測定方法
intキーと値を持つハッシュマップがテストされました。
メモリ使用量の測定値は、特定のサイズのマップの理論上の最小値を超える追加の占有メモリの相対的な量です。 たとえば、1000個のintキーと値のペアが占める(4(intサイズ)+ 4)* 1000 = 8000バイト。 このサイズのマップが20,000バイトを占める場合、メモリ使用量の測定値は(20,000-8,000)/ 8000 = 1.5になります。
各実装は、9つの負荷係数でテストされています。 各レベルの各実装は10個のサイズで実行され、1000〜100,000の間で対数的に均等に分散されました。その後、メモリ使用量インジケーターと平均操作実行時間は独立して平均されました。 )および1000から10 000 000までの10個すべて(すべてのサイズ)。
実装:
- 高頻度取引コレクション(HFTC)
- 高性能プリミティブコレクション(HPPC)
- fastutilコレクション
- ゴールドマンサックスコレクション(GS)
- Troveコレクション
- Mahoutコレクション
- 比較のための
java.util.HashMap
。 他のすべての実装はプリミティブな特殊化であり、HashMap
ボックスの値であるため、比較は明らかに不正ですが、それでもなお行われます。
キー値の取得(検索の成功)
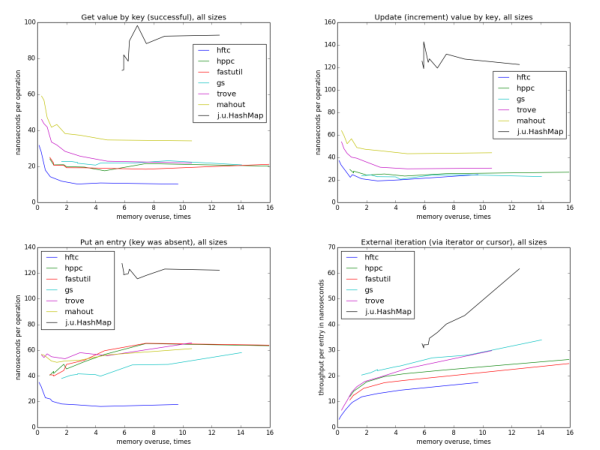
これらの写真を見ると、HFTC、Trove、Mahout、fastutil、HPPC、GSが同じハッシュアルゴリズムを使用していると想定できます。 (実際、これは完全に真実ではありません。)平均して、より多くのスパースハッシュテーブルは、キーを見つける前にチェックするスロットが少ないため、メモリからの読み取りが少ないため、操作は高速です。 小さいサイズでは、6つの実装すべてで最もアンロードされたマップが最速ですが、大きいサイズでは、メモリ再利用係数〜4から始まるすべてのサイズで平均すると、加速は表示されません。 これは、マップの合計サイズがいずれかのレベルのキャッシュ容量を超える場合、マップサイズがさらに大きくなるとキャッシュミスが頻繁になるためです。 この効果は、テストされた少数のスロットからの理論的なゲインを補正します。



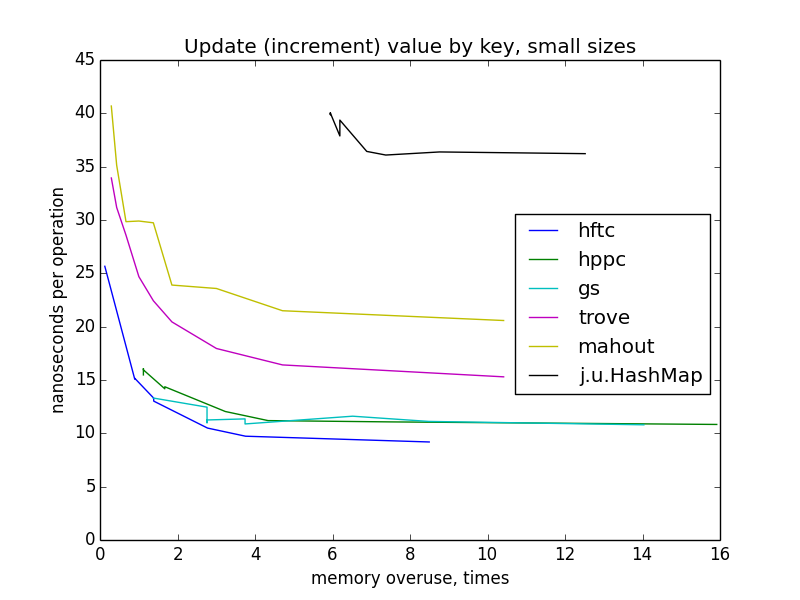
キー値の更新(増分)
この更新は、キーキャプチャによく似ています。 fastutil実装は、この操作用に特別に最適化されたメソッドがないため、テストされませんでした(同じ理由で、他の操作をテストする場合、一部の実装は利用できません)。


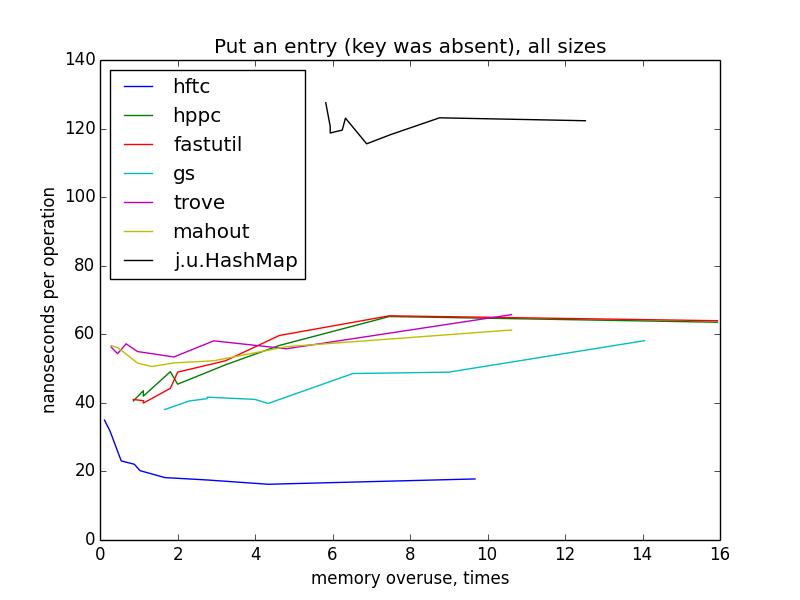
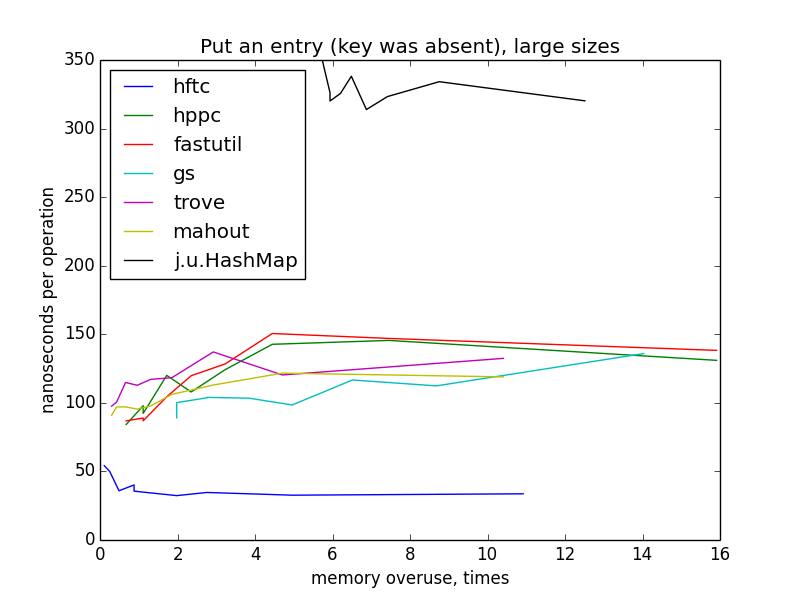
キーと値のペアの作成(キーはマップにありませんでした)
この操作を測定するために、マップはゼロから目標サイズ(1000〜100,000)まで埋められました。 マップはコンストラクターでターゲットサイズで初期化されているため、ハッシュテーブルの再構築は発生しません。
小さなサイズでもグラフィックは双曲線のように見えますが、大きなサイズに切り替えたときの画像のこのような急激な変化とHFTCと他のプリミティブな実装の違いについて明確な説明はありません。

内部反復(forEach)
単一キー操作とは対照的に、メモリ効率が低下すると反復は遅くなります。 また、すべてのオープンハッシュ実装について、同じ再利用レベルでの実装ごとに速度が異なるため、速度がメモリの再利用の指標のみに依存し、テーブルの理論的なワークロードには依存しないことも興味深いです。 また、他の操作とは異なり、forEachの速度はテーブルのサイズに実質的に依存しません。
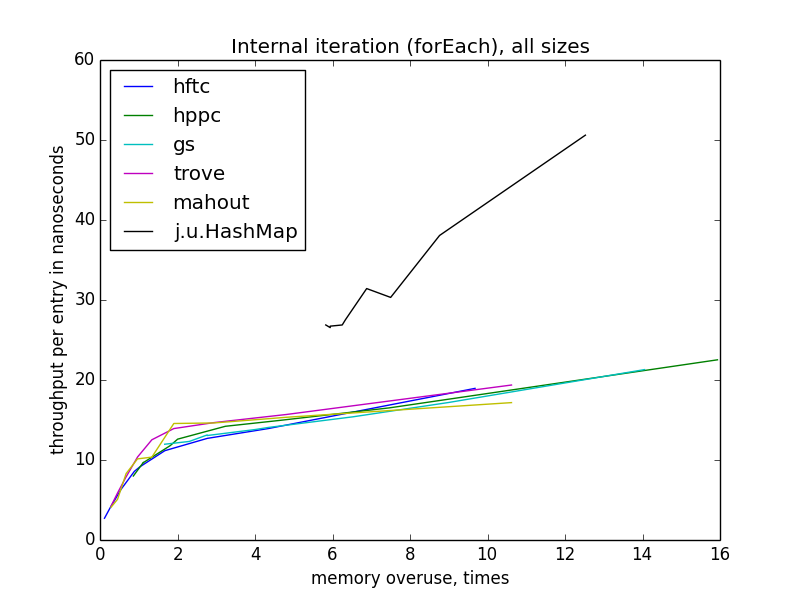
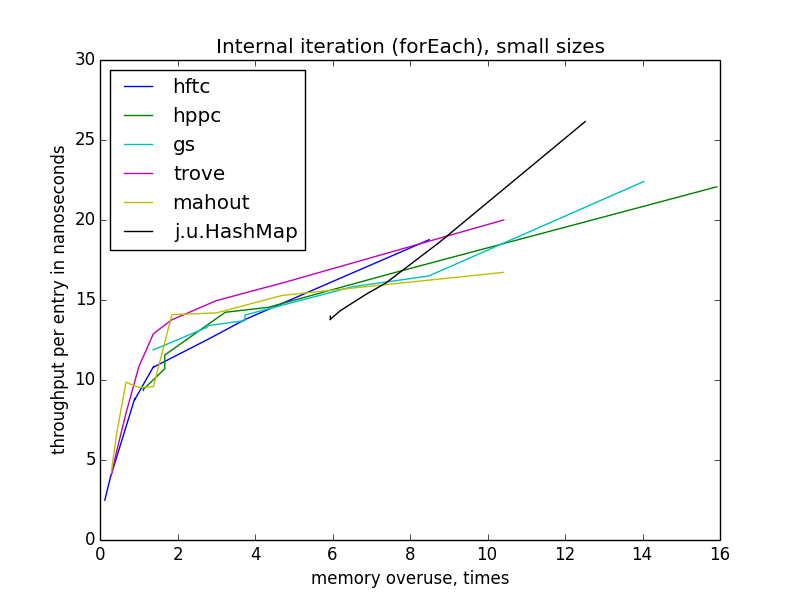

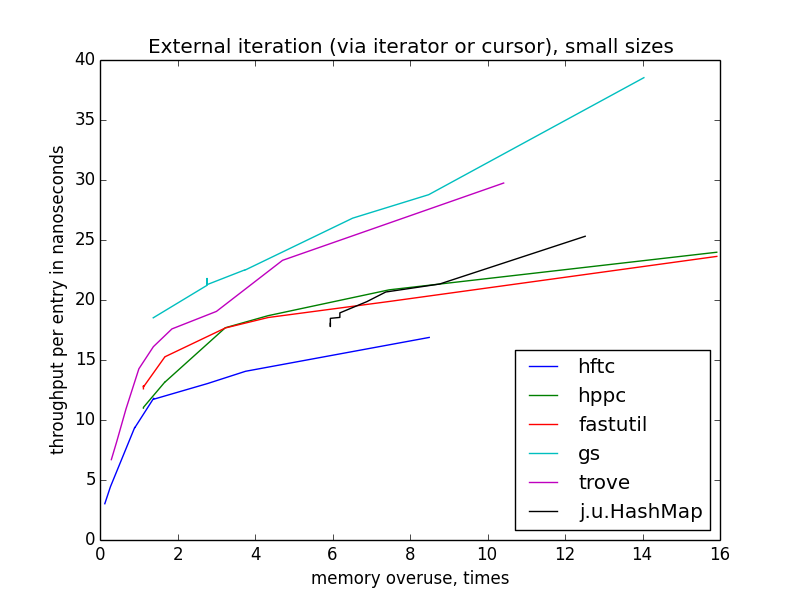
外部反復(イテレーターまたはカーソルを使用)
外部反復の速度は、内部最適化よりもはるかに速くなります。これは、最適化のためのスペースが増えるためです(より正確には、最適でないものを実行する機会が増えます)。 HFTCとTroveは独自のインターフェイスを使用し、他の実装は通常の
java.util.Iterator
使用します。


この投稿で写真が作成された測定の生の結果 。 その説明には、ベンチマークコードへのリンクとランタイムに関する情報があります。
PS この記事は英語です。