アリコロニーアルゴリズムの分類への適用は、2002年にR. Parpinelliによって最初に導入されました。 antアルゴリズムに基づいて分類ルールを抽出する方法は、AntMinerと呼ばれます。
メソッドの目的は条件が結果であるならフォームの簡単な規則を得ることです。
すべての属性はカテゴリーであると想定されます。 つまり 用語は、属性=値の形式で表示されます(例:性別=男性)。 AntMinerは、規則の順序付きリストを順番に生成します。 計算は空のルールセットで開始され、最初のルールが形成された後、このルールでカバーされるすべてのテストデータユニットがテストセットから削除されます。
アルゴリズムは、作業時に有向グラフを使用します。各属性は、テストセットで取得する可能な限り多くの頂点にマップされます。 したがって、アルゴリズムが開始する前に、属性のセットとその可能な値、および多くの可能なクラスがテストセットから選択されると想定されます。
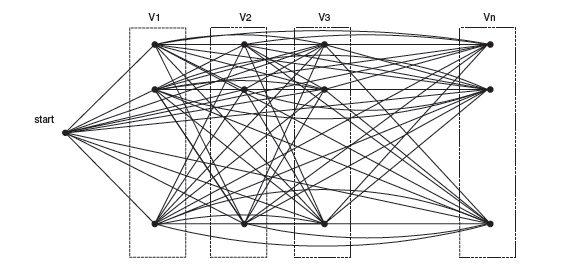
アルゴリズムの擬似コードは次のとおりです。
testSet =テストスイート全体 さようなら(| testSet |> max_number_of uncovered_cases) i = 0; 実行 i = i + 1; i番目のアリは、分類ルールを順番に作成します。 i番目のアリのルールで表されるパスに沿ってフェロモンを更新します。 さようなら(i <Ant_number) すべてのルールの中から最適なものを選択してください。 testSet =最良のルールでカバーされないケース。 サイクルの終わり
アルゴリズムのステップを順番に検討してください。
フェロモン値の初期化
グラフのすべてのエッジは、次の式に従って初期フェロモン値で初期化されます。
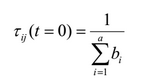
ここで、aは属性の総数、b iはi番目の属性の可能な値の数です。
ルール構築
AntMinerアルゴリズムの各ルールには、前件(属性=値という用語のセット)とそれが表すクラスが含まれます。 元のアルゴリズムでは、ソースデータにはカテゴリ属性のみが含まれています。 用語ij≈Ai = V ijであると仮定します。ここで、A iはi番目の属性で、V ijはA iの j番目の値です。
この用語がアリによって作成された現在の部分ルールに追加される確率は、次の式によって決定されます。
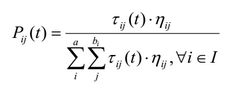
ここで、ηijはヒューリスティック値(後で決定される)、τijはグラフのこのエッジのフェロモン値、Iは現在のアリがまだ使用していない属性のセットです。
発見的
輸送問題を解決するための従来のアリコロニーアルゴリズムでは、次の頂点を決定するために、エッジの重みがフェロモン値とともに使用されます。 AntMinerでは、ヒューリスティックとは情報の量であり、情報理論で使用される用語です。 ここでの品質は、他のルールよりもいくつかのルールを優先するために、エントロピーを使用して測定されます。
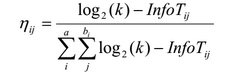
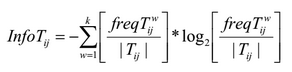
ここで、kはクラスの数、T ijはすべてのデータユニットを含むサブセットです。属性Aiの値はV ij 、| T ij |です。 Tijの要素数、freq(T w ij )はクラスwを持つデータ単位の数であり、属性の総数です。biはi番目の属性の可能な値の数です。
Info T ij値が高いほど、アリが特定の用語を選択する可能性は低くなります。
フェロモン値の更新
各アリがルールの構築を完了すると、フェロモンは次の式に従って更新されます。
τij(t +1)=τij(t)+τij(t).Q∀termij∈現在のルール
ここで、Qはルールの品質であり、次の式で計算されます。
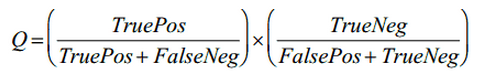
ここで、TruePosはルールでカバーされるデータユニットの数であり、そのクラスはルールで表されるクラスと一致します。FaslePosはルールでカバーされるデータユニットの数ですが、クラスはルールで表されるクラスとは異なります、TrueNegはルールでカバーされないデータユニットの数ですまた、そのクラスがルールで表されるクラスと一致しない場合、FalseNeg-ルールでカバーされないが、ルールで表されるクラスと一致するクラスのデータ単位の数。
蒸発をシミュレートして、フェロモンの再カウントを実行することも必要です。 これは、フェロモンの更新された値を考慮に入れた値の単純な正規化によって実行できます。
フェロモンの更新の改善
アルゴリズムの実行をより柔軟に調整するために、現在のルールに属するエッジの確率を更新するための次の式が使用されます。
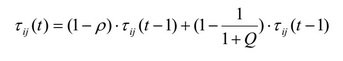
ここで、pは蒸発係数(通常は〜0.1の値が設定されます)、Qは上記のルールの品質です。 現在のルールでカバーされていないRi骨は、単純に正規化されます。 この方法では、低Qでフェロモンが減少し、高Qで増加します(元の方法とは対照的)。
エリートアリ
P = max Pijの項を選択するいわゆる「エリート」アリを導入することにより、アルゴリズムの収束を改善することもできます。
元のアルゴリズムでは、次のアルゴリズムに従って用語選択が選択されます。
FOR ALL(i、j)∈Ji IF q≤∑ Pij THEN termijを選択
ここで、qは一様分布のランダム変数[0..1]です。 つまり 用語の確率密度が使用されます。
エリートアリを導入するために、用語選択アルゴリズムが次のように変更されました。
q1≤ϕ THENの場合 FOR ALL(i、j)∈Ji IF q2≤∑ Pij THEN termijを選択 その他 P = max Pijの用語を選択します
ここで、q 1とq 2は一様分布の確率変数[0..1]です。
いくつかの観察
AntMinerの類似物は、有名なNaive Bayesアルゴリズムです。 彼らの比較に関する私の実験によれば、AntMinerはNaive Bayesよりもわずかに優れているか、さまざまなデータセットでそれよりも劣っています。 比較のため、 ここで紹介したAntMiner実装とWEKAライブラリのNaive Bayes実装を使用しました。 さらに、AntMinerは計算時間が大幅に劣っています。 おそらく、AntMinerが本当に最良の選択である状況またはいくつかの前提条件があります。