CROCはそのような経験の印象を既に共有していますが、主に総合テストの結果と熱心な声明の形で、どのストレージシステムにも当てはまりますが、壮観ではありますが、有益ではありません。 私は現在、インテグレーターではなく顧客で働いています。アプリケーションの側面は私たちにとってより重要なので、テストは適切な方法で編成されました。 しかし、順番に。
一般的な情報
XtremIOは、EMCの新しい(比較的)製品、またはEMCによって買収されたXtremIOです。 これは、コントローラーとしての2つのIntelシングルサーバーサーバー、2つのEaton UPS、1つの25ディスクドライブシェルフの5つのモジュールで構成されるオールフラッシュアレイです。 XtremIOの拡張ユニットである上記のすべてがブリックに結合されています。
キラー機能のソリューションは、「オンザフライ」での重複排除です。 フルクローンでVDIを使用しており、多くのクローンがあるため、この事実に特に興味がありました。 マーケティングは、それらがすべて1つのブリックに収まることを約束しました(ブリック容量-7.4 TB)。 現時点では、通常のアレイでほぼ70 TB以上を占めています。
物語の主題を撮影するのを忘れましたが、 CROCの投稿ですべてを詳細に見ることができます。 これは同じ配列であると確信しています。
インストールとセットアップ
デバイスはミニラックに取り付けられています。 私たちは考えずに一緒にそれを取りに行き、車からカートにドラッグするだけでほとんど乗り越えました。 しかし、コンポーネントに分解してから、データセンターに転送し、単独でマウントしました。 スライドの取り付けには多数のネジをねじ込む必要があるため、ドライバーで「G」の文字の位置に多くの時間を費やさなければなりませんでしたが、接続は満足です-必要かつ十分な長さのケーブルはすべて簡単に挿入および取り外しできますが、偶発的な引き出しに対する保護があります (この事実は、別のフラッシュストレージシステム(バイオリン)をテストした後に明確に記録されました。何らかの理由で、2つの隣接するソケットを接続するケーブルの長さは1.5メートルであり、挿入されたイーサネットパッチコードの1つは、ドライバーなどの追加のフラットツールなしで引き抜くことができません) 。
特別に訓練されたエンジニアがこのテーマを設定するために来ました。 現在、管理ソフトウェアの更新がデータ損失を伴って行われていることを知ることは非常に興味深いことでした。 システムへの新しいブリックの追加も同じです。 2台のディスクを一度に離すと、データが失われます(損失なしで、再構築後に2番目のディスクが失われる可能性があります)が、次の更新で修正することを約束します。 私に関しては、最初の2つのポイントが通常の方法で行われた方が良いでしょう。
アレイを完全に構成および管理するには、システムに専用サーバー(XMS-XtremeIO Management Server)が必要です。 キットへの物理的な追加として注文することもできます(このサーバーに相当する金の価格でソリューションのコストを増やすことで考える)、またはテンプレートから仮想ボックス(Linux)を展開することもできます。 次に、ソフトウェアを含むアーカイブを配置してインストールする必要があります。 そして、半ダースのデフォルトアカウントを使用してセットアップします。 一般に、初期構成プロセスは、ストレージシステムの通常の構成とは異なり、安心の方向ではありません。 さらに発展することを願っています。
悪用、重複排除、および問題の状況
さらに苦労することなく、彼らは戦闘VDIの一部をテストとしてテスト対象デバイスに転送し、何が起こるかを確認することにしました。 重複除去の有効性に特に興味があります。 完全なクローン、プロファイル、および一部のユーザーデータはVM内にありますが(ボリュームはほとんどの場合OSに比べて小さいですが)、宣言された奇跡には懐疑的であるため、10:1の係数は信じていませんでした。
転送された最初の36個のVMは、データストアで1.95 TB、ドライブで0.64 TBを使用しました。 重複排除率は2.7:1です。 確かに、最初のバッチは、IT部門の代表者の仮想デスクトップで構成されていました。特に、PC内のすべてを保持するのが好きで、物理的か仮想的かは関係ありません。 多くの場合、追加のドライブもあります。 システムが新しいマシンでいっぱいになると、係数は大きくなりましたが、大きくはなりませんでした。 数百の仮想マシンを備えたシステムのスクリーンショットの例を次に示します。
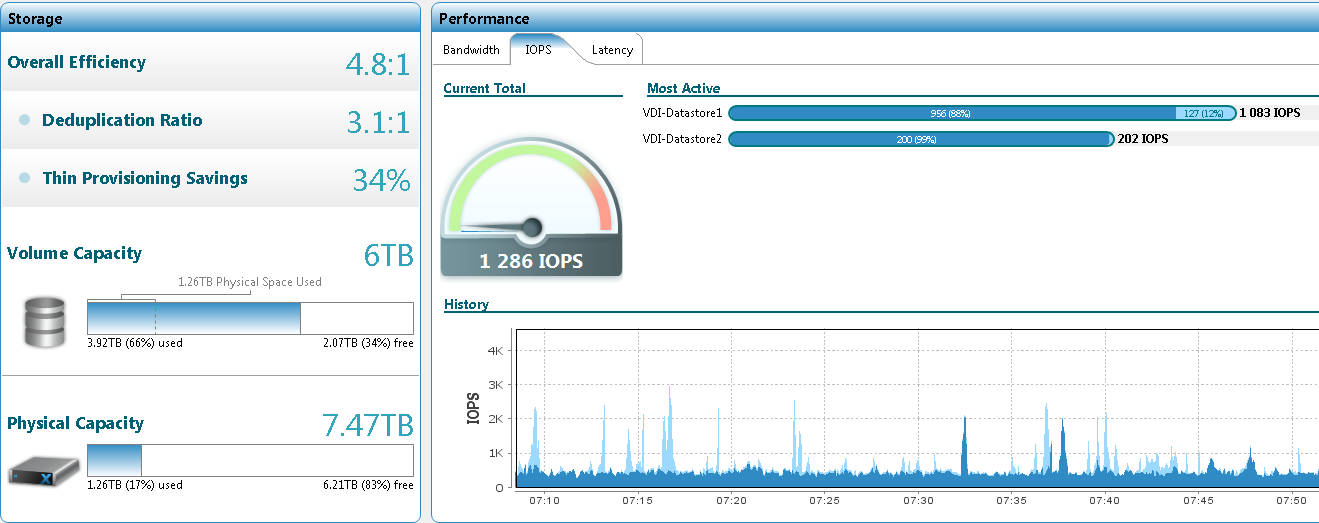
そして、これは450です:

vmdkの平均サイズは43 GBです。 内部はWindows 7 EEです。
この量に基づいて、新しいテストを停止してクランクアップすることにしました。新しいデータストアを作成し、テンプレートから新たにデプロイされた「クリーンな」クローンを使用して、デプロイ時間と重複をチェックします。 結果は印象的です。
100個のクローンが作成されました。
データストアに4 TBが入力されました。
ディスク容量の使用量が10 GB増加しました。
スクリーンショット(以前と比較):
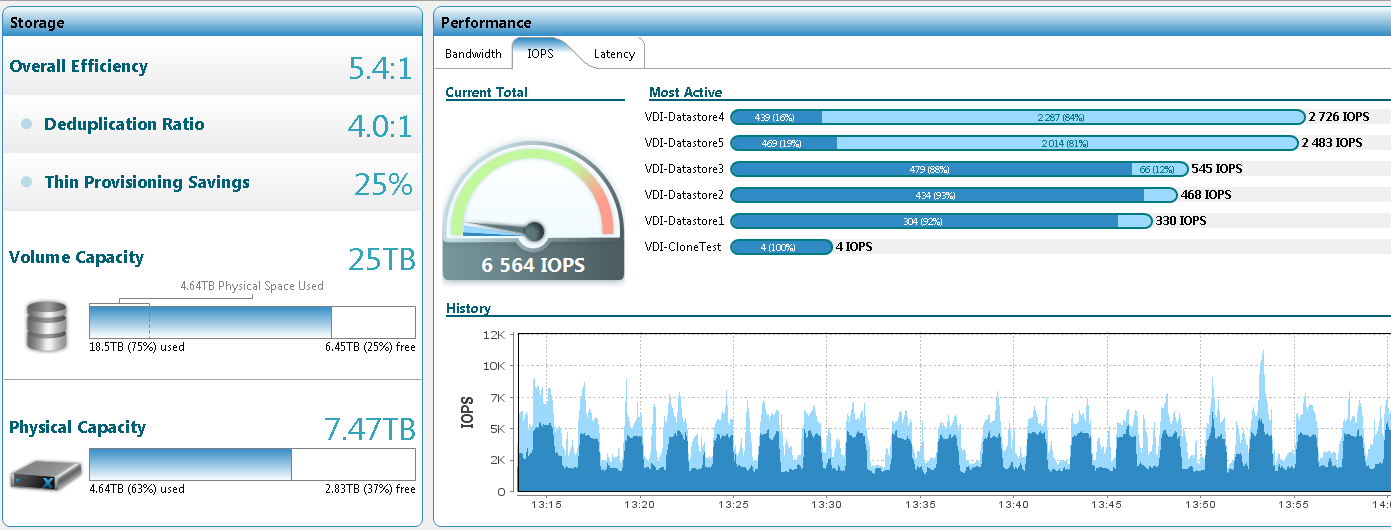
完全な結果プレートは次のとおりです。
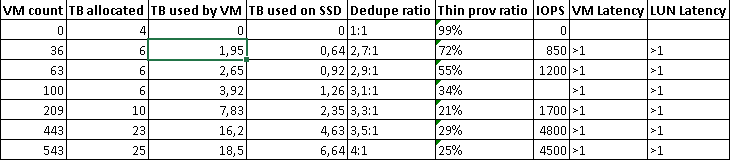
これらの100個のクローンを含めて、a)ブートストームでのシステムの動作、b)電源を入れた後の重複除去係数の変化、およびクリーンシステムのある時間を確認するというアイデアがまだありました。 しかし、起こったことは不快な行動と呼ばれる可能性があるため、これらの活動は延期する必要がありました。 5つのLUNの1つがブロックされ、クラスター全体を占有します。
その理由はホスト構成機能にあることを認識する価値があります。 IBM SVCをホストのストレージアグリゲーターとして(間違っているかどうかに関係なく)使用しているため、ハードウェアアシストロックを無効にする必要がありました。これは、メタデータを変更するときにデータストア全体ではなく、その小さなセクターをブロックできる最も重要なVAAI要素です。 なぜLUNがブロックされているのか-当然です。 なぜロックが解除されなかったのか-本当ではありません。 そして、すべてのホストから切断された後でもブロックを解除しなかった理由は完全に理解不能です(これを行っていない間は、1つのVMをオンにしたり移行したりすることはできませんでしたが、運が良ければ、その瞬間に誰かが会社の非常に重要な人々は、自分の車を再構築する必要がありました)、考えられるすべての想像もできないタイムアウトを通過しました。 「古いタイマー」によると、古いIBM DSxxxxでも同様の動作が観察されましたが、そのような場合のために特別なLUNロック解除ボタンがありました。
このボタンはここにはありません。その結果、89人が3時間デスクトップにアクセスできず、アレイを再起動することを既に考えていたため、これを行うための最も安全で信頼性の高い方法を探していました(コントローラーを1つずつ再起動しても解決しませんでした)。
ヘルプはEMCサポートによってサポートされていました。EMCサポートは最初、適切なエンジニアを腸から長い時間連れて行き、次にすべてのタブとコンソールを再確認して調べました。ソリューション自体はシンプルでエレガントでした。
vmkfstools --lock lunreset /vmfs/devices/disks/vml.02000000006001c230d8abfe000ff76c198ddbc13e504552432035
つまり、任意のホストからのロック解除コマンドです。
生きて学びます。
来週、私は必死にデスクトップをHDDストレージに戻し、後の時間があればすべてのテストを延期しました。 次のテスターがモスクワにいなかったので、配列が約束された時間よりも2日早く私たちから奪われたため、時間がありません、ウファ(復帰手続きの突然性と組織は完全に規範的ではない別個の価値があります)。
まとめ
イデオロギー的に、私は解決策が好きでした。 ユーザーデータをファイルサーバーにアップロードしてVDIインフラストラクチャをわずかに終了する場合、70 TBのすべてを1つではなく、2つまたは3つのBRIKに配置できます。 これは、ラック全体に対して12〜18ユニットです。 もちろん、svMotionの速度とクローンの展開は好きではありません(1分未満)。 しかし、まだ湿っています。 更新およびスケーリング中のデータの損失は、企業では受け入れられるとは見なされません。 また、予約ロックの瞬間も恥ずかしかったです。
一方、それは何とか未完成のNutanixのように見えます。 後者はプレゼンテーションによってのみ評価できますが、常に美しいものです。
そして価格について。 CROCは彼の投稿で、2800万という理解できない数字について書いています。 私は6年半ほど聞いたが、これは最小限ではなかった。 私は現在、価格交渉へのアクセスも関心も持っていませんが、確かに言うことを約束しません。