
こんにちはHabr! そしてここにまた来ました! 私たちは私たちの道でしばしば会った多くの懐疑論者を無視して、Tod Bot Robotプロジェクトの開発を続けています。 この投稿は、マニピュレーター制御ツールとしてのMoveItモジュールの紹介の続きです。
まず、マニピュレーターを介してオブジェクトをキャプチャおよび移動するタスク、およびオブジェクトを認識するタスクで重要な結果を達成できたと言いたいのですが、まず最初に。
MoveItでのキャプチャに関する少しの理論
物体の捕捉は、マニピュレーターの初期位置から直接物体を持ち上げるまでの、実行準備の整った完全な軌道を計算するいくつかの段階で構成されるコンベヤーの形で表すことができます。 これらの計算は、次のデータに基づいています。
- Planning Scene Monitorが提供するシーン計画ツール
- オブジェクトIDをキャプチャする
- このオブジェクトのブラシキャプチャ位置
後者には、次のデータが含まれます。
- マニピュレーターの「ブラシ」の位置と方向
- このポーズのグラブの成功の予想される可能性。
- マニピュレータの予備アプローチ。これは、ベクトルの方向として定義されます-アプローチの最小/望ましい距離
- キャプチャ後のマニピュレーターのインデント。ベクトルの方向として定義されます-インデントの最小距離
- 最大把持力
システムがコンベアを開始する前に、オブジェクトをキャプチャするブラシの位置の可能なオプションを生成する必要があります。 この例では、キャプチャされたすべてのオブジェクトが長方形であると仮定しています。 したがって、2本の指の形でキャプチャする場合、被写体を確実にキャプチャするための2つのペアのプレーンのみがあり、被写体が立っている上下をカウントしません。 これによれば、キャプチャ位置は、1組のプレーンと別のプレーンの半球の形で生成されます。
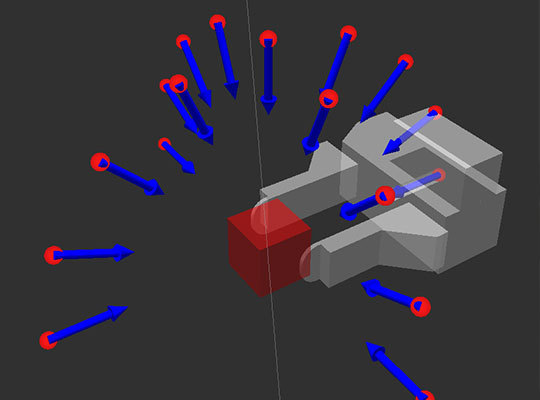
得られた多くの可能なポーズの中で、グリップ/ブラシの形状を満たさないポーズを取り除き、残りのポーズをコンベヤに転送して、これらのポーズを達成する軌道をさらに計画する必要があります。
対象物を持ち上げるコンベヤには、3つの主要なポイントがあります。

1-開始位置。 2-事前キャプチャの位置。 3-位置キャプチャ。
コンベアの実行中に、個々の軌道がアイテムを上げるための最終計画に追加されます。 キャプチャがすべての段階を正常に完了した場合は、計画を実装できます。 一般的なパイプラインアルゴリズムは次のようになります。
- 軌道は、初期位置からプリキャプチャポイントまで計画されます。 滑走路に着陸する飛行機を例にとると、着陸アプローチになります。
- すべての環境オブジェクトは、最初に衝突マトリックスに含まれていました。これについては、 ここで説明しました 。 キャプチャを成功させるために、衝突チェックは無効になっています。 次に、グリップが開きます。
- プレキャプチャポイントからキャプチャポイントまでのオブジェクトへのマニピュレータのアプローチの軌跡が計算されます。
- グリップが閉じます。
- キャプチャされたオブジェクトは、まだ衝突オブジェクトによって表されているため、キャプチャの一部になり、軌道を計画するときに考慮されます。
- 次に、オブジェクトを表面から引き裂き、オブジェクトを持ち上げた結果を固定するために、キャプチャ位置からプリキャプチャポイントまでのインデントパスが生成されます。
これで、必要なすべての軌道を含む構築された計画を完了できます。
まだ言われていないこと
実験に入ると、最初の4つの自由度にさらに2つ追加することにしました。 ビデオと写真では、それらは赤で示されています。 これは、フォークまたは擬人化されたブラシの形のグリッパーを使用する場合、マニピュレーターの良好な柔軟性が必要であるという事実によるものです。 ところで、真空吸引カップをグリップとして使用する場合、すべてがいくらか単純化され、4自由度で十分かもしれません。 キャプチャには1つのプレーンのみが使用されます。
実際、キャプチャする機能は、キャプチャ位置の生成に大きく依存します。生成される位置が多様になるほど、最適な位置を選択しやすくなります。 これにはすべてコインの裏返しがあります。ポジションが多いほど、処理に時間がかかります。 この場合、最初の10、34ポジション、次に68、136のポジションを生成しました。私たちに合った最適なオプションは34ポジションでした。 最小数の位置では、マニピュレーターが生成されたポーズになることは非常に困難です。原則として、マニピュレーターは単に物理的に到達することはできません。 34では、すべての条件を満たす2〜5のポジションがあります。
物体認識
これらの目的のために、ROSノードtabletop_object_detectorを使用することにしました。 これはブリティッシュコロンビア大学の科学者によって実装され、すでに確立されています。 私の意見では、システムの選択は、認識を適用する条件と、識別する必要のあるオブジェクトに直接依存する必要があります。 この場合、認識はオブジェクトの形状に従って実行され、キュウリの缶とトマトの缶を区別する必要がある場合、この方法は機能しません。 オブジェクトを識別するために、Kinectから取得した深度カメラデータが使用されます。
認識する前に、まずシステムをトレーニングする必要があります-目的のオブジェクトの3Dモデルを作成します。

プリングルズのパックの3Dモデル
その後、システムは受信したデータをデータベースで利用可能なモデルと比較します。
認識結果は次のようになります。

予想どおり、オブジェクトの検索速度は、データが処理されるマシンの能力に直接依存します。 Intel Core 2 Duo 1.8ghzと3Gb RAMを搭載したラップトップを使用しました。 さらに、オブジェクトの識別には約1.5〜2秒かかりました。
もちろん、環境からオブジェクトを区別して識別できるようになったので、今度はそれらを取得して移動したいと思います。 次のステップは、認識タスクとマニピュレーター制御を実際のロボットに統合することです。