 計算を高速化することが必要になる場合があり、すぐに望ましいことがあります。 同時に、便利ではあるが遅いツールをあきらめ、低レベルで高速なものに頼らなければなりません。 Rは、C / C ++、Fortran、またはJavaで記述された動的ライブラリを操作するためのかなり高度な機能を備えています。 習慣から、私はC / C ++を好む。
計算を高速化することが必要になる場合があり、すぐに望ましいことがあります。 同時に、便利ではあるが遅いツールをあきらめ、低レベルで高速なものに頼らなければなりません。 Rは、C / C ++、Fortran、またはJavaで記述された動的ライブラリを操作するためのかなり高度な機能を備えています。 習慣から、私はC / C ++を好む。
RおよびC
すぐに、Debian Wheezyの下で働くことを予約してください(Windowsでは、おそらくいくつかの微妙な違いがあります)。 R for Cでライブラリを作成するときは、次のことを考慮してください。
- Cで記述され、Rで呼び出される関数は、void型である必要があります。 これは、関数が結果を返す場合、関数の引数を通じて結果を返す必要があることを意味します
- すべての引数は参照によって渡されます(ポインターを操作するときは、警戒を怠ってはいけません!)
- Cコードでは、
Rh
とRmath.h
を含めることが望ましい(Rの数学関数を使用する場合)
2つのベクトルのスカラー積を計算する単純な関数から始めましょう。
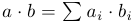
#include <Rh> void iprod(double *v1, double *v2, int *n, double *s) { double ret = 0; int len = *n; for (int i = 0; i < len; i++) { ret += v1[i] * v2[i]; } *s = ret; }
次に、動的ライブラリを取得する必要があります-gccを直接使用するか、このコマンドを使用できます(ちなみに、出力は覚えておく必要があります。これは将来役に立つためです)。
R CMD SHLIB inner_prod.c
出力では、
dyn.load()
関数を使用してロードするinner_prod.soファイルを取得します。 Cで関数自体を呼び出すには、
.C()
使用します
.C()
.Call()
と
.Call()
もありますが、機能がわずかに異なります。また、 .C()と.Call()のサポーター間で議論が白熱する場合があります)。
.C()
を介して呼び出すためにCでコードを記述するとき
.C()
それはよりクリーンで読みやすいことがわかります。 RおよびCの変数のタイプの対応に特に注意を払う必要があります(これについては、
.C()
関数のドキュメントで詳しく
.C()
しています)。 Rのラッパー関数:
iprod <- function(a, b) { if (!is.loaded('iprod')) { dyn.load("inner_prod.so") } n <- length(a) v <- 0 return(.C("iprod", as.double(a), as.double(b), as.integer(n), as.double(v))[[4]]) }
これで、私たちが達成したことを確認できます。
> n <- 1e7; a <- rnorm(n); b <- rnorm(n); > iprod(a, b) [1] 3482.183
そしてちょっとしたチェック:
> sum(a * b) [1] 3482.183
いずれにせよ、彼は正しいと思う。
RおよびCUDA
Nvidia Graphics AcceleratorがDebianで提供するすべての利点を活用するには、Nvidia独自のドライバーと
nvidia-cuda-toolkit
パッケージが
nvidia-cuda-toolkit
ている必要があります。 CUDAは確かに別の巨大なトピックに値します。このトピックのレベルは「初心者」なので、曲がった不完全なコードで人々を怖がらせることはありませんが、マニュアルから数行をコピーさせてください。
ベクトルの各要素を3乗して、結果のベクトルのユークリッドノルムを見つける必要があるとします。

GPUでの作業を容易にするために、
Thrust
並列アルゴリズムライブラリを使用します。これにより、低レベルのCUDA / C操作から抽象化できます。 この場合、データはいくつかの標準アルゴリズムが適用されるベクトルの形式で表示されます(要素ごとの演算、縮約、接頭辞合計、ソート)。
#include <thrust/transform_reduce.h> #include <thrust/device_vector.h> #include <cmath> // , 6 GPU (device) template <typename T> struct power{ __device__ T operator()(const T& x) const{ return std::pow(x, 6); } }; extern "C" void nrm(double *v, int *n, double *vnorm) { // , GPU, *v thrust::device_vector<double> dv(v, v + *n); // Reduce- , .. power // . *vnorm = std::sqrt( thrust::transform_reduce(dv.begin(), dv.end(), power<double>(), 0.0, thrust::plus<double>()) ); }
ここで
extern "C"
使用
extern "C"
必須です。そうでない場合、Rはnrm()関数を認識しません。 次に、nvccを使用してコードをコンパイルします。 コマンド
R CMD SHLIB...
の出力を覚えてい
R CMD SHLIB...
か? CUDA / Thrustを使用するライブラリを問題なくRから呼び出すことができるように、その一部を以下に示します。
nvcc -g -G -O2 -arch sm_30 -I/usr/share/R/include -Xcompiler "-Wall -fpic" -c thr.cu thr.o nvcc -shared -lm thr.o -o thr.so -L/usr/lib/R/lib -lR
出力では、DSO thr.soを取得します。 ラッパー関数は実質的に違いはありません:
gpunrm <- function(v) { if (!is.loaded('nrm')) dyn.load("thr.so") n <- length(v) vnorm <- 0 return(.C("nrm", as.double(v), as.integer(n), as.double(vnorm))[[3]]) }
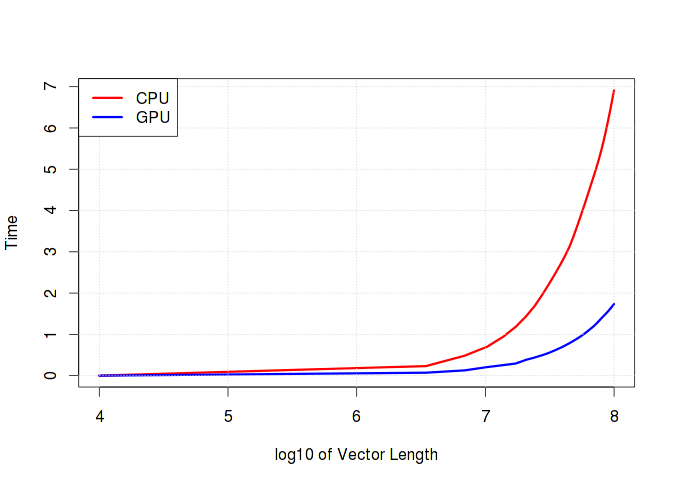
以下のグラフは、ベクターの長さに応じてランタイムがどのように成長するかを明確に示しています。 計算で加算/減算などの単純な操作が優先される場合、CPUとGPUの計算時間に実質的な違いはないことに注意してください。 さらに、メモリを操作するオーバーヘッドのためにGPUが失われる可能性が非常に高くなります。
非表示のテキスト
gpu_time <- c() cpu_time <- c() n <- seq.int(1e4, 1e8, length.out=30) for (i in n) { v <- rnorm(i, 1000) gpu_time <- c(gpu_time, system.time({p1 <- gpunrm(v)})[1]) cpu_time <- c(cpu_time, system.time({p2 <- sqrt(sum(v^6))})[1]) }
おわりに
実際、Rでは、行列とベクトルを操作するための操作が非常に最適化されており、日常生活でGPUを使用する必要はほとんどありませんが、GPUによって計算時間が大幅に短縮される場合があります。 CRANには、GPUでの作業に適した既製のパッケージ(
gputools
)が既にあります(詳細については、 こちらをご覧ください)。
参照資料
1. Rへの.Cインターフェイスの紹介
2. RおよびMatlabでのC関数の呼び出し
3. R用のCUDA C拡張機能の作成
4. Thrust :: CUDA Toolkitドキュメント
PS私はvirdの推奨に従って最初のコードフラグメントを修正しました。