内容
一般認識理論
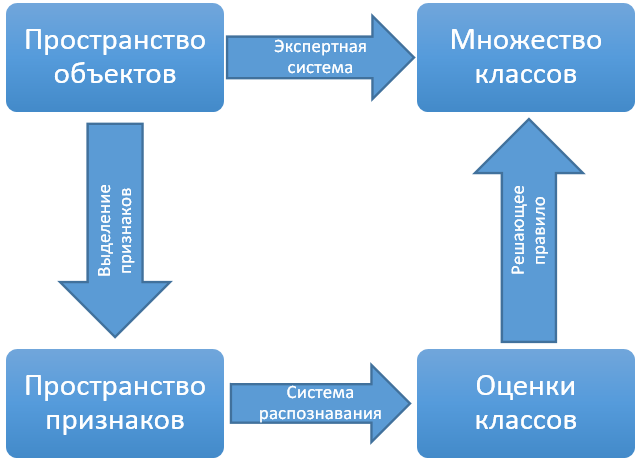
最後に、最も興味深いトピックである文字認識に到達しました。 しかし、最初に、理論を少し見て、正確に何を、なぜ私たちがしているのかを明確にします。 自動認識または機械学習の一般的なタスクは次のとおりです。
クラスCの特定のセットとオブジェクトRのスペースがあります。任意のオブジェクトに対してどのクラスに属するかを判別できる特定の外部「エキスパート」システムがあります。
自動認識のタスクは、転送された事前分類オブジェクトの限られた選択に基づいて、転送された新しいオブジェクトに対応するクラスを提供するシステムを構築することです。 さらに、「エキスパート」システムと自動認識システムとの間の分類の全体的な違いは最小限に抑える必要があります。
クラスシステムは離散または連続であり、多くのオブジェクトはあらゆる種類の構造であり、エキスパートシステムは任意であり、通常の人間のエキスパートから始まり、オブジェクトの特定のサンプルでのみ精度を評価できます。 しかし基本的に、自動検索のほとんどすべてのタスク(検索結果のランク付けから医療診断まで)は、特定の空間のオブジェクトとクラスのセット間のリンクを構築することになります。

しかし、そのような定式化では、タスクは実際には無意味です。なぜなら、オブジェクトが何であり、どのようにそれらを操作するのかが完全に不明確だからです。
したがって、通常、次のスキームが適用されます。少なくとも何らかの形でオブジェクト間の距離を決定できる特定の標識スペースが構築されます。 オブジェクトの空間から標識の空間への変換は現在準備中です。 構築中の変換の主な要件は、「コンパクト性仮説」に準拠しようとすることです。特徴空間内の近くにあるオブジェクトは、同じまたは類似のクラスを持たなければなりません。
したがって、元のタスクは次の手順に分割されます。
- 「コンパクトな仮説」を考慮して、オブジェクトの空間からサインの空間への変換を構築します
- 使用可能なマークアップされたオブジェクトのサンプルに基づいて属性スペースをマークします。これにより、各ポイントは、このポイントが異なるクラスに属するかどうかの推定セットに対応します。
- 一連の推定に基づいて、オブジェクトがどのクラスに属するかを最終的に決定する決定的なルールを作成します。
アルゴリズムの3番目のステップについて少し説明します。これは、システム内でアイデアがシンプルで実装もシンプルなまれな場所の1つであるためです。 いくつかの文字認識システムがあり、これらのシステムのそれぞれは、ある程度の自信を持って認識オプションのリストを提供します。 決定ルールのタスクは、すべてのシステムの認識オプションのリストを1つの共通リストにマージし、複数のシステムの認識品質を1つの不可欠な品質に結合することです。 品質は、分類子用に特別に選択された式を使用して組み合わされます。
そして、認識クラスに関するもう1つの発言-この記事では、「シンボル」という言葉を使用します。これは、理解しやすく、誰もが知っているからです。 しかし、これはテキストを単純化するためだけに行われました。実際、シンボルではなく書記素を認識します。 書記素は、シンボルをグラフィカルに表現する特定の方法です。 記号と書記法の関係は非常に複雑です-いくつかの書記法は1つの書記法に対応できます(ラテン語とキリル文字の小さい「C」と大きい「C」はすべて書記法です)。異なる書記法である可能性があります)。 書記素の標準リストは存在せず、それを自分でコンパイルし、書記素ごとに、対応できる文字のリストが与えられます。 書記素から文字への変換は、単語認識オプションを生成する段階での文字認識後に行われます。


文字「a」の2つの異なる書記素の例。
分類子の作業品質の評価に関するいくつかの事実:
- 互いに補完するいくつかの分類器を使用します。 つまり、いずれの場合でも、通常の品質評価は、決定ルールの適用後に取得されたオプションの統合リストの評価にすぎません。
- 単語のバリエーションを列挙する段階では、多くのコンテキスト情報が使用されますが、これは単一の文字内には存在しません。 したがって、分類器は常に最初に必要な認識オプションを配置する必要はありません-代わりに、正しいオプションが最初の2つまたは3つの認識オプションにあることが必要です。
認識システム
私たちのプログラムはいくつかの異なる分類器を使用します。これらは主に使用される機能が異なりますが、同時に認識システム自体の構造は実質的に同じです。
文字認識システムに必要な要件は非常に簡単です。
- システムは、可能性のある文字の任意のソースセットで等しく動作する必要があります。 ユーザーが認識のために選択する言語または言語の組み合わせを事前に知ることができないためです。 さらに、ユーザーは通常、一般的に任意のアルファベットで自分の言語を作成する機会があります。
- 認識可能な文字を制限すると、品質が向上し、分類子の作業が高速化されるはずです。 ユーザーがドキュメントの認識言語を選択すると、改善に気付くはずです。
これらの2つの要件に関連して、複雑でインテリジェントな認識システムを使用することはあまり一般的ではありません。 多くの場合、彼らはニューラルネットワークについて質問するので、すぐに書いた方が良いです-いいえ、多くの理由でそれらを使用しません。 それらの主な問題は、認識可能なクラスの残酷に修正されたセットと過度の内部複雑性であり、これにより分類子の正確な調整が非常に複雑になります。 ニューラルネットワークの詳細な議論は大きなホリバーのトピックなので、使用するものについてお話ししたいと思います。
そして、さまざまなベイジアン分類器を使用します。 彼のアイデアは次のとおりです。
記号空間(x)の特定のポイントについて、異なるクラス(C 1 、C 2 、...、C n )に属する確率を評価する必要があります。
正式に記述する場合、オブジェクトが属性空間でポイントx-P(C i | x)で記述されている場合、オブジェクトのクラスがC iである確率を計算する必要があります。
確率論の基本的なコースからベイズ公式を適用します。
P(C i | x)= P(C i )* P(x | C i )/ P(x);
その結果、異なるクラスの確率を比較してシンボルの答えを決定します。したがって、すべてのクラスに共通する式から分母を除外します。 異なるクラスの値セットP(C i )* P(x | C i )を比較し、それらから最大値を選択する必要があります。
P(C i )は、クラスのアプリオリ確率です。 認識されたオブジェクトに依存せず、事前に計算できます。 可能なクラス(アルファベット)のセットについては、指定された言語での文字の出現頻度によって事前に計算できます。 そして、練習は、すべてのキャラクターの同じ先験的確率をとることがより良い場合があることを示しています。
P(x | C i )は、特定のクラスC iがxの記述を持つオブジェクトを取得する確率です。 この確率は、分類器のトレーニング段階で事前に決定できます。 ここでは、数学的統計の完全に標準的な方法が機能します。属性空間のクラスの分布形式(標準、均一、...)を仮定し、このクラスのオブジェクトの大きなサンプルを取得し、このサンプルから選択した分布に必要なパラメーターを決定します。

分類子をトレーニングするための画像データベースの非常に小さな断片。
ベイジアン分類器を使用できるのはなぜですか? このシステムは、認識アルファベットから完全に独立しています。 各クラスの確率分布は、サンプルによって完全に独立していると見なされます。 実際には、クラスにアプリオリ確率を使用しない方が良いでしょう。 各クラスの最終グレードは確率であるため、どのクラスでも同じ範囲にあります。
したがって、ゼロと1のバイナリコードのイメージと、4〜5言語のフレーズブックのテキストの両方で、追加の設定なしで機能するシステムが得られます。 さらに、確率モデルの解釈は非常に簡単であり、必要に応じて個々のキャラクターを個別にトレーニングできます。
機能スペース
前述したように、システムにはいくつかの文字分類子があり、これらの分類子の主な違いは属性空間にあります。
分類子の標識のスペースは、2つのアイデアの組み合わせに基づいています。
- 属性空間が固定長の数値ベクトルで構成されている場合、ベイジアン分類器が機能するのは非常に簡単です-数値ベクトルの場合、分布パラメーターを復元するために必要な数学的期待値、分散、およびその他の特性を考慮するのは非常に簡単です。
- 画像の特定の断片の黒の量など、基本的な特性が画像上で計算される場合、そのような特性はそれぞれ、特定のシンボルに属する画像については何も言いません。 しかし、そのような特性の多くを1つのベクトルに収集すると、これらのベクトルの合計はすでにクラスごとに著しく異なります。
そのため、次のように構築されたいくつかの分類器があります:多くの(数百のオーダーの)基本特徴を選択し、それらからベクトルを収集し、そのようなベクトルを特徴空間として宣言し、それらにベイジアン分類器を構築します。
簡単な例として、画像をいくつかの縦縞と横縞に分割し、各縞について黒と白のピクセルの比率を考慮します。 さらに、結果のベクトルの正規分布があると考えています。 正規分布の場合、数学的期待値と分散を計算して、分布パラメーターを見つける必要があります。 ベクター上でこれを行うには、かなり多くのエレメンタリーを選択します。 したがって、非常に単純な属性から、単純な数学の助けを借りて、実際にはかなり高品質の分類器を取得します。
これは単純化された例であり、実際に使用されている特定の組み合わせや正確な兆候は、蓄積された経験と長い研究の結果であるため、ここではそれらについて詳しく説明しません。
ラスター分類器
別途、ラスター分類器について記述する必要があります。 文字認識のために考えられる最も単純な機能空間は、画像そのものです。 いくつかの(小さな)サイズを選択し、任意の画像をこのサイズにし、実際には固定長の値のベクトルを取得します。 ベクトルの追加と平均化の方法は誰もが知っているので、属性の完全に通常の空間ができます。
これが最も基本的な分類子-ラスターです。 1つの書記素のすべての画像をトレーニングベースから同じサイズにした後、それらを平均します。 結果は、各ドットの色が特定のシンボルに対してこのドットが白または黒になる確率に対応するグレー画像です。 必要に応じて、ラスター分類子をベイジアンとして解釈し、この画像がシンボルの標準で表示される特定の確率を考慮することができます。 しかし、この分類子の場合、このアプローチはすべてを複雑にするだけなので、白黒画像とグレー標準の間の通常の距離を使用して、画像が特定のクラスに属しているかどうかを評価します。
ラスター分類器の利点は、その単純さと速度です。 また、マイナスの精度は低く、主に同じサイズに縮小すると、シンボルのジオメトリに関するすべての情報が失われるため、この分類子のドットと文字「I」は同じ黒い四角に縮小されます。 結果として、この分類器は、認識オプションの初期リストを生成するための理想的なメカニズムであり、より複雑な分類器を使用して改良できます。


1文字のラスター標準のいくつかの例。
構造分類器
印刷されたテキストに加えて、当社のシステムは手書きのテキストも認識できます。 そして、手書きのテキストの問題は、たとえ人がブロック文字で書き込もうとしても、そのばらつきが非常に大きいことです。
したがって、手書きテキストの場合、すべての標準分類子は十分な品質を提供できません。 システムのこのタスクには、もう1つのステップがあります-構造分類子です。
彼のアイデアは次のとおりです。各シンボルは実際に明確に定義された構造を持っています。 しかし、画像内でこの構造を強調表示しようとすると、何も機能せず、変動性は非常に大きく、見つかった構造を可能なシンボルの構造と何らかの形で比較する必要があります。 しかし、基本的な分類子はあります-それらは不正確ですが、99.9%の場合、正しい認識オプションは、たとえば上位10個のオプションのリストに残っています。
それでは、バックエンドから行きましょう。
- 各シンボルについて、ライン、アーク、リングなどの基本的な要素でその構造を説明します...説明は手動で行う必要がありますが、これは大きな問題ですが、これまでのところ、私たちにとって許容できる品質のトポロジーを自動選択することはできませんでした。
- シンボルの構造的な説明については、画像内でそれを検索する方法、つまりどの要素から開始し、どの順序で移動するかを個別に説明します。
- 文字を認識するとき、基本的な分類器を使用して可能な認識オプションの小さなリストを取得します。
- 各認識オプションについて、それに対応する構造記述を画像で見つけようとします。
- 説明が出てきたら、その品質を評価します。 適合しませんでした-つまり、認識オプションがまったく適合しません。
このアプローチでは特定の仮説をテストするため、画像内で何を正確にどの順序で探すかを常に確実に知っているため、構造を選択するためのアルゴリズムが大幅に簡素化されます。

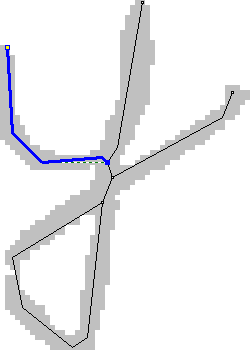


シンボル画像で選択された構造要素の例
微分分類器
分類子セットのアドオンとして、まだ差分分類子があります。 以下に登場する理由は、いくつかの小さな非常に特殊な機能を除き、互いに非常に似ている文字のペアがあることです。 さらに、キャラクターのペアごとに、これらの機能は異なります。 これらの機能に関する知識を共通の分類子に埋め込むと、一般的な分類子には記号が過剰に表示され、ほとんどの場合、それぞれの利点は得られません。 一方、通常の分類子の作業の後、認識仮説のリストが既にあり、どのオプションを互いに比較する必要があるかを正確に知っています。
したがって、類似した文字のペアに対して、これらの2つのクラスを正確に区別し、これらの2つのクラスについてのみこれらの機能に基づいて分類子を構築する特別な機能を見つけます。 認識オプションに近い推定値を持つ2つの類似したバリアントがある場合、このような分類器は、これら2つのオプションのどちらが望ましいかを正確に伝えることができます。
私たちのシステムでは、すべての主要な分類子が文字認識オプションのリストをさらにソートするために動作した後、差分分類子が使用されます。 同様の文字のペアを識別するために、基本的な分類子のみを使用する場合に最も頻繁にどの文字がどの文字と混同されるかを調べる自動システムが使用されます。 次に、疑わしいペアごとに、追加の機能が手動で選択され、差分分類器がトレーニングされます。
実践では、通常の言語では、親しい文字のペアはあまり多くないことが示されています。 さらに、新しい微分分類器をそれぞれ追加すると、認識が大幅に向上します。
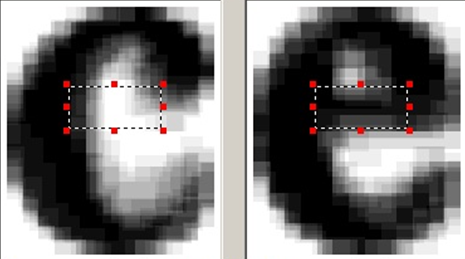
同様の文字のペアの追加機能を強調表示するためのサンプル領域。
結論として
この記事は、FineReaderおよび当社の他の製品で認識のために使用されるメカニズムの正確な説明であると主張するものではありません。 この説明は、テクノロジーを作成するために使用された基本的な原則のみです。 実際のシステムは大きすぎて複雑であるため、Habréの2つまたは3つの記事では説明できません。 そこにすべてが本当に配置されていることに本当に興味があるなら、それは良いです