
このような分析は、数学統計とYandexサービスの使用に関するデータの調査に基づいています。 行動特性は、ユーザーを一意に識別し、それによってパスワードの使用を置き換えるのに十分ではありませんが、これにより、許可後にハッキングを判別できます。 したがって、メールから盗まれたパスワードは、実際の所有者のふりをすることはありません。 これは本当に重要なステップであり、インターネットセキュリティシステムを別の角度から見て、現在のアカウント所有者やハッキングの瞬間や性質を特定するなどの複雑なタスクを解決できます。
人を認識する方法は比較的最近登場したと考えられていますが、実際には、さまざまな識別方法の歴史は中世にそのルーツを持っています。 古代中国では、14〜15世紀の変わり目に、指紋を使用することをすでに推測していたことが知られています。 確かに、彼らは限られた範囲でこの方法を使用しました-商人はこうして貿易協定に署名しました。 19世紀の終わりに、 乳頭線の一意性がフィンガープリンティングの基礎を形成し、その創始者はウィリアムハーシェルでした。 人の手のひらの表面のパターンが彼の人生を通して変わらないという理論を提唱したのは彼でした。
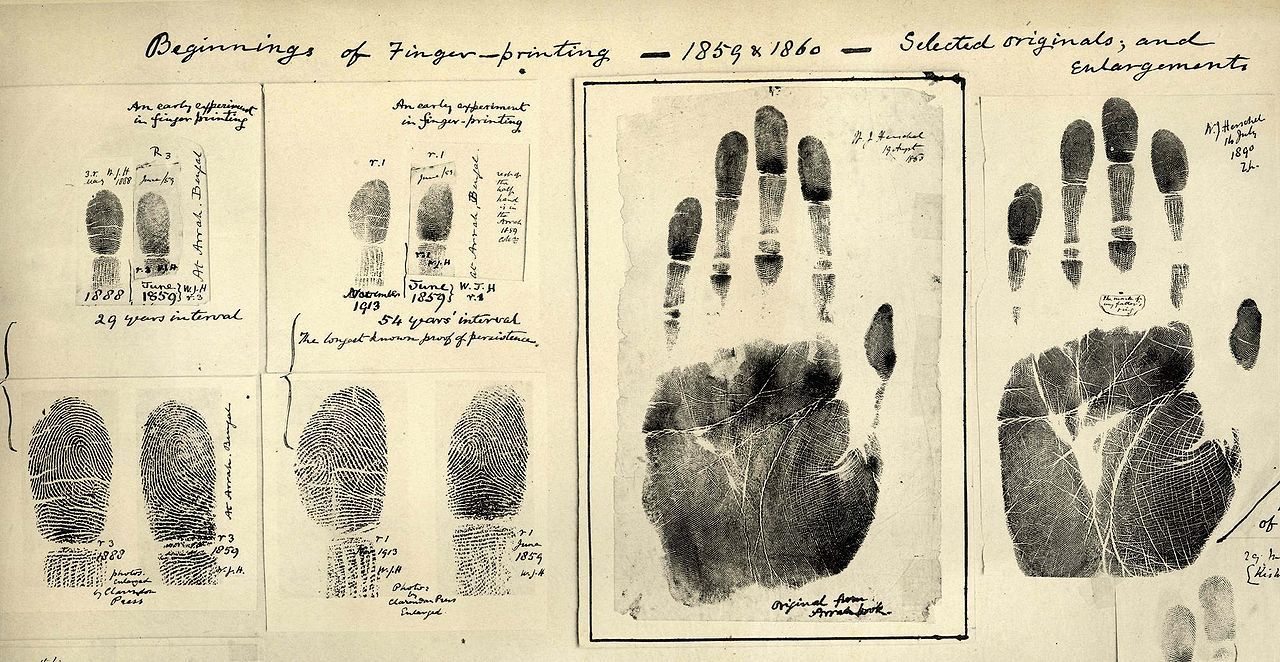
ハーシェル指紋カード
情報技術の発展に伴い、さまざまなユーザー認識システムが登場しています。 これらの方法のほとんどは、人が何らかのシステムへのアクセスを制御できるように設計されていますが、実際にはユーザーの識別と認証の領域ははるかに広くなっています。
世界中の科学者は、さまざまな理由で人を特定する問題に取り組んでいます。 さまざまなモデルと理論があります:すでに言及した指紋、虹彩、音声が認識に使用される最も人気のあるものから、マウスの動き、キーボードの「手書き」、およびWebサイトの動作を考慮した新しい物議を醸すものまであります。 Yandexは、既存のモデルを積極的に研究し、新しいモデルを作成しています。 私たちは旅の最初の段階にありますが、すでにいくつかの成功を収めているため、実験について少しお話ししたいと思います。
ユーザーを傷つける可能性のあるハッキング、スパム、悪意のある活動からメールボックスを保護するためのアルゴリズムに常に取り組んでいます。 既に存在するこれらのアクセス制御方法は、攻撃者がメールボックスに侵入することを困難にしますが、残念ながら、ハッキングの問題を完全に解決するわけではありません。 ボトルネックは、紛失、盗難、傍受、または盗まれたパスワードの使用のままです。 たとえば、安全な接続がサポートされていない他のサービスでYandexパスワードを使用すると、パスワードの傍受が発生する可能性があります。
「両方が同じパスワードで許可されている場合、攻撃者と現在のアカウント所有者を区別することは可能ですか?」と考えました。 私たちの調査では、メールボックスの所有者の振る舞いは、クラッカーの振る舞いとは常に異なることが示されています。
一般に、ログイン時間、通常の場所、認証の数、使用するデバイスなど、メールのユーザーの動作とは多くの特性を区別できます。特定の人には一般的ではない操作があります。 たとえば、既読の手紙の削除、フォルダの消去、ニュースレターの送信。 人は、さまざまな種類の手紙を扱うときに特定の行動をとることがあります。人からの手紙を読む、郵送を削除する、ソーシャルネットワークからの手紙を無視するなどです。 さらに、「下から上に一連の未読文字を読む」、「ログインして最初にメール、次にディスク、次にニュースに行く」などの習慣があります。 このような行動パターンは、多くのサービスで計算できます。 これらの要素の組み合わせから、ユーザーのプロファイルが形成されます。これにより、ユーザー自身の全体像はわかりませんが、アカウントハッキングの事実と通常の承認を区別することができます。 もちろん、このアプローチは機械学習を使用しないと効果的ではありません。 その助けにより、プロファイルとハッキングを決定するための境界に影響を与える一連の要因が決定されます。
この方法の本質は非常に単純です。誰もが自分だけの習慣を持っています。仕事と休息の体制から始まり、人が発生する場所と彼が使用するデバイスの数まで続きます。 たとえば、誰かが常に自宅と職場からのメールをチェックし、2台のデバイスを使用し、読んだ手紙を削除せず、スパムを送信しません。 彼は日中はメールを使用し、夜はメールをチェックしません。 また、誰かが1か月間旅行することが多く、さまざまな国からのメールを定期的に読み取ります。 これらのユーザーにはさまざまな動作パターンがあり、それに基づいて個々のプロファイルを作成し、メールへのすべての新しいエントリと比較できます。
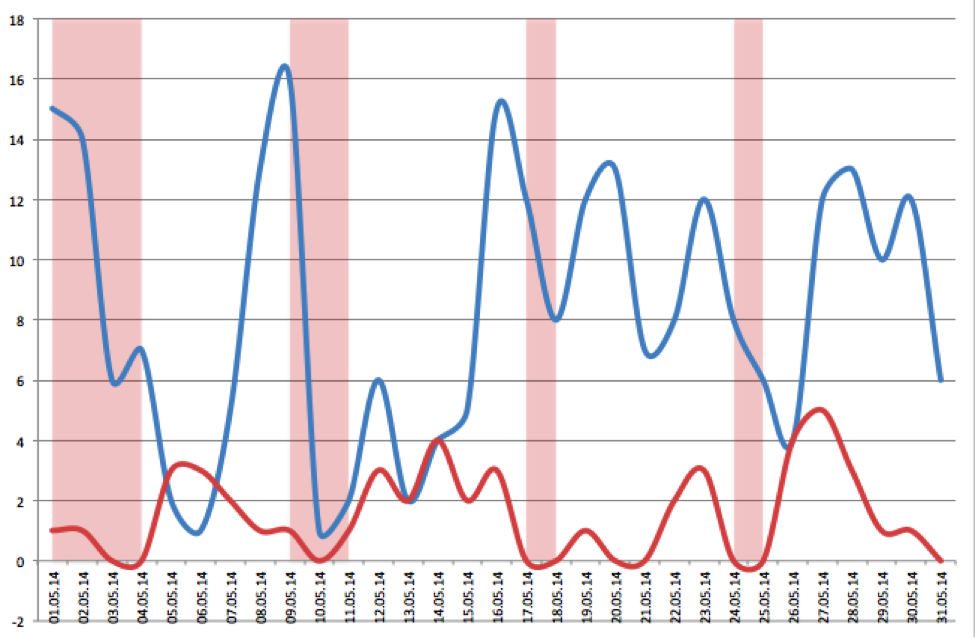
これは、2人の異なる人物のプロファイルの外観です。 赤いグラフは、ハッキングされていない通常のユーザーのプロファイルを示しています。 すべてがかなり均一であり、パラメーターに急激な変化がないことがわかります。 青いグラフは、疑わしいアカウントの動作を示しています。すべてのインジケータが強くジャンプし、リソースへの混oticとした呼び出しが追跡されます。 これにより、不正アクセスの事実を推測することができます。
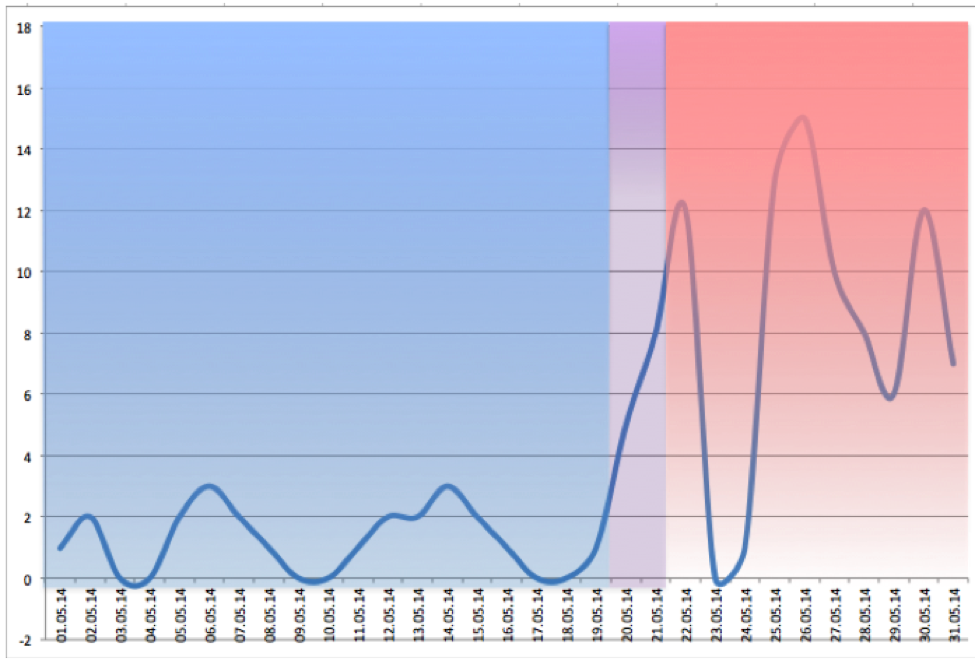
このグラフは、ハッキング時のプロファイルの変化を示しています。 青色の領域では、インジケータが正常であることがわかりますが、赤色のゾーンではすでに大きな変動が見られます。 さらに、これが発生した日付が明確に表示されるため、ハッキングの検索が大幅に簡素化されます。
このアプローチにより、ユーザーはパスワードやセッションCookieの盗難から保護され、アカウントでの承認後でもハッキングを検出できます。
私たちは、完全に機能する亀裂検出システムの立ち上げについて話す準備がまだできていません。 すべてのパズルの詳細がまだ組み立てられているわけではありません。これらのテクノロジーを活用する方法を十分に理解し、学習するには時間がかかります。 しかし、その有効性は現在明らかです。情報保護システムで機械学習を使用すると、保存されたデータのセキュリティが大幅に向上します。 したがって、この方向で作業を続けます。