しかし、違います。 鈍いグラフィックスを正気に見せ、同時にブレーキなしで動作させるには、汗をかかなければなりませんでした。ほとんどすべての段階で、予想外の困難が待ち受けていました。
目的:図を作成するためのクロスプラットフォームライブラリを開発します。これは対話型で、すぐに使用できるアニメーション化されたトランジションをサポートし、最も重要なこととして、速度を落とすことはありませんでした。
問題1:floatとピクセルの一致
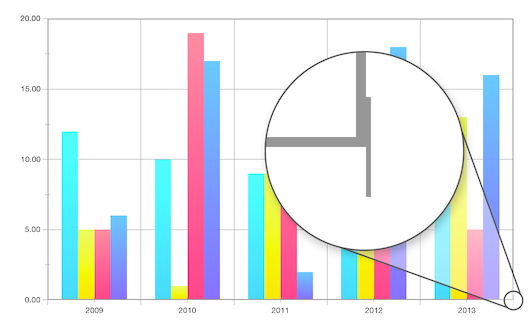
一年生でもセグメントをn個の等しい部分に分割できるように思われます。 私たちの問題は何ですか? 数学的には、ここではすべてが真実です。 人生はフロートの精度を損ないます。 同等ではあるが異なる変換の影響を受ける場合、2行のピクセルをピクセルに結合することは実際には不可能です。GPUの腸では、ラスタ化プロセス中に毎回異なる方法でエラーが発生します。 そして、右の左のピクセルは、輪郭、軸上のマークなどに関して非常に顕著です。 エラーの存在を予測したり、エラーが発生したラスタライズのメカニズムに影響を与えたりすることができないため、デバッグすることはほとんど不可能です。 この場合、 シザーテストが有効になっているかどうかに応じてエラーが異なることがわかります(チャートのプロット領域を制限するために使用します)。
松葉杖を作らなければなりません。 たとえば、変換変換のオフセットを10 -4に丸めます。 この番号はどこから来たのですか? 拾った! コードは恐ろしく見えますが、動作します:
const float m[16] = { 1.0f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, (float)(ceil(tx() * 10000.0f) / 10000.0), (float)(ceil(ty() * 10000.0f) / 10000.0), (float)(ceil(tz() * 10000.0f) / 10000.0), 1.0f };
その結果、実際に発生するほとんどの場合、エラーを補正するために必要な値を選択しました。 重要なものを見逃さないことが望まれます。
問題2:垂直線のドッキング
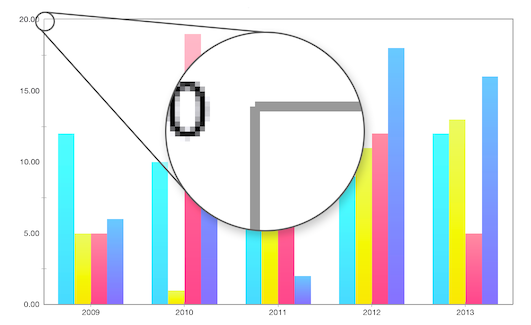
ここでのポイントはエラーではなく、「ハードウェアアクセラレーション」ラインの実装方法です。 厚さは2ピクセルで、座標は同じで、交差点は中央にあります。 そして-結果として、壮大な「噛まれた」コーナー。 解決策は、端の1つのX座標またはY座標を1ピクセルずらします。 しかし、ポリゴンの座標を操作しながら何かをピクセル単位でシフトすることは、全体的な問題です。 シーンの座標とスクリーンの座標は、エラーによって透過される変換によって互いに接続されます-特に投影マトリックスによって記述されるスコープのサイズがスクリーンのサイズと等しくない場合。
最終的に、許容可能な結果をもたらすバイアスを選択しましたが、「しかし、堆積物は残っていました」。解決策はまだ信頼性が低く、ユーザーの角が欠ける可能性が常にあります。 次のようになります。
m_border->setFrame(NRect(rect.origin.x + 0.5f, rect.origin.y + 0.5f, rect.size.width - 3.5f, rect.size.height - 3.0f)); m_xAxisLine->setFrame(NRect(rect.origin.x, rect.origin.y, rect.size.width - 1.5f, rect.size.height - 1.0f)); m_yAxisLine->setFrame(NRect(rect.origin.x, rect.origin.y, rect.size.width - 1.5f, rect.size.height - 0.5f));
問題3:一般的な行
そして再び線。 どのチャートにもかなりの数の線があります-通常の線、フリルはありません。 これは、軸、グリッド、軸の分割、グラフ要素の境界、場合によってはグラフ自体です。 そして、これらの線はどういうわけか描かなければなりません。 それは簡単だと思われますか? 逆説的に思えるかもしれませんが、現代のグラフィカルAPIほど、通常の行のサポートをより自信を持って捨てています。OpenGLの証明、Direct3Dの証明です 。
これまで、ラインは引き続きサポートされていますが、許容される太さは厳しく制限されています。 実践では、iOSデバイスでは8ピクセルであり、一部のAndroidではさらに小さいことが示されています。 OpenGL仕様では、点線パターンのインストール機能( glLineStipple )はサポートされなくなりました。OpenGLES2.0のモバイルデバイスでは使用できません。 線自体は-許容できる太さの境界に収まるものでさえ-恐ろしく見えます:
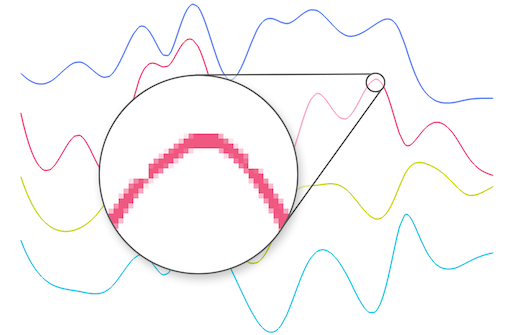
私たちが持っているものに我慢しながら、すべてがあなた自身のラインビジュアライザーを書くところまで行き、それは輪郭のスケールに関係なくスクリーン上で一定の太さを維持します(GL_LINESのように) 。 おそらく、このためには、ポリゴンからそれらを構築する必要があります:

問題4:ポリゴン間の穴

そして再び、精度の問題。 スクリーンショットは、円グラフに明るい「しみ」を示しています。 これは、ラスター化エラーの結果にすぎません(もう一度!)、そして松葉杖は保存できません。 ボーダースムージングを有効にすると、少し良くなります。

現時点では、彼らは和解し、この形で去りました。
問題5:システムのアンチエイリアスの機能
境界線のスムージングがまったくないため、網膜ディスプレイでもレンダリング結果が目を痛めます。 しかし、最新のプラットフォームで利用可能なMSAAシステムスムージングアルゴリズムには、3つの重大な問題があります。
- パフォーマンスの低下:観測によると、携帯電話では平均3倍低下し、複雑なシーンでアニメーションを再生すると、目に見えるラグが発生します。
- マルチプラットフォームの難しさ(そして追いかけている):異なるプラットフォームでは、システムのアンチエイリアスはさまざまな方法でオンになりますが、コードを最大限に統一しようとしています。
- 画像のアーチファクト:側面が画面の側面に平行なオブジェクト(たとえば、グラフのグリッド線)は、システムのアンチエイリアシング(すべての変換の結果、分数座標を持つことが判明した場合)によってぼやけますが、シャープのままである必要があります:
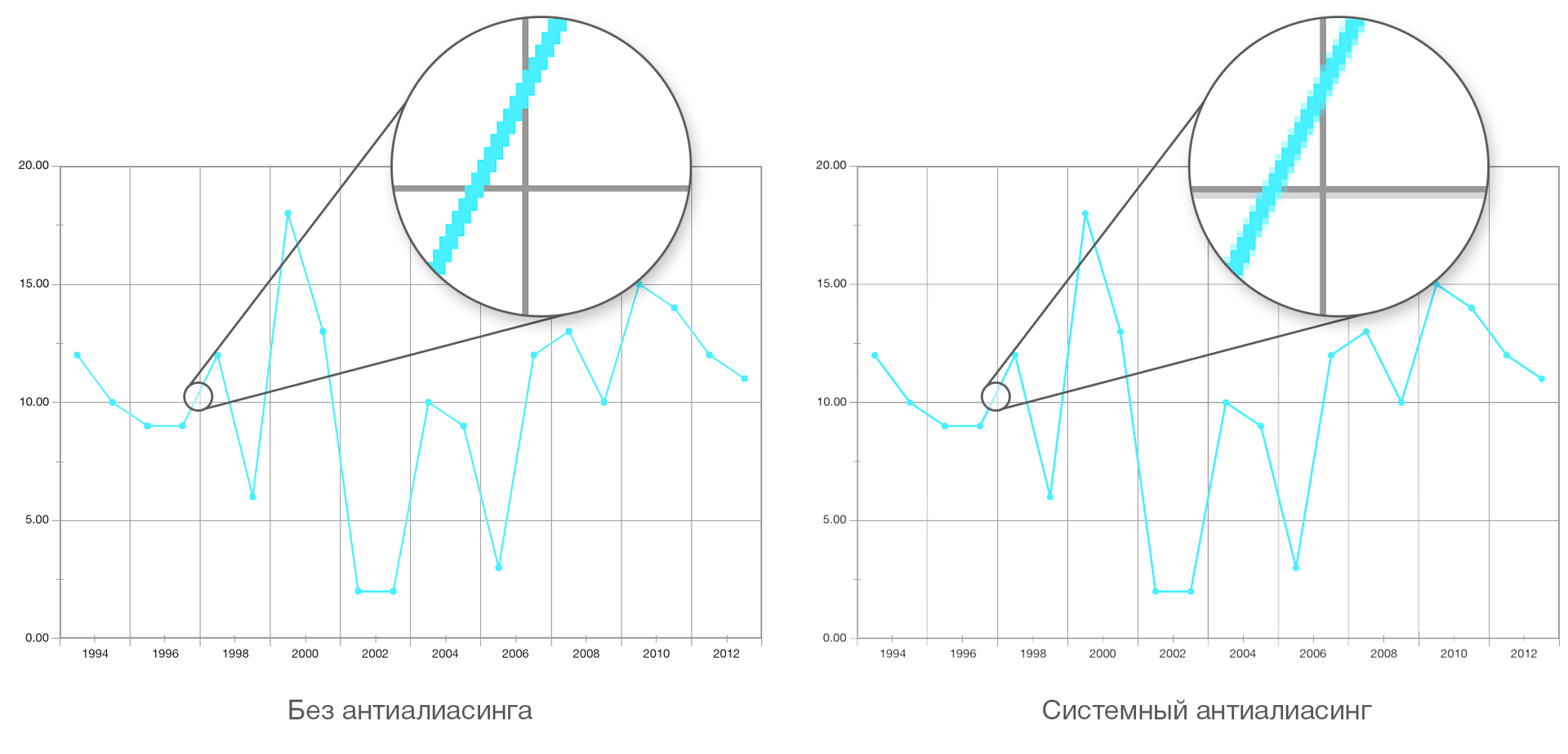
このため、標準のスムージングを放棄し、独自のアルゴリズム
- アニメーションの再生中は自動的にオフにできます(アニメーション中、ユーザーは滑らかな動きが必要で、静的な場合はエッジが滑らかです)。
- スムージングパフォーマンスの点では、システムのアンチエイリアスと一致しますが、グラフィックエンジンの内部メカニズムによってのみ実装されます(つまり、マルチプラットフォームを維持します)。
- 全体ではなく、シーンの一部に影響を与える可能性があります(これによりアーティファクトのぼやけが回避されます。スムージングされたオブジェクトのセットから明らかに恩恵を受けないものを単に除外します)。
シーンの一部への影響は、オブジェクトのセット全体が相互の配置(前面、中央、背景など)およびスムージングの必要性に従ってグループ(レイヤー)に分割される場合、「レイヤーバイレイヤー」レンダリングによって編成されます。 レイヤーは順番に描画され、アンチエイリアスは対応する属性が設定されているレイヤーにのみ適用されます。

問題6:マルチスレッドと省電力
ユーザーインターフェースイベントを処理し、グラフィックシーンを異なるスレッドでレンダリングすることをお勧めします。 ただし、ユーザーアクションはシーンの外観に影響するため、同期が必要です。 すべてのビジュアルオブジェクトにミューテックスを配置するのは多すぎると判断し、代わりにトランザクションメモリを実装しました。
アイデアは、プロパティの2つのハッシュテーブルがあることです。メインスレッド(メインスレッドテーブル、MTT)とレンダーストリーム(レンダースレッドテーブル、RTT)用です。 オブジェクトの外観の設定に対するすべての変更は、MTTに分類されます。 その中の別のレコードを押すと、「同期ティック」の計画につながります(まだ計画されていない場合)。これは、メインスレッドの次の反復の開始時に発生します(ユーザーインターフェイスはメインスレッドで処理されると想定されます)。 同期チェック中に、MTTのコンテンツはRTTに移動されます(このアクションは、グラフィックシーン全体で唯一のミューテックスによって保護されています)。 レンダリングストリームの各反復の開始時に、RTTにエントリがあるかどうかを確認し、エントリがある場合は、対応するオブジェクトに適用されます。
また、特定のプロパティのインストールとアニメーションを実装します。 たとえば、一定時間に0から1へのスケール変更を指定できます。RTTからの記録はすぐには適用されませんが、いくつかのステップで適用されます。各ステップでは、特定の法則に従ってスケール値を0から1に補間した結果になります
また、同じメカニズムにより、オンデマンドでレンダリングする機能が提供されます。実際のレンダリングは、RTTにレコードがある場合(つまり、シーンの状態が変更された場合)にのみ実行されます。 オンデマンドの視覚化は、プロセッサをオフロードし、それにより貴重なバッテリー電力を節約するため、モバイルデバイスに非常に関連しています。
そのようなもの。 もちろん、Googleを使用する機能についても十分なタスクがありましたが、最も予想外のレーキがリストされていました。 その結果、主催者の努力にもかかわらず、