゲストが任意の値を書き込むことができる場合、モニターは正常に機能しません。 このため、シャドウが作成されます。これは、メモリに保存されている操作に重要なレジスタのコピーです。 元のリソースへのゲストアクセスの試みはすべて、モニターによってインターセプトされ、シャドウコピーの値を使用してエミュレートされます。
シャドウ構造を使用した作業のソフトウェアモデリングの必要性は、ゲスト作業の生産性を失う原因の1つです。 したがって、アーキテクチャ状態の一部の要素はシャドウのハードウェアサポートを受け取ります。非ルートモードでは、そのようなレジスタへのアクセスはシャドウコピーに直ちにリダイレクトされます。
Intel VT-x [1]の場合、少なくとも次のプロセッサ構造がシャドウを取得します:CR0、CR4、CR8 / TPR(タスク優先度レジスタ)、GSBASE。
シャドウVMCS
そのため、L0のアーキテクチャ状態のシャドウ構造の実装は、純粋にソフトウェアにすることができます。 ただし、これに対する代償は、呼び出しを絶えず傍受する必要があることです。 したがって、[2]では、「非ルート」L2からL1への単一の出口は、L1からL0への約40-50の真の遷移を引き起こさないことが言及されています。 これらの遷移の大部分は、VMREADとVMWRITE [5]の2つの命令のみが原因です。
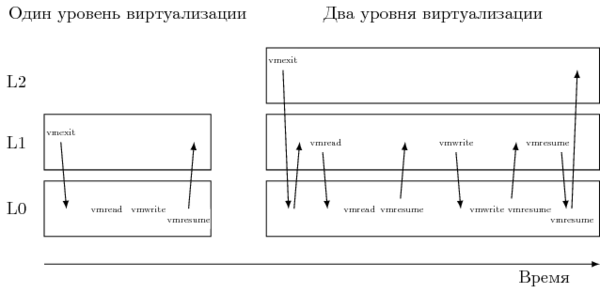
これらの手順は、仮想化モード間の移行を制御するVMCS(仮想マシン制御構造)フレームワークで機能します。 L1が直接変更することを直接許可することはできないため、L0はシャドウコピーを作成し、シャドウコピーをエミュレートして、これら2つの命令をインターセプトします。 その結果、L2からの各出口の処理時間が大幅に増加します。
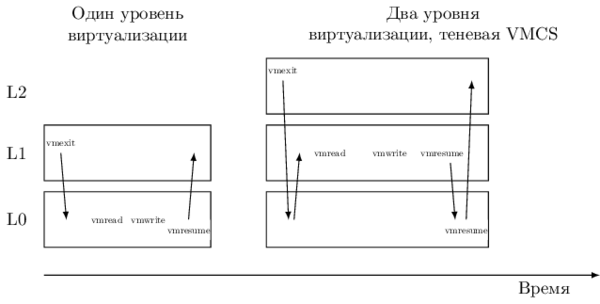
そのため、Intel VT-x VMCSの以降のバージョンでは、シャドウコピー-シャドウVMCSを取得しました。 この構造はメモリに格納され、通常のVMCSと同じ内容を持ち、 VM-exitを生成せずに非ルートモードからなど、VMREAD / VMWRITE命令を使用して読み取り/変更できます。 その結果、遷移L1→L0の大部分が削除されます。 ただし、シャドウVMCSを使用して非ルートモードとルートモードを開始/終了することはできません。L0によって管理される元のVMCSがこれに引き続き使用されます。
シャドウEPT
第1部で言及したIntel EPT(英語の拡張ページテーブル)は、アドレス変換に使用される別のシャドウ構造を操作するためのハードウェアアクセラレーション手法でもあります。 ゲスト変換テーブルのツリー全体を監視し(CR3特権レジスタの値から開始)、読み取り/変更の試行をインターセプトする代わりに、独自の「サンドボックス」を作成します。 これらの物理アドレスは、ゲストの物理アドレスの変換後に取得されますが、これも機器によって行われます。
組み込み仮想化の場合、VMCSの場合と同様に、3つの変換レベル(L2→L1、L1→L0およびL0→物理アドレス)がありますが、ハードウェアは2つしかサポートしていません。 つまり、翻訳のレベルの1つをプログラムでモデル化する必要があります。
L2→L1をシミュレートすると、予想どおり、これにより大幅な速度低下が発生します。 影響は、単一レベルの場合よりもさらに大きくなります。各例外#PF(英語のページ違反)およびL2内のCR3の書き込みは、L1ではなくL0での出力につながります。 ただし、ゲストL1環境の作成頻度がL2のプロセスよりもはるかに少ない[6]ことに気付いた場合、ブロードキャスト(L1→L0)をプログラム(つまり低速)にし、解放されたハードウェア(高速)EPTをL2→L1に使用できます。 これは、コンパイラの最適化の分野からのアイデアを思い出させます。最もネストされたコードループを最適化する必要があります。 仮想化の場合、これは最も組み込みのゲストです。
仮想化³:次は何ですか?
将来何が起こるかについて少し想像してみましょう。 さらにこのセクションには、将来の仮想化をどのように調整できるかについての私自身の(そしてそうではない)アイデアがあります。 彼らは完全に破産している可能性があり、不可能または不適切です。

そして将来、VMモニターの作成者はさらに深く掘り下げて、ネストの第3、第4、およびより深いレベルに再帰的な仮想化をもたらすことを望んでいます。 2レベルのネストをサポートするための上記の手法は、非常に魅力的ではありません。 3番目のレベルでも効果的な仮想化のために同じトリックを繰り返すことができるかどうかはよくわかりません。 問題は、ゲストモードが自分自身の再入力をサポートしていないことです。
コンピュータ技術の歴史は同様の問題を思い起こさせ、解決策を提案します。 初期のFortranは、ローカル変数(アクティベーションレコード)の状態が静的に割り当てられたメモリに保存されていたため、再帰的なプロシージャコールをサポートしていませんでした。 すでに実行中のプロシージャを呼び出すと、この領域が消去され、プロシージャの終了が切断されます。 最新のプログラミング言語で実装されたこのソリューションは、呼び出されたプロシージャのデータと戻りアドレスを格納するレコードのスタックをサポートすることで構成されていました。
VMCSについても同様の状況が見られます。この構造には絶対アドレスが使用され、その構造内のデータはL0モニターに属します。 ゲストは同じVMCSを使用できません。そうしないと、ホストの状態を失う危険があります。 スタック、または二重にリンクされた VMCS リストさえあれば、現在のモニター(およびそのすべての上位)に属する各後続エントリが、コマンドL0の下でL2を転送するための上記のトリックに頼る必要はありません。 ゲストを終了すると、前のVMCSに切り替えながらモニターに制御が移り、ゲストモードに入るとリストの次のVMCSがアクティブになります。
ネストされた仮想化のパフォーマンスを制限する2番目の機能は、同期例外の非合理的な処理です[7]。 組み込みゲストL N内で例外が発生すると、L Nに最も近いモニターL( N-1 )に状況の処理を「下げる」ことが彼の唯一のタスクであっても、制御は常にL0に転送されます。 下降には、すべての中間モニターの状態の雪崩が伴います。
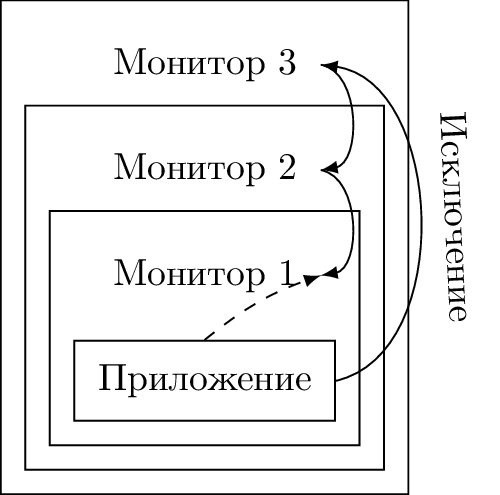
アーキテクチャの効率的な再帰仮想化には、いくつかの例外的なイベントの処理方向を変更できるメカニズムが必要です:固定順序L0→L( N-1 )の代わりに、同期割り込みをL( N-1 )→L0に向けることができます。 より多くのネストされたモニターが状況を処理できない場合にのみ、外部モニターの介入が必要です。
結論の代わりに
仮想化の最適化(および実際の一般的な最適化)のトピックは無尽蔵です-最高速度を達成するための道のりには、もう1つの最終的なフロンティアが常にあります。 私の3つのノートでは、一部のIntel VT-x拡張機能とネストされた仮想化技術についてのみ説明し、残りは完全に無視しました。 幸いなことに、オープンで商用の仮想化ソリューションに取り組んでいる研究者は、彼らの仕事の結果を公開することをいとわない。 KVMプロジェクトの年次会議の資料とVmwareのホワイトペーパーは、最新の成果に関する優れた情報源です。 たとえば、デバイスからの非同期割り込みによって引き起こされるVM出口の数を減らす問題は、[8]で詳細に説明されています。
ご清聴ありがとうございました!
文学
- Intel Corporation。 Intel 64およびIA-32アーキテクチャソフトウェア開発者マニュアル。 ボリューム1〜3、2014。www.intel.com / content / www / us / en / processors / architectures-software-developer-manuals.html
- Orit Wasserman、Red Hat。 ネストされた仮想化:シャコガメ。 // KVMフォーラム2013-www.linux-kvm.org/wiki/images/e/e9/Kvm-forum-2013-nested-virtualization-shadow-turtles.pdf
- カシヤプチ。 Intelのネストされた仮想化(VMX) raw.githubusercontent.com/kashyapc/nvmx-haswell/master/SETUP-nVMX.rst
- ムリ・ベン・イェフダ等。 Turtlesプロジェクト:ネストされた仮想化の設計と実装//第9回オペレーティングシステムの設計と実装に関するUSENIXシンポジウム、2010年。www.usenix.org/ event / osdi10 / tech / full_papers / Ben-Yehuda.pdf }
- Intel Corporation。 Intel VMCS Shadowingを搭載した第4世代Intel Core vProプロセッサー。 www-ssl.intel.com/content/www/us/en/it-management/intel-it-best-practices/intel-vmcs-shadowing-paper.html
- グレブ・ナタポフ。 ネストされたVMXを高速化するネストされたEPT // KVMフォーラム2013-www.linux-kvm.org/wiki/images/8/8c/Kvm-forum-2013-nested-ept.pdf
- ウイングチープーン、アロイシウス・K・モク。 x86アーキテクチャの再帰的仮想化におけるVMExitフォワーディングの遅延の改善// 2012第45回ハワイシステムサイエンス国際会議
- ムリ・ベン・イェフダ。 x86仮想化のベアメタルパフォーマンス。 www.mulix.org/lectures/bare-metal-perf/bare-metal-intel.pdf