
この投稿では、以前に行った選択に基づいた単純な提案アルゴリズムについてお話したいと思います。 このために、まず、2つのタスクを実行します。
- 配列からランダムな値を選択
- 値の重みに基づいて配列からランダムな値を選択する
最初の問題を解決するために、多くのPLに既製の関数があることに気付く人は多いでしょう。 ただし、2番目の問題を段階的に解決するために
解決策として、Javascriptにやや似た擬似コードを使用します。 したがって、私のrandom()メソッドは0から1の値を返します。
したがって、タスク1
反復ごとに単純に配列を反復処理して、ランダムにtrue / falseを取得できます
Math.floor(Math.random() * maxNumber)
という形式の一般的なJavascriptソリューションを使用できます。これは、使用するソリューションの短縮バージョンです。
解決策
0から1までの数値の範囲を等しい
n
セグメントで除算し、
random
から最も近い前の値を取得します。
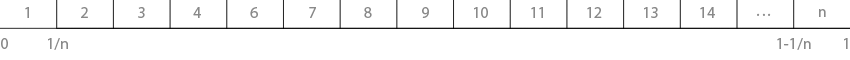
実用部
簡単にするために、独自のインデックスのみを含む150要素の配列を使用します。 つまり、0から150までの数列です。
maxNumber = 150; // elementPart = 100 / maxNumber / 100; // , 0.66% randomResult = random(); cursor = 0; for (i = 0; i <= maxNumber; i++) { cursor += elementPart; if (cursor >= randomResult) { result = i; break; } }
タスク2
初期データをいくつか紹介します。
items = [ {id: 1, score: 4}, {id: 2, score: 0}, {id: 3} ]
score
は特定の値(ポイント数)であり、値の「重み」を他の値よりも先に変更します。 値を選択するか、この値と一度選択した値との類似性に対してポイントを付与できます。 スコアリングのルールは、想像力とアプリケーションの特定の状況によってのみ制限されます。
注意深い読者は、0ポイントがデフォルト値ではないことに気づきました。 これは、選択から値を除外できるようにするためです。そのため、デフォルトのポイント数は1になります。これを行うには、初期データを修正します。
for (i = 0; i < items.length; i++) { item = items[i]; if (item.score === 0) { item.remove(); // continue; } if (item.score === null) { item.score = 1; // score , 1 } }
解決策
ソリューションの本質は、0から1の範囲の値のセグメントを変更することです。
例:

実用部
値の重み計算を追加します。
sumScores = 0; for (i = 0; i < items.length; i++) { // sumScores += items[i].score; } for (i = 0; i < items.length; i++) { weight = items[i].score / sumScores; items[i].weight = weight; }
ここで、重みはすべての要素の合計ポイントの割合です。
重みの合計を計算し、問題1の解決策を確定します。
sumWeights = 0 for (i = 0; i < items.length; i++) { // sumWeights += items[i].weight; } cursor = 0; for (i = 0; i < items.length; i++) { cursor += items[i].weight / sumWeights; if (cursor >= randomResult) { suggestedItem = items[i]; break; } }
したがって、id = 3の場合よりも高い確率でid = 1の値を取得します。ただし、この場合、遅かれ早かれ同じ値が提供されるという結論に達します(ポイント数の増加に応じて)もちろん、サンプルから人為的に除外しない限り)。
このようなソリューションは、ユーザーが最も類似したものを提供する必要があるシステムに非常に適用可能です-スコアを0に設定して、選択した値を除外することを忘れずに、好みの値(同じ色、同じタイプ、おそらく同じメーカー)のスコアを作成するだけです。
セットが必要な場合、同様の製品が表示される可能性は低くなります(たとえば、購入したばかりの場合に2番目の掃除機が必要になるのはなぜですか?)、または選択から購入した商品を落とさずに新しいものを試すことを提案します(たとえば、食べ物や消耗品の注文(電子タバコの香りなど))、重量の計算を少し調整する必要があります:
for (i = 0; i < items.length; i++) { weight = 1 - items[i].score / sumScore; if (items[i].score == sumScore) { weight = 1; } items[i].weight = weight; }
ここで、重量はパーセントの逆数です。
リストにゼロ以外のアカウントを持つアイテムが1つしかない場合、このアイテムに1つのウェイトをチェックして割り当てます。
ここで、この値を選択するたびにスコアにポイントを追加し、それをさらに(選択から除外せずに)移動して、ユーザーに代替オプションを提供します。
これらの2つのアプローチは組み合わせることができます。たとえば、ユーザーに通常購入する製品のメーカーを提供すると同時に、まだ購入していない商品を提供します。
ここでデモを試すことができます。
トピック別
代替の多基準選択とファジー選択のルールについては、 こちらをご覧ください 。