そして、「彼らはストーブから踊りだす」ので、私たちは最初から状況を見ていきます-仮想バックアップの根底にある原則で、少し内向きに掘り下げ、仮想環境の管理者の約90%が考慮していないという1つの明らかな問題を明らかにします。 また、説明を簡素化するために、最も透過的で文書化されているVMwareハイパーバイザーの機能に基づいて、すべての機能の説明を行うことに注意してください。
主なアイデアは、本番システムが配置されているストレージシステムの負荷を軽減することです。これは、制御されていないアクティビティがI / O操作のレイテンシを大幅に増加させ、不快な結果を引き起こすことが多いためです。
•ゲストOS内のアプリケーションパフォーマンスが非常に低いレベルに低下し、さらに低くなります
•DAG、SQL on alwaysなどのクラスター構造の崩壊。
•ゲストOSは単にシステムドライブを失う可能性があります
また、ストレージレベルでのパフォーマンスの低下に関連する、一見したところ、他にも多くの驚くべきものがあります。
どうやってこれに到達したのか
バックアップがスナップショットに基づいていることは秘密ではありません。 このアルファとオメガにより、仮想マシンのディスク上のファイル構造の一貫性とバックアップ期間中のディスク自体のファイルの保護という2つの非常に重要な目標を達成できます。
ディスク操作を正常に停止し、スナップショットを作成したら、VMディスクの保存に直接進むことができます。 これはさまざまな方法で実行できます。
•LANスタックを介してホストに直接アクセスすることにより、ファイルを取得できます。 この方法は常に機能しますが、常に非常に低速です(バックアップインフラストラクチャ全体が10Gリンクで構築されている場合を除く)。
•より収益性の高いオプションは、ディスクを一時的に別のマシンに接続し、そこからダウンロードする機能です。 この場合、データはI / Oスタックを介してストレージから直接取得されます。 この場合のコピー速度は、他のすべての条件が同じであれば、少なくとも1桁は向上します。
•また、最速かつ最も高価なオプションは、必要なすべてのメタデータをハイパーバイザーから受け取って、SANから直接ファイルを取得することです。 この場合、コピー速度は2桁、3桁高速にできます。 すべては、SANとバックアップストレージの場所との間の接続に依存します。
ただし、使用するオプションに関係なく、ディスクのコピーが完了したら、逆の操作を実行します。バックアップ中に仮想マシンで発生し、スナップショットに蓄積されたすべての変更は、元のディスクに統合する必要があります。その後、スナップショットを安全に削除できます。 VMは、何も起こらなかったかのように機能し続けます。
そして、ここで2つの非常に重要なニュアンスが出てきますが、それらが現れるまで注意を払う人はほとんどいません。
スナップショットの統合は、ホストストレージシステムの負荷の観点から非常に困難な手順であり、ストレージの速度(パフォーマンス)に直接依存します。 今がその時です。 2つ目-この操作は、ハイパーバイザーレベルで最高の優先度を持ちます。 情報の完全性ほど重要なものはありません。それに反論することは困難です。
2番目に1番目を追加すると、スナップショットの統合中にハートビートリクエストがクラスターVMに到着した場合、このリクエストへの応答に許容できない時間がかかると考えられる場合、ハイパーバイザーはその送信を(一時バッファーに配置することで)簡単に遅らせることができます統合操作に不一致が生じる可能性があります。
この時点で、3つの意見があります。
•ゲストOSの観点から、彼女は順調です。 それは動作しますが、ハイパーバイザーが少しフリーズするという事実は、そのレベルで常に目立つとは限りません。 ただし、例外があることに注意してください。記事の冒頭で説明したように、OSはディスクとの接触を失う可能性があります。 すべての結果を持つシステムを含む。
•ハイパーバイザーの観点からは、すべてが問題ありません。 彼は慎重にスナップショットを削除し、VMに入力されるリクエストは、自分の裁量で、バッファまたはいわゆるヘルパースナップショットに入れて、後でこのデータをVMに送信できるようにします。 データの整合性が確保され、誰もが踊っています。
•しかし、現時点ではクラスター上でパニックが発生しています。 クラスターメンバー(または複数の参加者)が既にいくつかの投票を逃しており、クォーラムの再カウントを開始するとき、またはクラスターが生きているよりも死んでいる可能性が高いことを報告するときです。 いずれにせよ、状況は非常に不快です。
誰かがクラスターをテストしたい場合は、スナップショットを作成して、10にカウントしてすぐに削除しないように警告します。 スナップショットは存続し、
お母さん、それは私のせいじゃない
旧石器時代後期のストレージシステムにあるメールボックスサーバーの3日間のバックアップの後、DAGが再び崩壊した一部のクライアントは、明らかな接続を参照して、すべての致命的な罪を私たちに責めるのが大好きです-バックアップ中にクラスターが崩壊しました。つまり、バックアップソフトウェアのせいです しかし、残念ながら、この記事で説明されているすべての事実はVMware自身によって確認されています。 KBで投稿された記事では、白黒で書かれています-スナップショットの統合中に、ロードされたVMが外部からの応答を停止する場合があります。 これの典型的な結果は、失われたシステムドライブを報告するBSODです。 VMがクラスターの一部だった場合、クラスターから除外され、クラスターが分割されるか、最良の場合はパフォーマンスが非常に大幅に低下します(ただし、RAMを増やすことで比較的うまく対処できます)。 また、ベストプラクティスでは、スナップショットを2日間以上保存することはお勧めしません。
また、 HF記事でこのトピックに関する情報の選択も収集しました。
これと戦うことにした方法
明らかに、このプロセスのボトルネックはストレージの内部速度です。 朝は素晴らしいドライブがあり、夕方までにストアの負荷を減らすために本番をオフにする必要がありました。今月は数百ギガバイトに成長したスナップショットを削除できることを期待して(VMパフォーマンスが低下しました)重要なポイントまで)。
最初に、正面攻撃オプションがテストされました-ストレージシステムでの操作の数を直接制限するパラメーターが導入されました。 しかし、この方法には静的システムに固有の欠点が多すぎます。 VMが配置されているのと同じストレージシステムにバックアップを保存するのが好きな若いパイオニアは、バックアップをさらに遅くするすべての可能な方法を特定し、ホストをパニックにすることができます。
そのため、新しいバージョンでは、このようなモデルを完全に放棄し、現在のI / Oレイテンシインジケーターの動的処理に切り替えることが決定されました。 グローバルアプリケーション設定レベルでは、次のようになります。
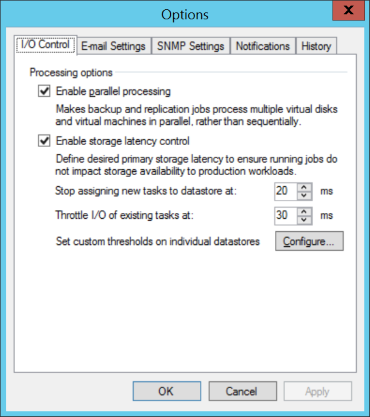
また、Hyper-Vを使用する場合は、グローバル設定に加えて、特定のデータストレージまたはボリュームごとに独自のパラメーターを設定できることに注意してください。 しかし、これはライセンスの問題です。
したがって、提案されている同じパラメータの束を検討してください。
「次の時点でデータストアへの新しいタスクの割り当てを停止します。 」バックアップ中にレイテンシ(IOPSレイテンシ)が許容しきい値を超えた場合、VBRサーバーはストレージパフォーマンスが許容レベルに戻るまで新しいファイル転送ストリームを作成しません。 または、簡単に言えば、ストレージに大きな負荷がかかっている場合、ストレージからすべてのジュースを絞り出そうとはしません。
「 既存タスクのI / Oのスロットル: 」-バックアップタスクが既に実行されている場合に使用され、外部負荷によりディスクへのアクセスに遅延が発生します。 たとえば、バックアップ中にマシンの1つでSQLサーバーが起動され、同じストレージシステムに追加の負荷がかかる場合、VBRサーバーは実稼働システムに干渉しないように、独自のディスクアクセスレートを人為的に減らします。 パフォーマンスが以前のレベルに戻ると、VBRサーバーはデータ転送速度も自動的に増加します。 この段落は、前の段落を補足します。 最初の手段として、一定の安定したレベルで作業している間に追加の負荷の作成を単に停止する場合、2番目の手段は、運用システムを優先して進行中の操作の強度を下げることです。
これらのパラメーターがどのように機能するかの例は、このスクリーンショットに完全に表示されています。
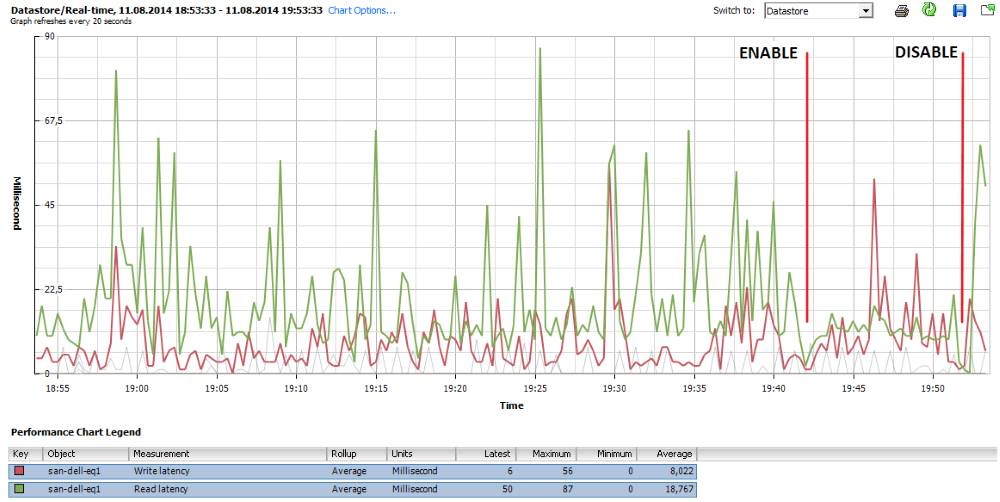
グラフの最初の段階では、ストレージは「休止」状態にあります。 通常の作業手順が発生します。 18:55にバックアップタスクが含まれ、これにより、顕著なピークが80ミリ秒に達すると予想される読み取り/書き込み操作の遅延が増加しました。 19:42頃、制御メカニズムがアクティブになり(マークを有効化)、読み取り可能な遅延の平均値(緑色のグラフ)は20ミリ秒に保たれ、制御メカニズムがオフになったときにのみ増加します(マークを無効化)。
デフォルトの20および30ミリ秒のしきい値は天井から取られたのではなく、提供してくれた多くのお客様からのモニタリングデータを評価した結果です。 したがって、これらの値はほとんどの仮想環境に最適です。
おわりに
おそらく、ここでこの機能の説明を終了します。 できるだけアクセスしやすいようにしましたが、まだ質問がある場合は、コメントまたはPMを続けていただければうれしいです。
当社の他の製品またはそれらの個々の機能に関する質問をお気軽に。 全員に答えようとしますが、簡単に解決しない場合は、別の記事を作成します。