このようなアプローチにより、同じ情報ニーズで訪問されたサイトのグループを識別することができます。 ただし、このような単純なセグメンテーションの品質が制限されていることは明らかであるため、より複雑なアルゴリズムを使用してより良い品質を実現できます。 このレポートは、ユーザーアクティビティを論理セグメントに自動的に分割する問題に専念します。 入手可能な情報に基づいて、私たちは情報ニーズに基づいて彼らの日常活動を自動的にグループに分割する方法を提案します。 いくつかのセグメンテーション方法について説明し、それらの有効性の比較分析を行います。 提案されたアルゴリズムは、タイムアウトに応じた分離に基づく方法よりも大幅に優れています。
ブラウザ、検索エンジン、または特定のサイトでのユーザーアクティビティは、有用な情報の豊富な情報源です。リクエストの再編成、リクエストの前後の移動/ポータルへの訪問。 残念ながら、この情報は構造化されておらず、非常にノイズが多くなります。 主なタスクは、生データの処理、構造化、および精製です。 ユーザーアクティビティを論理的に関連するコンポーネントに自動的に分割する方法を提案したいと思います。
ユーザーは、検索エンジンとブラウザーと継続的に対話します。
- 要求を設定します。
- 問題の文書をクリックします。
- 発行の新しいページを要求します。
- ブラウザのリンクとナビゲーションボタンを使用してページ間を移動します。
- タブを切り替えます。
- ページをスクロールし、マウスでそれらをリードします。
- 他の検索エンジンに行きます。
これらのイベントをアトミックに考慮するだけでなく、ユーザーを駆動するものをよりよく理解するために結合することを学ぶことも重要です。 ある出来事が別の出来事を導き、それらを結びつけることを学べば、何がユーザーを動かしているのかをよりよく理解することができます。
ユーザーセッションの調査に関連して、いくつかのタスクが発生します。
- 論理セッションの境界の決定。
- セッションの次のアクションの予測。
- セッション情報を取得して、次のアクションを支援します。
- 1つのセッションでのユーザーアクションのモデリング。
- セッション中の隠されたデータの評価-情報の必要性、セッションに対する満足度、疲労。
次に、いくつかの定義を定式化し、いくつかの表記法を導入する必要があります。 私のストーリーの主人公であるブラウザセッションは、日中にユーザーがアクセスする一連のページです: D u- (d 1 ....... d n ) 。 セカンダリオブジェクト-リクエストセッション-1日以内にユーザーが指定した一連のリクエスト: Q u- (q 1 ....... q n ) また、論理的なブラウザセッション(および論理的なリクエストセッション)-同じ情報ニーズgでアクセスされた論理的に接続されたページで構成されるブラウザセッションの一部を強調したい場合もあります。
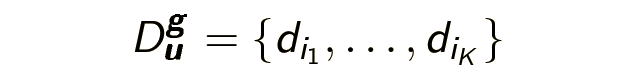
ユーザーセッションが何であるかの例を考えてみましょう。
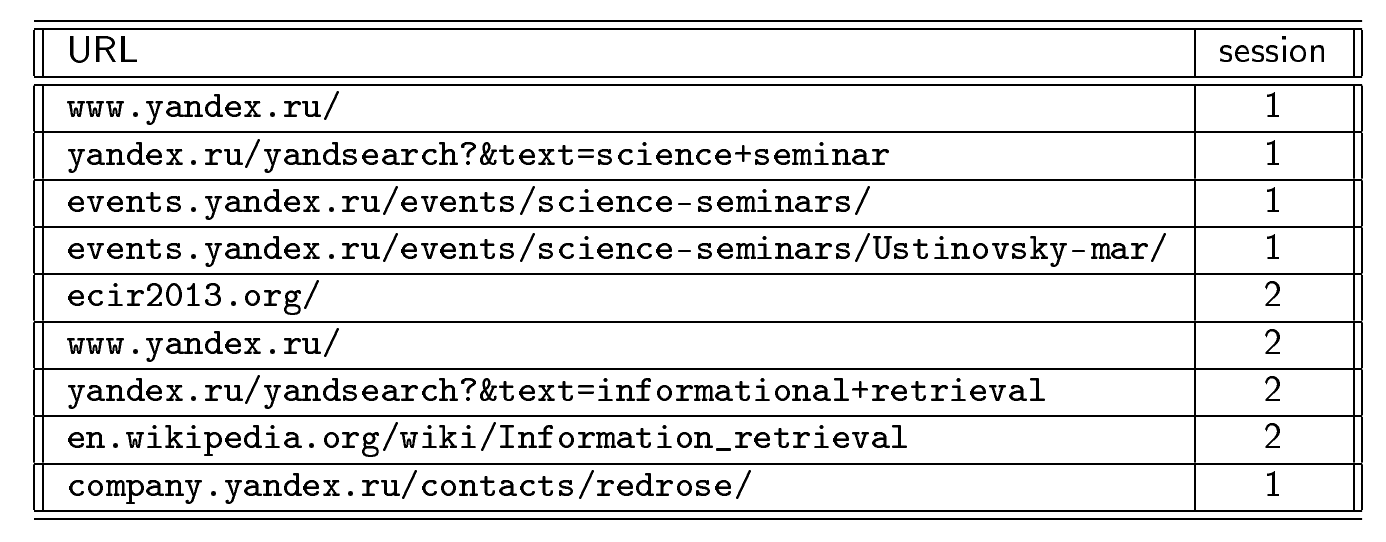
ユーザーは検索エンジンのページに移動し、科学セミナーに関する情報の検索を開始し、すべてのYandexセミナーのリストを含むページに移動し、3月28日に興味深いレポートがあることを知り、彼の発表を読みました。 突然、彼は発表で彼に知られていない概念に気づき、それが何であるかを見たかった。 彼はサイトecir2013.orgへのリンクをたどります。 この時点で、彼の情報ニーズは変わりました。最初はセミナーに関する情報を見たいと思っていましたが、今では会議に興味を持つようになりました。 会議のメインページを見ると、彼は別の未知の概念-情報検索を見つけました。 彼は再び検索エンジンに行き、そこでクエリを入力します[情報検索]。 検索で、彼はウィキペディアでページを見つけ、それについて読み、このトピックに興味があると判断し、Yandexポータルに戻ってセミナーの開催場所を確認します。 元の論理セッションに戻ります。
もちろん、これは人為的な例ですが、論理セッションのいくつかの重要な機能をトレースできます。
- 原則として、論理セッションはインターリーブされます。
- 一部のページは、いくつかの論理セッションに参加しています。
- ユーザーの要件は、リクエストが行われる前に変更されます。
少し脱線し、クエリセッションを見て理解できること、つまりユーザーに関する情報を抽出できることを見てみましょう。 必要な情報がすぐに見つからない場合、ユーザーは同じトピックに対して異なるクエリを要求できます。 しかし、答えが検索結果の最初のページ、2番目、3番目などにない場合、どのように動作しますか グラフには、さまざまな長さのリクエストセッションのデータが表示されます。
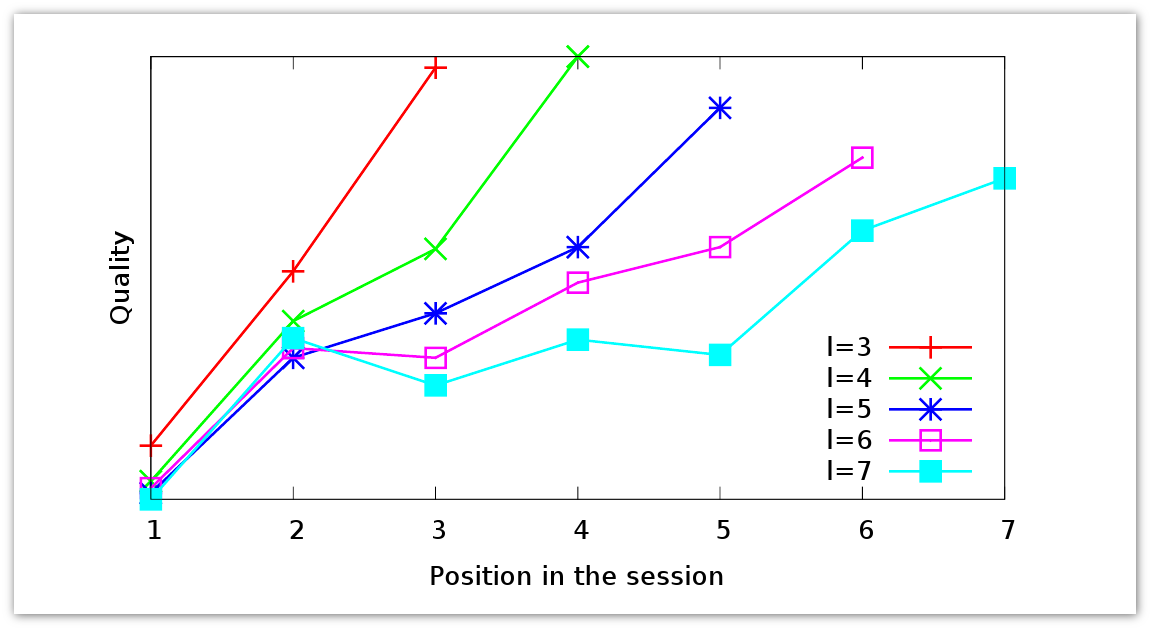
赤は、3つの要求の長さを持つ要求セッションを示します。 セッション中に、応答の品質が向上していることがわかります。 ユーザーは、より良い回答を作成します。 同じ傾向は、より長いセッションでも見られます。 ユーザーがリクエストの文言をどれだけ長く変更しなくても、平均して配信の品質は向上します。 ユーザーは、リクエストを再構成する最適な方法を理解しています。
通常、 D uは非アクティブ期間τに基づいてセグメント化されます(ここで、 τ(d)はdを開く瞬間です)。 d iとd i + 1はそれぞれ同じセッションに属し、 τ(d i + 1 )-τ(d i )<τです。 これは最も一般的で一般的なアプローチです。 ただし、セッションが互いに点在している場合は機能しないことは明らかです。 ユーザーがこのアプローチの観点からあるトピックに戻ると、それはすでに新しい論理セッションになります。
クエリセッションの論理パーティションのタスクは、次の2つのペーパーで既に解決されています。
- P.ボルディ等。 クエリフローグラフ:モデルとアプリケーション。
- R.ジョーンズ他 セッションタイムアウトを超えて:クエリログの検索トピックの自動階層セグメンテーション。
そこで異なる方法が使用され、異なる目標が追求されましたが、両方の作品の著者は、それらの方法が時間配分を大幅に改善できると主張しています。 このため、ブラウザセッションに最適なアルゴリズムを見つけようと思いました。
私の研究では、いくつかの質問をすることにしました:
- 要求セッションの論理的な内訳をブラウザセッションのレベルまで明確にすることは可能ですか?
- 非アクティブな期間に基づいて、どの程度の品質のパーティション分割がアプローチを提供しますか?
- さまざまなクラスタリングアルゴリズムがセグメンテーションの品質にどのように影響しますか?
- 論理セグメンテーションに重要な要因のソースは何ですか?
方法
使用された生データは、生のブラウザセッション-ユーザーがアクセスした一連のページです。 セグメンテーション自体は2つのステップで構築されます。
- ペアワイズ分類。 ユーザーが1つの目的で2つのページ( d i 、d j )にアクセスしたかどうかを予測します:関数p(d i 、d j )∈ [0; 1]を学習します。これは、1つの論理セッションに属するd i 、d jの確率を推定します。
- クラスタリング p(d i 、d j )のさまざまな推定値について、エッジp(d i 、d j )の重みでN頂点d i上の完全なグラフを強く連結されたコンポーネントにクラスター化します。
その結果、セグメンテーションが発生します。

2つのステップのそれぞれをより詳細に検討してください。 分類から始めましょう。 機械学習では、まず最初に一連の例をまとめる必要があります。 同じ論理セッションに属するかどうかを判断するために、十分な数のペアのセットを手でマークしました。 次に、各評価ペア( d、d ' )について、因子を抽出します
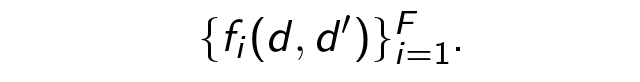
その後、分類器p(d i 、d j )を学習します。
分類器のモデルとして、ロジスティック損失関数を持つ決定木を使用します。 すべてのペアの正しい分類の確率を最大化します。
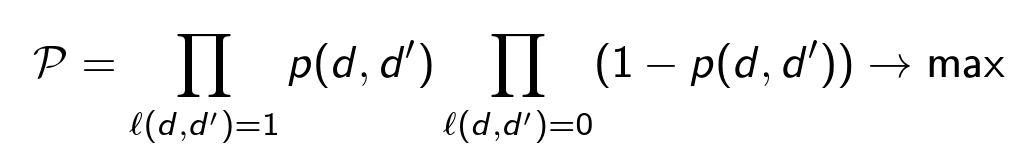
各ペア( d、d ' )について、4種類の因子(合計約29個)を抽出します。
- URLベースの要因。
- テキスト要素。
- セッション要因。 訪問間の時間d、d ' 、それらの間のドキュメントの数、リンクのクリックがあったかどうか。
- コンテキストの一般化。 前の3つの段落と同じですが、 d 'に先行するドキュメントdの計算のみです。
分類が完了し、現在の目標はグラフ全体をクラスター化し、確率を最大化するパーティションを見つけることです( ρの値は固定され、パーティションが変更されます)。
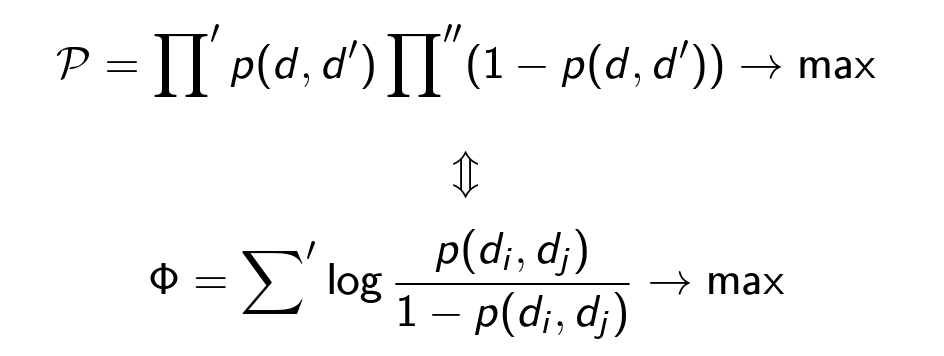
Π '1つのクラスターのすべてのペア( d、d' )の積。
Σは、異なるクラスターのすべてのペア( d、d ' )の合計です。
Π "は、すべてのクラスターのすべてのペア( d、d ' )の積です。
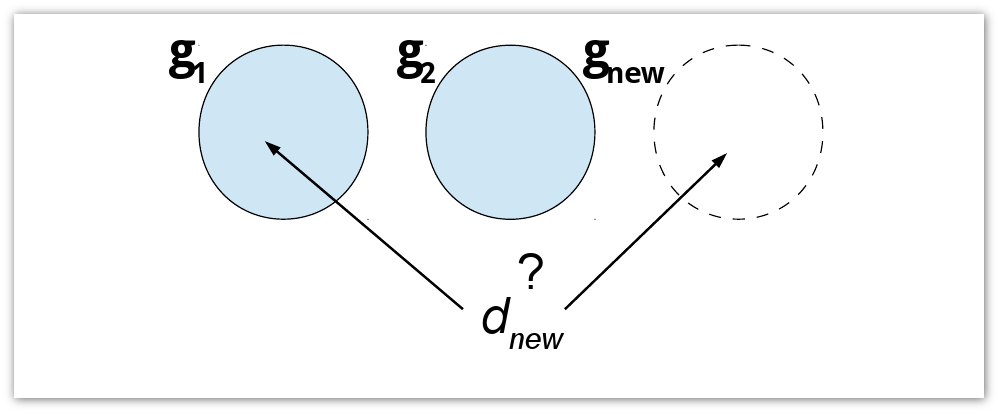
問題の記述は良さそうに見えますが、この形式ではNP完全であることがわかります。 つまり セッションサイズが大きい場合、クラスタリングは非常に計算コストがかかります。 したがって、さまざまな貪欲なアルゴリズムを適用する必要があります。 このタイプの貪欲なアルゴリズムを使用する場合、特定のタスクに対して直接選択する必要がある速度、品質、および範囲のバランスが常に生じます。 すべての貪欲なアルゴリズムを2つの適用領域に分けました。 1つ目はリアルタイムクラスタリングです。新しいドキュメントd newはそれぞれ、現在のクラスターに追加されるか( g 1 、g 2 )、新しいドキュメントを形成します( g new )。
3つの貪欲なアルゴリズムを使用しました。
- 最終ページの最尤。 d gはセグメントgの最後のページです。 すべてのp(d g 、d new ) <1/2、したがって、新しいセッションを開始します。 それ以外の場合は、最大確率でd newをセッションに追加します。
- すべてのページの最尤法。 すべてのp(d、d new ) <1/2であるため、新しいセッションを開始します。 それ以外の場合は、ドキュメントを含むセッションに最大確率でd newを追加します。
- 貪欲な追加。 d newを追加して、 Φの成長を最大化します。 すべてのgについてΦが常に減少する場合、新しいセグメントを開始します。
2番目のタイプのアルゴリズムは、ユーザーの毎日のすべてのアクティビティを一度に処理します。 クラスタリング後を実行します。 このタイプには、 貪欲なマージが含まれます。 Nを作成します-| D u | クラスター。 既存のクラスターを積極的にマージしますが、 Φは増やすことができます。
最初のアルゴリズムの複雑さはO(G×N)です 。ここで、 Gはセグメントの数です。 他のすべてのアルゴリズムにはO(N 2 )の複雑さがあります。
実験
ツールバーを使用して収集された匿名のブラウザベースのログは、生データとして使用されました。 これらには公開ページのアドレスが含まれており、各ページについて、訪問の時間、訪問のソース(リンクがある場合)、ドキュメントのテキスト、およびユーザーがそれらを残したリンク(これが発生した場合)が抽出されました。 トレーニングサンプルの場合、各ブラウザーセッションは評価者によって手動で論理セッションに分割されました。 合計で、220のブラウザー論理セッションと分類子トレーニング用の15万1千のペアがありました。1つのセッションから7万8千、異なるセッションから7万3千です。 論理セッションの平均長は12ページで、ユーザーあたりの1日あたりの論理セッションの平均数は4.4でした。
次の表は、さまざまな要因のセットでトレーニングされた時間パーティションと分類器の品質を示しています。
| 一連の要因 | 一時的な分割 | 全部 | コンテキスト外 | テキストなし |
| Fメジャー | 80% | 83% | 83% | 82% |
| 精度 | 72% | 82% | 81% | 81% |
機械学習プロセスの各要因の貢献度を計算できる方法があります。 次の表に、上位10の要因とその貢献を示します。
| Rk | ファクター | めがね |
| 1 | d 1とd 1の間の時間 | 1 |
| 2 | LCS | 0.58 |
| 3 | LCS /長さ( url 1 ) | 0.40 |
| 4 | LCS /長さ( url 2 ) | 0.40 |
| 5 | #d 1 b d 1の間のページ | 0.33 |
| 6 | URLトリグラムの一致 | 0.32 |
| 7 | コンテキストLCS /長さ( url 1 ) | 0.32 |
| 8 | 単一ホスト | 0.22 |
| 9 | LCS /長さ( url 2 ) | 0.20 |
| 10 | コンテキストlc | 0.20 |
予想どおり、最も重要な要素はドキュメントを訪問する時間です。 また、URLとLCS(一般的なURL部分文字列の長さ)が重要な役割を果たすことも非常に自然です。 役割はコンテキスト要因によって果たされます。 ただし、単一のテキスト要素はありません。
それでは、クラスタリング実験に移りましょう。 アルゴリズムの品質の尺度は、 ランドインデックスに基づいています 。 セットD uの 2つのセグメンテーションS 1 、S 2の場合、等しく対応するドキュメントのペアのシェアに等しくなります。
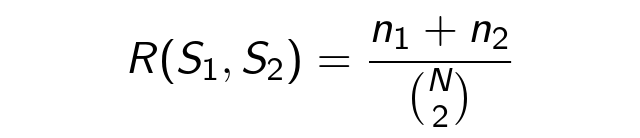
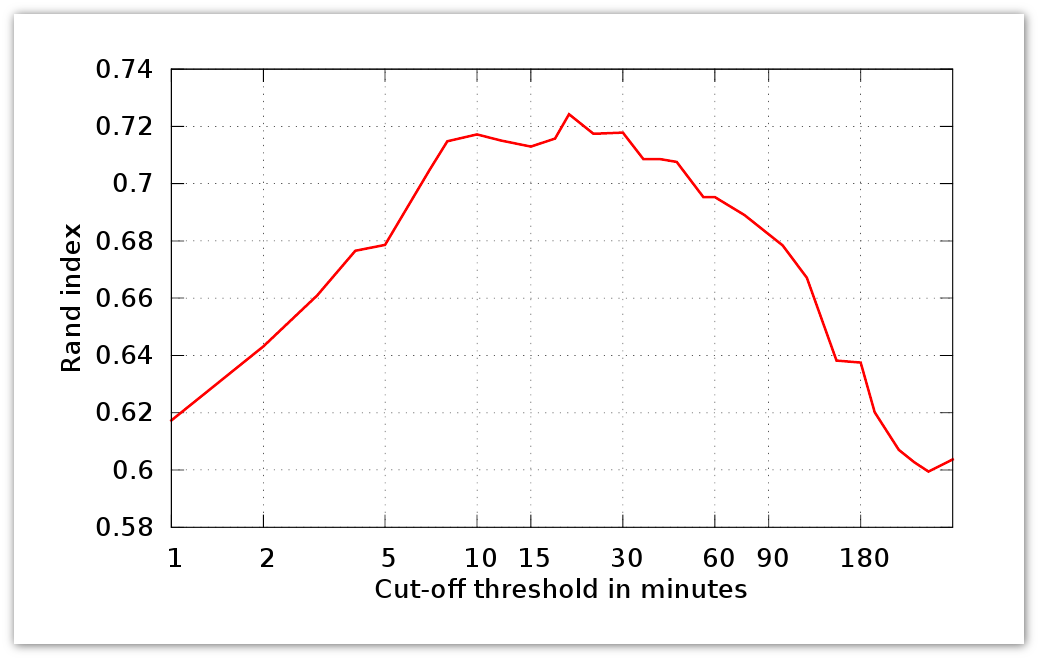
ここで、1つのセグメントS 1 、S 2からのn 1- #ペア 、 D uの 異なるセグメントS 1 、S 2 、 N- #の要素からのn 2- #ペア 。 さらに、 S 1は理想的なセグメンテーションであり、 S 2が推定されます。 R(S 1 、S 2 )は、対応する分類器の精度を表します。 以下のグラフは、 τのアクティビティ期間のランドインデックスを示しています。
次に、上記のアルゴリズムがどのように機能するかを見てみましょう。
| 方法 | ランドインデックス | 難易度 |
| 一時的な | 0.72 | - |
| マックス 最後の可能性 ページ数 | 0.75 | O(N×G) |
| マックス すべてのページの可能性 | 0.79 | O(N 2 ) |
| 貪欲な追加 | 0.82 | O(N 2 ) |
| 貪欲な合併 | 0.86 | O(N 2 ) |
貪欲な合併に対応する分類器の品質(0.86)は、元の分類器の品質(0.82)よりもさらに高くなっています。
結論
- ブラウザログの自動処理方法が提案され、クエリログの分割が明確になりました。
- セグメンテーションの問題を、分類とクラスタリングのよく研究された問題に減らしました。
- タイミングアプローチはかなり優れていますが、より洗練されたクラスタリングアルゴリズムはそれをはるかに上回ります。
- コンテキストおよびテキストの要因は、セッションデータとURLの一致に基づく要因よりも、単一セッション内のページ間の論理リンクを決定するためにはるかに重要ではありません。
Yandexでの次回の科学技術セミナーは6月10日に開催されます。 それは推薦システムと分散アルゴリズムの話題にささげられるでしょう 。