
私のプロジェクトはほぼ準備ができており、プロセスをテストするだけであり、胴体にノッチを付けることができます。
この記事では、私たちのクラスターである「 スレーブ 」の「駆動力」を高めることについて説明し、プロジェクト全体で使用したリソースへの有用なリンクをまとめて提供します 。 おそらく一部の人にとって、記事はソースコードと実装の詳細に乏しいように思えたので、記事の最後にGithubへのリンクを提供します
さて、習慣から、最初に、クラウドにデプロイすることに成功したアーキテクチャの図を示します。
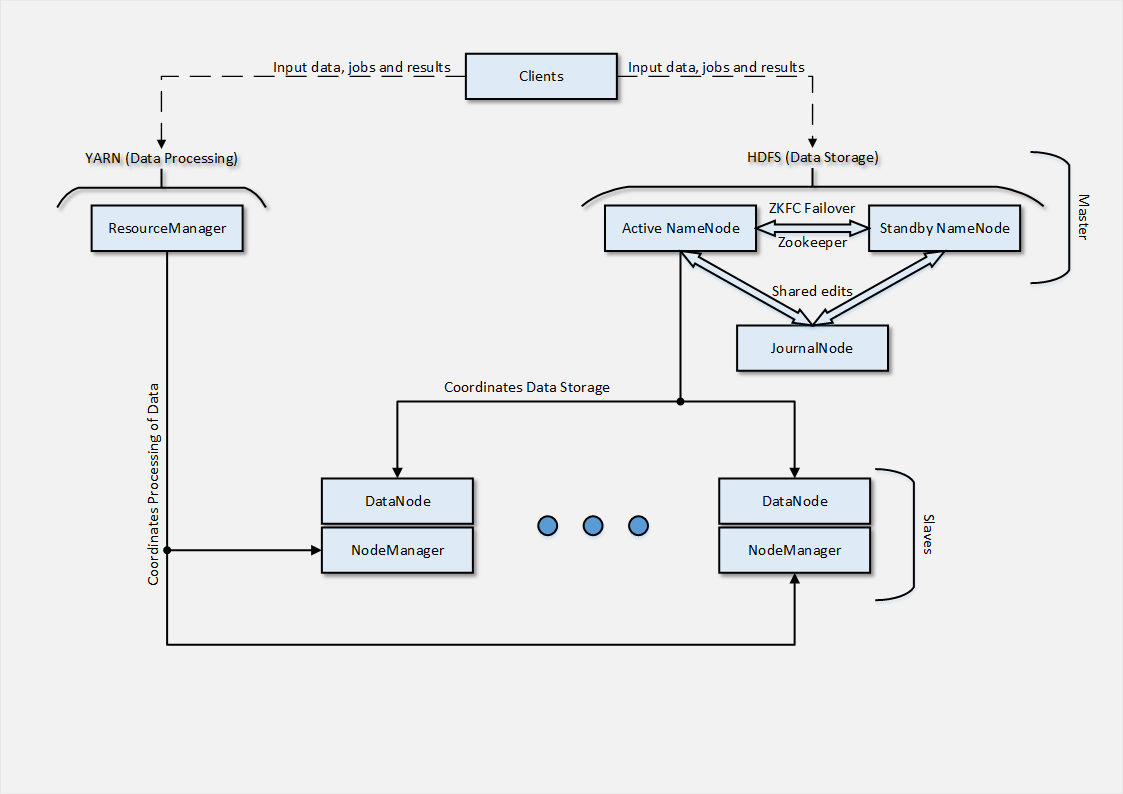
私たちの場合、実行のテストの性質を考えると、2つのスレーブノードのみが使用されましたが、実際の状態ではそれらは数十になります。 次に、展開がどのように編成されたかを簡単に説明します。
スレーブを展開する
アーキテクチャから推測できるように、 スレーブノードは2つの部分で構成され、それぞれがマスターアーキテクチャの部分に関連付けられたアクションを担当します。 DataNodeは、 スレーブノードと、 データの分散ストレージを調整するNameNodeとの相互作用のポイントです。
DataNodeプロセスはNameNodeノードのサービスに接続します。その後、 クライアントはファイル操作でDataNodeノードに直接アクセスできます。 また、データ複製の場合、 DataNodeノードは互いに通信するため、 RAIDアレイの使用を避けることができます。 複製メカニズムはすでにソフトウェアに組み込まれています。
DataNodeをデプロイするプロセスは非常に簡単です。
- Java形式での前提条件の設定。
- Hadoopディストリビューションのパッケージでリポジトリを追加します。
- DataNodeの設定に必要なディレクトリのバックボーンを作成します。
- テンプレートとクックブックの 属性に基づいた構成ファイルの生成
- 配布パッケージのインストール( hadoop-hdfs-datanode )
-
service hadoop-hdfs-datanode start
よるDataNodeプロセスのservice hadoop-hdfs-datanode start
; - 展開プロセスのステータスの登録。
その結果、すべてのデータが正しく構成が適用されている場合、 NameNodeノードのWebインターフェースで追加されたスレーブノードを確認できます。 これは、分散データストレージに関連するファイル操作でDataNodeノードを使用できるようになったことを意味します。 ファイルをHDFSにコピーして、自分で確認します。
NodeManagerは、 ResourceManagerとの対話を担当します。ResourceManagerは 、それらを実行するために使用可能なタスクとリソースを管理します。 NodeManagerのデプロイメントプロセスは、 DataNodeの場合のプロセスに似ていますが、インストールとサービスのパッケージ名が異なります( hadoop-yarn-nodemanager )。
Slaves-ノードの展開が正常に完了した後、クラスターの準備が整ったと見なすことができます。 環境変数 (hadoop_env、yarn_envなど)を設定するファイルに注意する価値があります。変数のデータはクラスターの実際の値に対応している必要があります。 また、このサービスまたはそのサービスが実行されているドメイン名とポートが示されている変数の値の正確さに注意する価値があります。
クラスターの状態を確認するにはどうすればよいですか? 最も手頃なオプションは、 クライアントノードの1つからタスクを開始することです。 たとえば、次のように:
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 5
hadoop-mapreduce-examples-2.2.0.jarはタスク記述ファイルの名前(基本インストールで使用可能)、 piはタスクのタイプ (この場合はMapReduceタスク)を示し、 2と5はタスクの分散パラメーターを担当します(より詳細に- ここ )。
結果は 、すべての計算を実行した後、統計と計算の結果、またはそこにデータの出力を含む出力ファイルの作成とともに端末に出力されます(データの性質と出力の形式は、 .jarファイルに記述されているジョブによって異なります)。
<終了/>
これらはクラスタとパイです、親愛なるHabrazhiteliです。 この段階では-このソリューションに理想的であるふりをしません。 クックブックコードのテストと改善/編集の段階がまだあります。 私は自分の経験を共有し、 Hadoopクラスターを展開する別のアプローチを説明したかったのです。このアプローチは、最も単純でほとんどの正統派ではありません。 しかし、「鋼」が焼き戻されるのは、そのような型破りな状態です。 私の最終目標は、プライベートクラウド向けのAmazon MapReduceサービスの控えめな対応です。
この一連の記事に注意を払って注意を払ったすべての人からのアドバイスを本当に歓迎します(注意を払って質問をしてくれた ffriendに特に感謝します。
素材リンク
約束されたように、ここに私の同僚と一緒にプロジェクトを受け入れ可能な形にするのを助けた資料のリストがあります :
-HDPディストリビューションの詳細なドキュメント-docs.hortonworks.com
-父親のWiki 、 Apache Hadoop-wiki.apache.org/hadoop
-それらからのドキュメント -hadoop.apache.org/docs/current
-少し説明が古いアーキテクチャーの説明記事- ここ
-2部構成の優れたチュートリアル - ここ
-martsenの翻訳チュートリアルを適応-habrahabr.ru/post/206196
-コミュニティクックブック 「 Hadoop 」。これに基づいてプロジェクトを作成しました-Hadoopクックブック
-最後に-謙虚なプロジェクトをそのまま(更新前) -GitHub
ご清聴ありがとうございました ! コメントを歓迎します! 何かお困りのことがありましたら、お問い合わせください またね
UPD。 Habréの記事へのリンク、チュートリアルの翻訳を追加しました。