2番目のレッスンでは、タスクキューを使用して、リソースを大量に消費するタスクを複数のサブスクライバーに分散する方法を検討しました。
しかし、リモートマシンで関数を実行して結果を待つ場合はどうでしょうか。 それはまったく別の話です。 このパターンは、一般にリモートプロシージャコール(RPC、以降RPCと呼びます)として知られています。
このガイドでは、RabbitMQを使用して、クライアントとスケーラブルなRPCサーバーを含むRPCシステムを構築します。 配布を必要とする実際の時間のかかるタスクがないため、フィボナッチ数を返す単純なRPCサーバーを作成します。
顧客インターフェース
RPCサービスの使用を説明するために、単純なクライアントクラスを作成します。 このクラスには、RPC要求を送信し、応答を受信するまでブロックする呼び出しメソッドが含まれます。
fibonacci_rpc = FibonacciRpcClient() result = fibonacci_rpc.call(4) print "fib(4) is %r" % (result,)
RPCノート
RPCはかなり一般的なパターンですが、多くの場合批判されます。 開発者が使用している機能(RPCを介して実行されるローカルまたは低速)を正確に知らない場合、通常問題が発生します。 このような混乱は、予測できないシステム動作を引き起こす可能性があり、デバッグプロセスに不必要な複雑さをもたらします。 したがって、ソフトウェアを単純化する代わりに、RPCを不適切に使用すると、コードが無人で読み取り不能になる可能性があります。
上記に基づいて、次の推奨事項を作成できます。
- それぞれの場合にどの関数が呼び出されるかが明らかであることを確認してください:ローカルまたはリモート。
- システムを文書化します。 コンポーネント間の依存関係を明示的にします。
- バグを処理します。 RPCサーバーが長時間応答しない場合、クライアントはどのように応答する必要がありますか?
- 疑わしい場合は、RPCを使用しないでください。 可能であれば、結果が次の処理レベルに非同期で渡される場合、ブロッキングRPCではなく非同期パイプラインを使用します。
結果キュー
一般に、RabbitMQを使用してRPCを実行するのは簡単です。 クライアントがリクエストを送信し、サーバーがリクエストに応答します。 応答を受信するには、クライアントはキューを渡して、リクエストとともに結果を送信する必要があります。 コードでどのように見えるか見てみましょう:
result = channel.queue_declare(exclusive=True) callback_queue = result.method.queue channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to = callback_queue, ), body=request) # ...- callback_queue ...
メッセージのプロパティ
AMQPには14の事前定義されたメッセージプロパティがあります。 それらのほとんどは、次の例外を除いて、非常にまれにしか使用されません。
- delivery_mode :メッセージを「永続的」(値2)または「一時的」(その他の値)としてマークします。 2番目のレッスンでこのプロパティを覚えておく必要があります。
- content_type :データ表示形式(MIME)を記述するために使用されます。 たとえば、頻繁に使用されるJSON形式の場合、このプロパティをapplication / jsonに設定することをお勧めします。
- reply_to :通常、結果キューを示すために使用されます。
- correlation_id :プロパティは、RPC応答を要求にマップするために使用されます。
相関ID
上記の方法では、RPC要求ごとに応答キューを作成することを提案しました。 これは多少冗長ですが、幸いなことに、より良い方法があります-各クライアントに共通の結果キューを作成しましょう。
このキューから回答を受け取ったため、新しい質問が発生します。この回答がどのリクエストに対応するのかは明確ではありません。 ここで、 correlation_idプロパティが役立ちます。 リクエストごとにこのプロパティに一意の値を割り当てます。 後で、このプロパティの値に基づいて、受信した応答を応答キューから抽出すると、要求と応答を明確に一致させることができます。 correlation_idプロパティで不明な値が見つかった場合、このメッセージはリクエストに対応していないため、安全に無視できます。
スクリプトを中断するのではなく、応答キューからの不明なメッセージを単純に無視することを計画しているのはなぜだろうと思われるかもしれません。 これは、サーバー側で競合状態が発生する可能性があるためです。 これはほとんどありませんが、RPCサーバーが応答を送信し、要求処理の確認を送信する時間がないシナリオが可能です。 これが発生した場合、再起動されたRPCサーバーがこの要求を再び処理します。 これが、クライアントで繰り返し応答を正しく処理する必要がある理由です。 さらに、理想的には、RPCはべき等でなければなりません。
まとめ
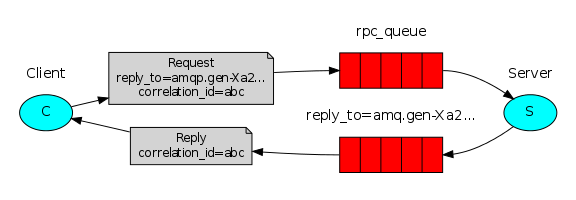
RPCは次のように機能します。
-クライアントが起動すると、結果の匿名の一意のキューを作成します。
-RPCリクエストを作成するために、クライアントは2つのプロパティを持つメッセージを送信します: reply_to 、値は結果キューで、 correlation_id 、各リクエストに一意の値が設定されます。
-要求はrpc_queueキューに送信されます 。
-サーバーはこのキューからのリクエストを待っています。 要求が受信されると、サーバーはタスクを実行し、 reply_toプロパティのキューを使用して、結果を含むメッセージをクライアントに送信します。
-クライアントは結果キューから結果を期待します。 メッセージを受信すると、クライアントはcorrelation_idプロパティをチェックします。 要求の値と一致する場合、結果はアプリケーションに送信されます。
すべてをまとめる
Rpc_server.pyサーバーコード:
#!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2) def on_request(ch, method, props, body): n = int(body) print " [.] fib(%s)" % (n,) response = fib(n) ch.basic_publish(exchange='', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id = \ props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request, queue='rpc_queue') print " [x] Awaiting RPC requests" channel.start_consuming()
サーバーコードは非常に簡単です。
- (4)通常どおり、接続を確立してキューを宣言します。
- (11)整数の正数のみを引数としてとるフィボナッチ数を返す関数を宣言します(この関数は大きな数で動作する可能性は低く、これはおそらく最も遅い実装です)。
- (19)RPCサーバーのコアであるbasic_consumeに対してon_requestコールバック関数を宣言します。 要求が受信されると実行されます。 作業が完了すると、関数は結果を送り返します。
- (32)おそらく、いつか複数のサーバーを起動したいと思うでしょう。 負荷を複数のサーバーに均等に分散させるために、 prefetch_countを設定します 。
クライアントコードrpc_client.py:
#!/usr/bin/env python import pika import uuid class FibonacciRpcClient(object): def __init__(self): self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue) def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to = self.callback_queue, correlation_id = self.corr_id, ), body=str(n)) while self.response is None: self.connection.process_data_events() return int(self.response) fibonacci_rpc = FibonacciRpcClient() print " [x] Requesting fib(30)" response = fibonacci_rpc.call(30) print " [.] Got %r" % (response,)
クライアントコードはもう少し複雑です。
- (7)接続、チャネルを確立し、受信した応答の結果の一意のキューをアナウンスします。
- (16)RPCからの応答を受信するために、結果キューにサブスクライブします。
- (18)各応答の受信時に実行されるコールバック関数 ' on_response 'は、かなり些細なタスクを実行します-受信した応答ごとに、 correlation_idが期待したものと一致するかどうかをチェックします。 その場合、応答をself.responseに保存し、ループを中断します。
- (23)次に、実際にRPC要求を実行する呼び出しメソッドを定義します。
- (24)このメソッドでは、最初に一意のcorrelation_idを生成して保存します。on_responseコールバック関数はこの値を使用して目的の応答を追跡します。
- (25)次に、 reply_toプロパティとcorrelation_idプロパティを含むリクエストをキューに入れます。
- (32)次に、応答を待機するプロセスが開始されます。
- (33)そして、最後に、結果をユーザーに返します。
RPCサービスの準備ができました。 サーバーを起動できます。
$ python rpc_server.py [x] Awaiting RPC requests
フィボナッチ数を取得するには、クライアントを実行します。
$ python rpc_client.py [x] Requesting fib(30)
提示されたRPC実装オプションは、唯一可能な選択肢ではありませんが、次の利点があります。
- RPCサーバーが遅すぎる場合は、別のサーバーを簡単に追加できます。 新しいコンソールで2番目のrpc_server.pyを実行してみてください。
- クライアント側では、RPCは1つのメッセージのみを送受信する必要があります。 queue_declareの同期呼び出しは不要です 。 その結果、RPCクライアントは1つのRPC要求に対して1つの要求と応答のサイクルを管理します。
ただし、コードは単純化されており、次のようなより複雑な(もちろん、重要な)問題を解決しようとさえしていません。
- サーバーが実行されていない場合、クライアントはどのように応答する必要がありますか?
- クライアントにRPCのタイムアウトを設定する必要がありますか?
- ある時点でサーバーが「ブレーク」して例外をスローした場合、クライアントに渡す必要がありますか?
- 処理前の無効な着信メッセージ(たとえば、許容可能な境界のチェック)に対する保護。
すべての管理記事
RabbitMQチュートリアル1-Hello World (Python)
RabbitMQチュートリアル2-タスクキュー (Python)
RabbitMQチュートリアル3-発行/購読 (php)
RabbitMQチュートリアル4-ルーティング (php)
RabbitMQチュートリアル5-テーマ (php)
RabbitMQチュートリアル6-リモートプロシージャコール(この記事、Python)