はじめに
見出しの形式でデータを整理することに関する以前の記事(見出しを作成するための基礎としてグラフを使用し、 見出しの作成者を待つ問題 )で、 見出しの整理に関する一般的なアイデアが説明されました。 この記事では、事前に作成された見出しグラフに基づいてテキストの主題を自動的に決定するための可能なアルゴリズムの1つについて説明します。 同時に、アルゴリズムの基礎となるアイデアを可能な限りシンプルにするために、複雑な数式を意図的に避けています。
見出しデータの準備
まず、どの形式でルブリケーターのデータを準備するかを決定します。
- 1.見出しはツリーではなくグラフです
- 2.主題が決定されたテキストは、複数のカテゴリに同時に割り当てることができます。
- 3.見出しとの各相関について、見出しを決定するための精度係数が示されます
- 4.テキストの件名は各テキストに対して個別に決定され、他のテキストの見出しが以前に決定された方法に依存しません
最後のポイントは少し説明が必要です。 テキストの主題の定義の独立性は、結果のその後のソートが必要ない場合に非常に優れています。 テキストが単に分類されるかどうか。 ただし、見出しに複数のテキストがある場合は、見出しに最適な基準で並べ替える必要があるでしょう。 わかりやすくするために、この記事は省略されています。
テキストの主題を簡単に決定するためのアルゴリズム
ルブリケーターについて説明します。 調査中のテキストから、見出しに記載されているキーワードを抽出します。 抽出の結果として、壊れた、ほとんどの場合インコヒーレントなグラフの断片を取得します。 グラフの抽出された部分を「すべて」の最上部に「到達」させるために、ウェーブ(または必要に応じて他の)アルゴリズムを使用します。 結果を分析して表示します。
テキストの主題を詳細に決定するためのアルゴリズム
ルブリケーターの作成については、以前の記事で詳しく説明しました。 この段階では、キーワードが存在するリーフ要素、および節見出しに、作成済みの列見出しがあると考えています。
調査中のテキストの見出しのキーワードセット全体の検索を実行します。 多くの単語を見つける必要がある可能性があるため、特定の実装については、テキスト内の文字列の配列をすばやく検索するためのアルゴリズムを参照することをお勧めします。 まず、最も人気のあるものへのリンクを提供します。
アホアルゴリズム-コラシック
このアルゴリズムの特徴は、ツリーの構築と「戻り値」の処理というかなり複雑なロジックです。実装例は数多くあります。 ハブラーでは、このアルゴリズムの良い説明がありました 。
Rabin-Karpアルゴリズム。 アルゴリズムの特徴的な機能は、非常に大きな単語セットで効果的に機能することです。
原則として、上記で提案した2つのアルゴリズムの説明を読んだ後、それらに基づいて独自の実装を考え出すことは難しくなく、追加条件を考慮することができます。 たとえば、テキストの大文字と小文字の区別、形態の考慮などの要件。
見出しの説明で使用されているキーワードが調査対象のテキストから抽出された後、テキストの主題の決定に直接進むことができます。
波
見出しには「すべて」の頂点があります。 テキストにあるキーワードも存在します。 この段階の目標は、「すべて」のトップで見つかった各キーワードからパスを見つけることです。
キーワード「砂」の場合、見出しの見出しへのパスは次のようになります。
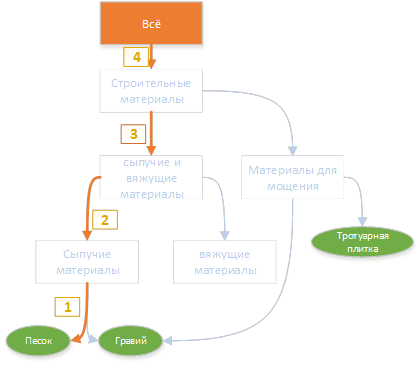
同様に、サミットへのパスは、前の手順で見つかったすべての単語に従って構築されます。
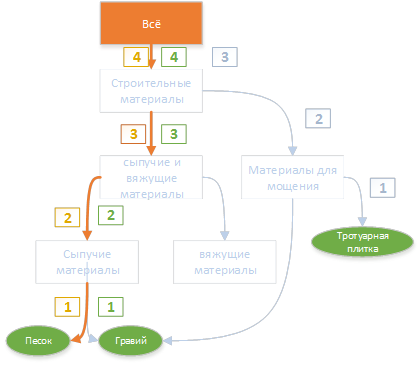
このような構造の結果、各キーワードの上部へのパスが見つかります。
トピックの特定
次に、記事の例を使用して、見出しの自動決定がどのように行われたかを考えてみましょう:「 舗装スラブを敷設する方法は?」 「。 人は、記事を読まなくても、タイルと関連する材料と技術を敷設する可能な方法について話すことを提案するかもしれません。
この記事の自動見出し検出の仕組みを確認します。
伝統的に、記事で見つかったキーワードから始めましょう。見出しに表示があります。
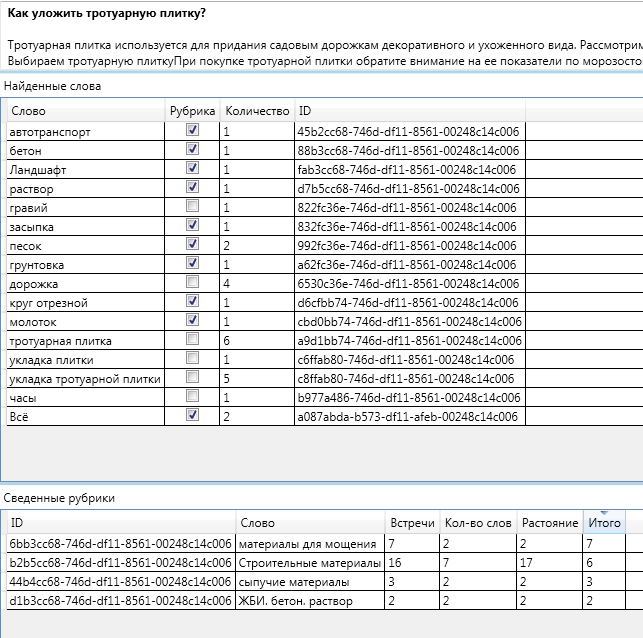
図では、「見出し」マークは、この見出し項目が緑豊かでないことを意味します。 これにより、見出しの名前とそれを説明するキーワードを「組み合わせる」ことができます。
記事「 舗装スラブの敷設方法 」で最も人気のある言葉は、「舗装スラブ」です。これは予想されることです。
以下に、例に含まれていた見出しの一部を示します。
たとえば、キーワード「砂利」は2つのセクションに割り当てられ、キーワード「舗装スラブ」は1つのセクションにのみ割り当てられていることが示されています。 見出しも明るいテキストで強調表示されますが、その名前はテキストでは見つかりません。 (キーワードと見出しに同じ名前を付けることができることに注意してください。詳細は前の記事にあります)。
次に、記事が割り当てられた見出しを見てみましょう。

この記事が割り当てられている最初の見出しは「Paving Materials」という見出しです。
図では、強調表示された行は合計を含む見出しであり、下は各単語のデータを含むプレートです。
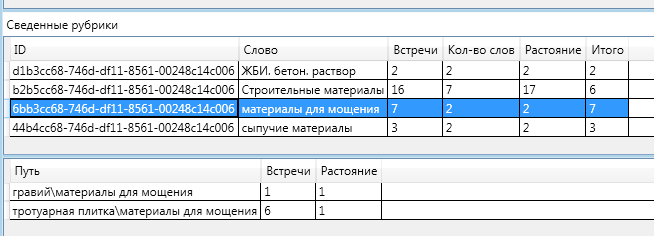
このセクションのメンバーシップの最終評価は7です。これは最高の評価です。 このセクションから、テキストには2つの単語が含まれ、合計距離2で7回です。グラフの2つの頂点間の距離が最短パスのエッジの数であることを思い出してください。
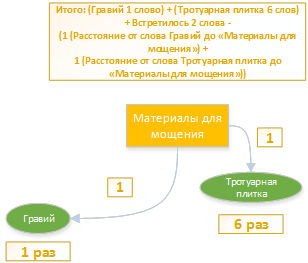
つまり、テキストは「グラベル」というキーワードに1回一致しました。 そして、キーワード「舗装スラブ」を6回。 これらの言葉はどちらも、「舗装材料」というルーブリックに関連しています。
合計:(砂利1単語)+(舗装スラブ6単語)+ 2単語に会った-(1(単語砂利から「舗装材料」までの距離)+
1(「舗装スラブ」から「舗装材料」までの距離))
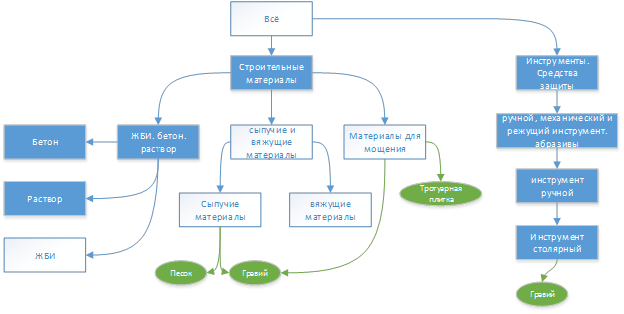
完全を期すために、残りのセクションの情報の図を示します。
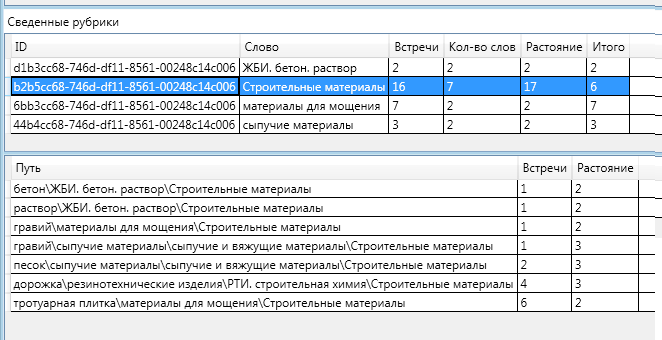
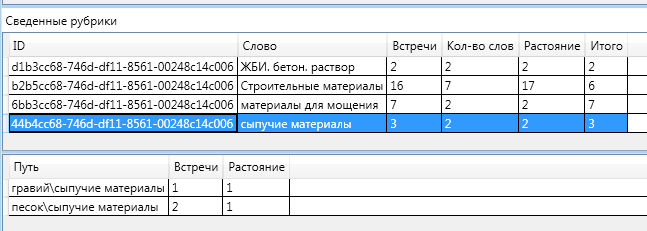
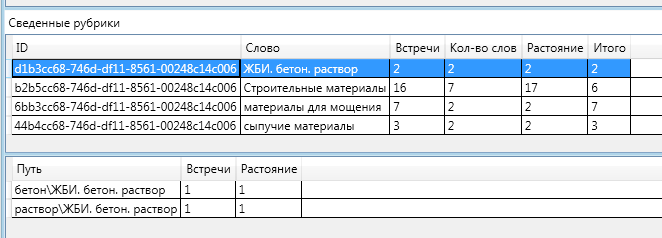
「建築材料」セクションの「途中」に、「バルク材料」と「バルクおよびセメント材料」という2つの見出しがあったという事実に注目するのは興味深いことです。 それらの1つは最終定義に落ち、もう1つはそうではありませんでした。
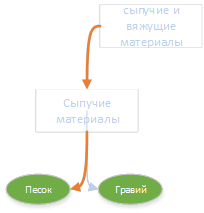
砂と砂利はともに「バルク材料」という見出しに起因します。 「バルク材料」は「バルク材料とセメント質材料」に起因します。 より一般的な(上部)見出しまでの距離は、より具体的な(下部)見出しまでの距離よりも大きく、「合計」の関連性を計算する式により、非常に小さい(負の値まで)ことがわかります。
フォーミュラ
表の「合計」列を決定する式は次のとおりです。
合計=「会議」+「単語数」-「距離」
ミーティング-キーワードが見つかった回数。
単語数-見つかった異なる単語の数。
距離-各単語から選択したカテゴリまでの合計距離。
そして、この公式は根本的な仮定からほど遠い。 そして、確かに、追加の要素などを装備して改善することができます (コメントでこれについて議論することをお勧めします)。
将来を見据えて、このシステムの開発中に、微調整の知恵に混乱しないように、明示的に指定された係数を避けるように特に試みたことに注意してください。
成長ポイント
本質的に、ルブリケーターをすぐに均一にコンパイルすることはできません。 確かに、そのセクションの一部は他のセクションよりも詳細になります。 これにより、グラフの「ゆがみ」が発生し、一方の部分の「上部の葉」からの距離が増加し、他方の部分が大幅に減少する可能性があります。 この不均衡は、グラフの距離の「正しい」計算に悪影響を与える可能性があります。 ここでは、グラフの各ノードの子の数を考慮に入れることができます。

テキストの主題を決定するプロセスを最適化するための2番目の興味深いアイデアは、テキストのさまざまなセクションのトピックを選択的に決定し、その後の結果を構成するというアイデアです。
この考え方は、原則として、記事の冒頭にさまざまなキーワードで満たされた「紹介」セクションがあるという事実に基づいています。次のセクションでは、各章をより確実に分類できる記事のアイデアの改良があります。
他の方法
同じ例が他のオンライントピック決定サービスでどのように見えるかを見るのは興味深いです。
サイトhttp://www.linkfeedator.ru/index.php?task=tematikaは次の結果を提供します。

ウェブサイト: http : //sm.ashmanov.com/demo/

結論
テキストの自動分類見出しのトピックは、検索エンジン、知識処理および抽出システムに非常に関連しています。 この記事が、自動分類の技術を研究し始めたばかりの人だけでなく、これについて複数の犬を食べた人にも役立つことを願っています。
謝辞
最初の2つの記事を読んでフィードバックを共有してくれた人たち、そして個人的に数字のある美しいテーブルを手に入れるためのAndrey Benkovに感謝します。