
夕方に座って、何か役に立つことをする必要に苦しんでいますが、私はそのようには感じません。ニューラルネットワークに関する別の記事に出会い、火をつけました。 最後に、独自のニューラルネットワークを作成する必要があります。 アイデアは当たり前です:誰もがニューラルネットワークを愛し、オープンソースの例がたくさんあります。 私は時々LeNetとOpenCVネットワークの両方を使用しなければなりませんでした。 しかし、私は紙の破片だけでそれらの特徴とメカニズムを知っていることにいつも警戒していました。 そして、「神経回路網は逆伝播法によって教えられている」という知識とこれを行う方法の理解との間には、大きなギャップがあります。 そして、私は決めました。 1〜2晩座って、自分でそれを実行し、理解して理解する時間です。
ライダーのいない馬のタスクのないニューラルネットワーク。 ニューラルネットワークによって行われる深刻なタスクを解決するには、デバッグと処理に多くの時間を費やします。 したがって、簡単なタスクが必要でした。 純粋に数学的に解決できる信号処理の最も単純なタスクの1つは、ホワイトノイズの検出の問題です。 問題のプラスは、紙で解決できるということです。数学的な解決策と比較して、結果のネットワークの精度を評価できます。 結局のところ、すべてのタスクで、式をチェックするだけでニューラルネットワークがどの程度うまく機能したかを評価できます。
タスク
まず、問題を定式化します。 N個の要素のシーケンスがあるとします。 シーケンスの各要素には、期待値がゼロで分散が1つのノイズがあります。 信号Eがあります。これは、0.5からN-0.5の中心を持つこのシーケンス内にあります。 ピクセルの中心にいるとき、ほとんどのエネルギーが同じピクセルにあるように、そのような分散を持つガウスで信号を設定します(非常にポイント1で退屈になります)。 シーケンスに信号があるかどうかを判断する必要があります。
「なんて合成タスクだ!」とあなたは言います。 しかし、これは完全に真実ではありません。 この問題は、ポイントオブジェクトを使用するたびに発生します。 それは、画像内の星、時系列の反射ラジオ(音、光)パルス、望遠鏡の飛行機や衛星はもちろんのこと、顕微鏡下の微生物でさえあります。
もう少し厳密に書きます。 一定の分散を持ち、数学的な期待値がゼロの通常のノイズを含む信号シーケンスl 0 ... I nがあるとします。
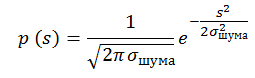
ピクセルに信号sが含まれる確率はp(s)に等しくなります。 分散1および期待値0の正規分布ノイズで満たされたシーケンスの例:

一定の信号対雑音比、SNR = E_signal /σ_noise= constの信号もあります。 信号のサイズがピクセルのサイズにほぼ等しい場合、これを記述する権利があります。 私たちからの信号もガウスによって設定されます:
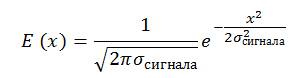
簡単にするため、σ_signal= 0.25∙Lと仮定します。Lはピクセルサイズです。 これは、ピクセルの中心に位置する信号の場合、ピクセルには-2σ〜+2σの信号エネルギーが含まれることを意味します。
これは、ノイズのある最後のシーケンスがどのように見えるかであり、その上に信号がポイント4.1を中心とするSNR = 5で重畳されます。

ところで、 正規分布を生成する方法を知っていますか?
面白いですが、多くの人が中心極限定理を使ってそれを生成します。 この方法では、6つの線形分布値が-0.5〜0.5の範囲で追加されます。 結果として生じる値は、単一性の分散で正規分布していると考えられています。 しかし、この方法では、大きな偏差を伴う不正確な分布テールが得られます。 正確に6つの量を取得する場合、max = | min | = 3 = 3 *σ。 これにより、実装の0.2%が即座に遮断されます。 100 * 100の画像を生成する場合、そのようなイベントは20ピクセルで発生するはずであり、それほど小さくありません。
良いアルゴリズムがあります: Box-Muller 変換、George Marsagli変換
このテーマに関するHabréの良い記事があります。
これらの方法はすべて、区間[0; 1]の線形分布を正規分布に数学的に変換することに基づいています。
ニューロン
ニューラルネットワークについて多くのことが書かれています。 リンクや主要なポイントのみに限定して、詳細に入らないようにします。
ニューラルネットワークはニューロンで構成されます。 ニューロンが人にどのように配置されているかを正確に知る人はいませんが、多くの美しいモデルがあります。 habrには、ニューロンに関する多くの興味深い記事がありました: 1、2など。
この問題では、信号のシーケンスがニューロンの入力に供給され、それが加算されて活性化関数を実行するときに、ニューロンの最も単純なスキームを基礎として取りました。
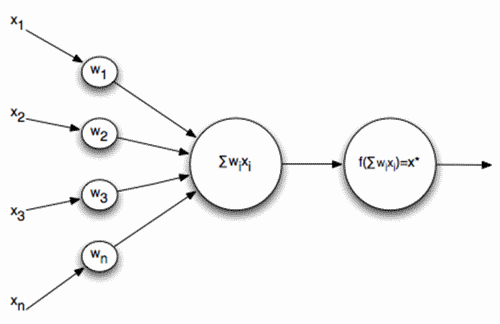
アクティベーション機能はどこにありますか:
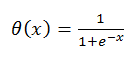
そのようなニューロンはそのようなモデルで何をし、なぜ活性化機能が必要なのですか?
ニューロンは、トレーニング対象の特定のパターンと比較されます。 また、アクティベーション関数は、パターンがどれだけ一致してソリューションを正規化するかを決定するトリガーです。 何らかの理由で、ニューロンはトランジスタのように見えることがよくありますが、これは叙情的な余談です。
アクティベーション機能をステップにしてみませんか? 多くの理由がありますが、主な理由は、少し後で説明しますが、ニューロン機能の分化を必要とする学習機能です。 上記のアクティベーション関数には、非常に優れた差異があります。

ニューラルネットワーク
ネットワークがあります。 問題を解決する方法は? 単純な問題を解決する古典的な方法は、この種のニューラルネットワークを作成することです。
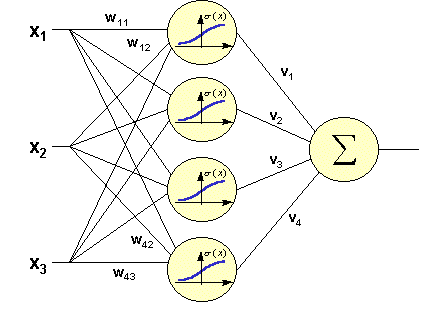
入力信号、1つの隠れ層(各ニューロンがすべての入力要素に接続されている)、および出力ニューロンがあります。 このようなネットワークのトレーニングは、実際には、すべての係数wとvを設定しています。
ほとんどこれを行いますが、タスク用に最適化した後です。 入力画像のすべてのピクセルについて、隠れ層のすべてのニューロンをトレーニングするのはなぜですか? 最大信号には3ピクセル、おそらく2ピクセルもかかります。 したがって、隠れ層の各ニューロンを3つの隣接ピクセルのみに接続します。
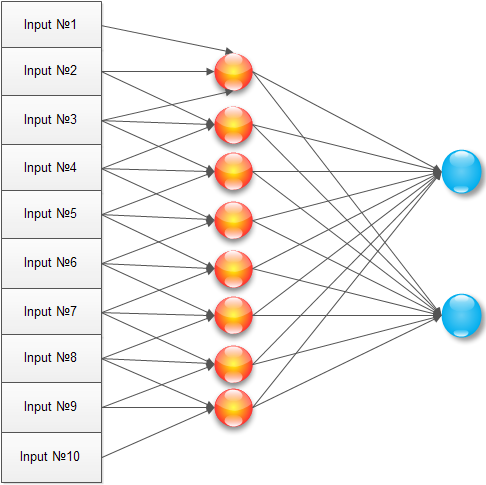
この構成では、ニューロンは画像の近くでトレーニングされ、ローカル検出器として機能し始めます。 非表示レイヤー(1..N)のトレーニング済み要素の配列は次のようになります。
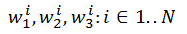
実験として、2つの出力ニューロンを導入しましたが、後で判明したように、これはあまり意味がありませんでした。
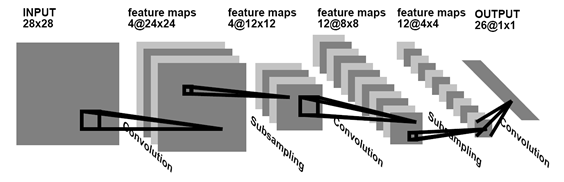
このタイプのニューラルネットワークは、作業で使用されている最も古いものの1つです。 最近、ますます多くの人々が畳み込みネットワークを使用しています。 畳み込みネットワークについては、すでにハブに繰り返し記述されています: 1、2 。
たたみ込みネットワークとは、画像全体に共通する既存のパターンを検索して記憶するネットワークです。 通常、ニューラルネットワークとは何かを示すために、次のような画像を描きます。
しかし、それをコーディングしようとすると、脳は「どうやってこれを現実に適用することができるか」から混乱に陥ります。 しかし実際には、上記のニューラルネットワークの例は、たった1つのアクションで畳み込みネットワークに変換されます。 これを行うには、学習時に要素w 1 1 、...、w 1 Nが異なる要素ではなく、同じ要素w 1であると仮定するだけで十分です。 次に、隠れ層をトレーニングした結果、たたみ込みである3つの要素w 1 、w 2 、w 3のみが見つかります。
確かに、1つの畳み込みでは問題を解決するのに十分ではないため、2番目の畳み込みを入力する必要がありますが、これは、要素1..Nが最初の畳み込みを訓練し、要素N. 2Nは2番目です。
トレーニング
ニューラルネットワークは簡単に描画できますが、訓練するのはそれほど簡単ではありません。 初めてこれを行うと、脳は少し回転します。 しかし、幸いなことに、RuNetには2つの非常に優れた記事があり、その後、すべてが1日として明確になります。1、2
1つ目は学習のロジックと順序を非常によく示し、2つ目は明確に定義された数学的本質を持っています:数式から得られるもの、ニューラルネットワークの初期化方法、係数の計算方法と適用方法。
一般に、エラーの逆伝播の方法は次のとおりです。既知の信号を入力に適用し、それを出力ニューロンに分配し、目的の結果と比較します。 不一致がある場合、エラー値に接続の重みが乗算され、最後の層のすべてのニューロンに渡されます。 すべてのニューロンがエラーを知ったら、エラーが減少するように学習係数をシフトします。
どちらかといえば、学習を恐れてはいけません。 たとえば、エラー定義は次のように1行で作成されます。
public void ThetaForNode(Neuron t1, Neuron t2, int myname) { // BPThetta = t1.mass[myname] * t1.BPThetta + t2.mass[myname] * t2.BPThetta; }
そして、このような重みの修正:
public void CorrectWeight(double Speed, ref double[] massOut) { for (int i = 0; i < mass.Length; i++) { // + ****(1-) massOut[i] = massOut[i] + Speed * BPThetta * input[i] * RESULT * (1 - RESULT); } }
結果
そもそも、約束どおり、「あるべき姿」を計算します。 SNR(信号対雑音)比が3であるとします。この場合、信号は雑音分散の3倍です。 ピクセル内の信号が値Xをとる確率を描画しましょう。
グラフには、ノイズの確率分布のみのグラフと、SNR = 3の比率のポイントでの信号+ノイズの確率分布のグラフのみが表示されます。 信号の検出を決定するには、特定のXを選択し、それより大きいすべての値を信号、すべての値がノイズより小さいと見なす必要があります。 誤警報とオブジェクトのスキップについて決定した確率を描画します(赤いグラフの場合、これはその積分であり、青い「1積分」の場合):
このようなグラフの交点は、通常EER(Equal Error Rate)と呼ばれます。 この時点で、誤った決定の確率は、オブジェクトを失う確率に等しくなります。
この問題では、10個の入力信号があります。 このような状況でEERポイントを選択する方法は? 簡単です。 Xsの選択された値で誤警報が発生しない確率は次の値に等しくなります(最初の図の青いグラフで積分):
したがって、10ピクセルで誤報が発生していない確率は次の値に等しくなります。
少なくとも1つの誤報が発生した確率は1-Pです。 1-Pグラフと、その隣のオブジェクトスキップ確率のグラフ(2番目のグラフから複製)を描画しましょう。
したがって、SNR = 3での信号とノイズのEERポイントは2つの領域にあり、EER≒0.2です。 そして、ニューラルネットワークは何を提供しますか?
ニューラルネットワークは、指で解決した問題よりもわずかに悪いことがわかります。 しかし、すべてがそれほど悪いわけではありません。 数学的考察では、いくつかの特徴を考慮しませんでした(たとえば、信号がピクセルの中心に移動しないことがあります)。 特に深く行くことなく、これは統計を著しく悪化させないが、悪化させると言うことができます。
正直に言うと、私はこの結果に勇気づけられました。 ネットワークは、純粋に数学的問題にうまく対処します。
付録1
それにもかかわらず、私の主な仕事は、ニューラルネットワークをゼロから作成し、ワンドを突くことでした。 このセクションでは、ネットワークの動作に関するいくつかの面白いgifがあります。 ネットワークは理想からはほど遠いことが判明しました(このトピックはHabréで人気があるため、この記事には専門家によるコメントがつぶれると思います)が、執筆の結果として多くのデザインとライティング機能を学び、今後はそれを繰り返さないようにしますので、私は個人的に満足しています。
通常のネットワークの最初のGIF。 上のバーは時間の入力信号です。 SNR = 10、信号ははっきりと見えます。 下の2つのストリップは、最後のニューロンの合計への入り口です。 ネットワークが画像を安定させ、信号がオンまたはオフになると、最後のニューロンの入力のコントラストのみが変化することがわかります。 信号がない場合、画像がほとんど静止しているのは面白いです。
2番目のGIFは畳み込みネットワークと同じです。 最後のニューロンへの入力数が2倍に増加します。 しかし、原則として、構造は変わりません。
付録2
すべてのソースはこちら-github.com/ZlodeiBaal/NeuronNetworkにあります。 C#で書かれています。 OpenCV dllはサイズが大きいため、ダウンロード後にlib.rarフォルダー内で解凍する必要があります。 または、ここからプロジェクトをすぐにダウンロードします。何も解凍する必要はありません-yadi.sk/d/lZn2ZJ_BWc4DB 。
コードは午後2時にどこかで書かれたため、業界標準からはほど遠いですが、はっきりしているようです(確かにHabrに関する記事を長く書いたのです)。