(1 = true AND (2 < 100)) OR (1 = false AND (3 > 17)) ... AND\OR
そのような機能の典型的な例はhotline.ua/computer/myshi-klaviaturyです

MySQL + Symfony2 / Doctrineのフレームワークですべてを実装していますが、速度は不十分です-回答は1〜10秒以内に形成されます。 このすべての経済を最適化しようとする私の試みは、削減されています。
商品をフィルタリングするタスクの用語(簡略化された形式)
- 特性 -商品の特定のプロパティ。 たとえば、メモリの量。
- 製品テンプレート -同様の製品の考えられるすべての特性のセット、たとえばコンピューターマウスの考えられる特性のリスト。 新しい製品を追加するとき、管理者はテンプレート内の特性を選択できます。 1つの製品に新しい特性を追加することはできません。この製品のテンプレートに特性を追加する必要があります。 同時に、このテンプレートを使用するすべての製品でこの機能を使用できます。
- 製品グループ -1つのテンプレートに基づく製品。 たとえば、コンピューターのマウス。 フィルタリングは、1つのグループの製品に対してのみ行われます。
- 基準 -商品の特性に関する一連の正式な要件で構成される論理ルール。 たとえば、「ゲーミングマウス」は、一連のパフォーマンス要件(サイズは小型ではありません)AND(レーザーセンサー)AND(少なくとも1500のセンサー解像度)です
- フィルター -類似製品の基準のグループ。 基準に応じて、ANDまたはORで結合できます
Hotlineには、より高度なバージョンがあります-基準の有効化後に残っている製品の数を示すヒントがあります。 たとえば、「Bluetooth」フィルターを選択した場合、ページを読み込んだ後、「マウスセンサータイプは光学」フィルターの番号は17になります。その活性化。
この問題を解決するために、 Neo4jグラフデータベースを試してみることにしました。 表面的なレビューについては、 この投稿を読むことをお勧めします。
Neo4jの用語と一般的なグラフデータベース。
- グラフデータベース 、 グラフデータベース -グラフ上に構築されたデータベース-ノードとそれらの間の関係
- Cypher -Neo4jデータベースにクエリを書き込むための言語(おおよそ、MYSQLのSQLと同様)
- node 、 node-データベース内のオブジェクト、グラフノード。 ノードの数は、2の350〜340億乗に制限されています。
- ノードラベル 、 ノードラベル -条件付きの「ノードタイプ」として使用されます。 たとえば、映画タイプのノードは、俳優タイプのノードに関連付けることができます。 ラベルノードでは大文字と小文字が区別され、間違ったレジスタに名前を入力してもCypherはエラーを生成しません。
- 関係 、 通信 -2つのノード間の接続、グラフの端。 債券の数は、2の35〜34億乗に制限されています。
- relation identirfier 、 接続のタイプは接続の Neo4jです。 リンクタイプの最大数は32767です
- プロパティ 、 ノードプロパティ - ノードに割り当てることができるデータのセット。 たとえば、ノードが製品の場合、ノードのプロパティにMySQLデータベースの製品IDを保存できます
- ノードID 、 ノードID-ノードの一意の識別子。 デフォルトでは、結果を表示すると、このIDが表示されます。 Cypherリクエストで使用する方法が見つかりませんでした
問題を解決するためのスキーム
製品ごとに個別のノードを作成し、ノードのプロパティでMySQLデータベースに製品IDを保存します。 各基準について、独自のノードを作成し、プロパティに基準のIDを保存します。 次に、商品のすべてのノードを、商品に適した基準のノードに関連付けます。 製品の特性または基準プロパティを変更する場合、ノード間の関係を更新します。
最初の解決策はNeo4jを使用することです
グラフデータベースで作業したことがないことを考慮して、Neo4jをローカルに展開し、Cypherを基本レベルで学習し、必要なロジックを実装することを決めました。 すべてうまくいけば、それぞれが500の特性を持つ100万の製品のデータベースの作業速度をテストします。
システムの展開は非常に簡単です- 配布キットをダウンロードしてインストールします。
Neo4jサーバーにはRestAPIがあり、phpにはneo4jphpライブラリがあります。 Symfony2との統合用のバンドル-klaussilveira / neo4j-ogm-bundleもあります。
ディストリビューションには、デフォルトでhttp:// localhost:7474 /で動作するWebサーバーとアプリケーションが含まれます
他の機能を備えた古いバージョンのclientがまだあります。
簡単なドキュメントをドキュメントとして使用すると便利です。 コード例はgraphgistにあります。 理論的には、そこでオンラインで実行する必要がありますが、現在は機能しません。 コードを表示するには、 graphgist (たとえば、 ここ )からのリンクをたどって、[ページソース]ボタンをクリックする必要があります。
Neo4jを使用した実験では、 組み込みのWebクライアントを使用すると非常に便利で、Cypherリクエストを実行し、ノードの接続と特性とともにリクエストへの応答を表示できます。
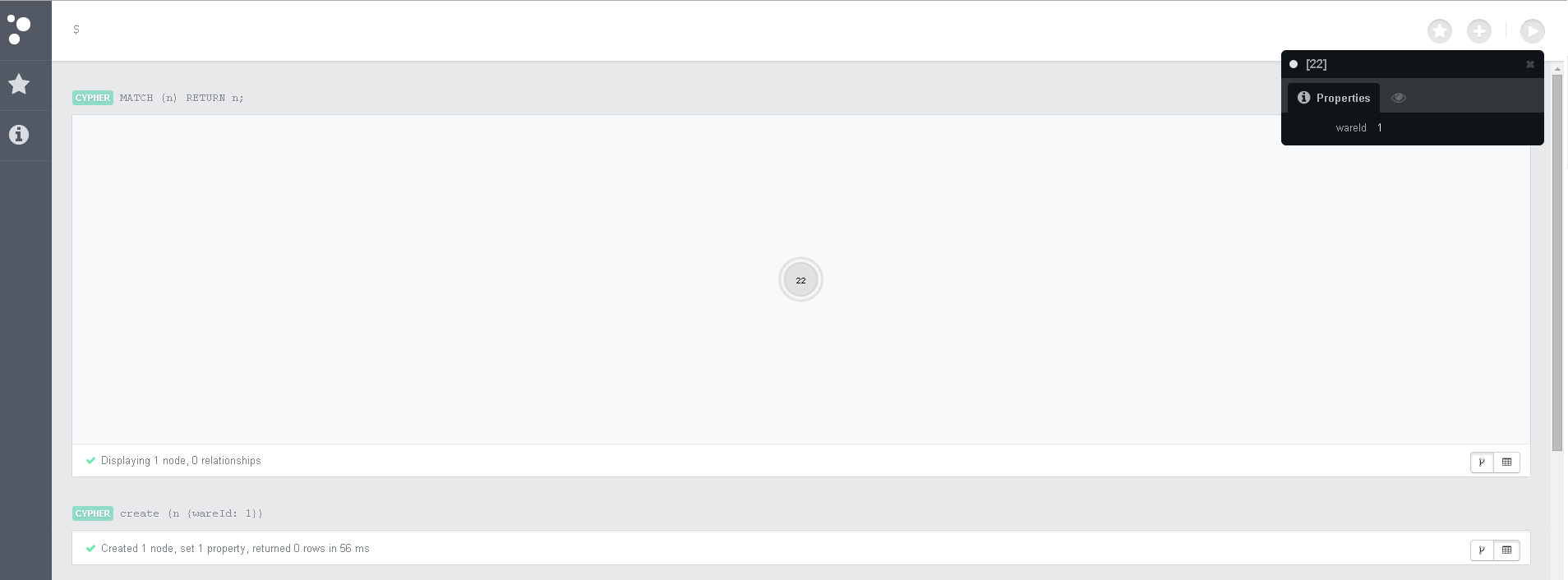
単純な暗号コマンド
ラベル付きのノードを作成する
create (n:Ware {wareId: 1});
すべてのノードを選択
MATCH (n) RETURN n;
カウンター
MATCH (n:Ware {wareId:1}) RETURN "Our graph have "+count(*)+" Nodes with label Ware and wareId=1" as counter;
2つの関連ノードを作成する
CREATE (n{wareId:1})-[r:SUIT]->(m{criteriaId:1})
2つの既存のノードをリンクする
MATCH (a {wareId: 1}), (b {criteriaId: 2}) MERGE (a)-[r:SUIT]->(b)
関連するすべてのノードを削除する
match (n)-[r]-() DELETE n,r;
すべての無関係なノードを削除します-関係するノードがあるデータベースでこのコマンドを実行しようとすると、機能しません。 最初に関連するノードを削除する必要があります。
match n DELETE n;
基準に一致する製品を選択3
MATCH (a:Ware)-->(b:Criteria {criteriaId: 3}) RETURN a;
一度にいくつかのCypherコマンドがWebクライアントを実行できません。 彼らは古いクライアントがその方法を知っていると言うが、私はそのような機会を見つけられなかった。 したがって、1行をコピーする必要があります。
1つのコマンドでリンクを持つ複数のノードを作成できます。ノードに異なる名前を付ける必要があります。リンクに名前を付けることはできません
CREATE (w1:Ware{wareId:1})-[:SUIT]->(c1:Criteria{criteriaId:1}), (w2:Ware{wareId:2})-[:SUIT]->(c2:Criteria{criteriaId:2}), (w3:Ware{wareId:3})-[:SUIT]->(c3:Criteria{criteriaId:3}), (w4:Ware{wareId:4})-[:SUIT]->(c1), (w5:Ware{wareId:5})-[:SUIT]->(c1), (w4)-[:SUIT]->(c2), (w5)-[:SUIT]->(c3);
そのような構造を取得します。 見えにくい場合は、マウスを使用してノードを再配置できます。

中級Neo4j速度テスト
今度は、データベースと大規模なデータベースからの単純なサンプルを埋める速度をテストします。
これを行うには、neo4jphpのクローンを作成します
git clone https://github.com/jadell/neo4jphp.git
このライブラリの基本的な説明はこの投稿にありますので、すぐにサンプル/ test_fill_1.phpテストベースを作成するコードをレイアウトします
<?php use Everyman\Neo4j\Client, Everyman\Neo4j\Index\NodeIndex, Everyman\Neo4j\Relationship, Everyman\Neo4j\Node, Everyman\Neo4j\Cypher; require_once 'example_bootstrap.php'; $neoClient = new Client(); $neoWares = new NodeIndex($neoClient, 'Ware'); $neoCriterias = new NodeIndex($neoClient, 'Criteria'); $neoWareLabel = $neoClient->makeLabel('Ware'); $neoCriteriaLabel = $neoClient->makeLabel('Criteria'); $wareTemplatesCount = 200; // $criteriasCount = 500; // $waresCount = 10000; // $commitWares = 100; // , 1 batch $minRelations = 200; // $maxRelations = 400; // $time = time(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) { $neoClient->startBatch(); print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") ..."; $criterias = array(); // for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) { $c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - commitBatch $neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save() $criterias[] = $c; } // for($wareId = 1;$wareId <=$waresCount;$wareId++) { $w = $neoClient->makeNode()->setProperty('wareId', $wareTemplateId * $waresCount + $wareId)->save(); // ->addLabels(array($neoWareLabel)) - commitBatch $neoWares->add($c, 'wareId', $wareTemplateId * $waresCount + $criteriaId); // for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) { $w->relateTo($criterias[array_rand($criterias)], "SUIT")->save(); } if(($wareId % $commitWares) == 0) { // , Neo4j $neoClient->commitBatch(); print " [commit ".$commitWares." ".(time() - $time)." sec]"; $time = time(); $neoClient->startBatch(); } } $neoClient->commitBatch(); print " done in ".(time() - $time)." seconds\n"; $time = time(); }
私は夜のために基地を埋めるためのスクリプトを残しました。 約4時間後、スクリプトはデータの追加を停止し、Neo4jサービスはサーバーの100%のロードを開始しました。 午前中、作業の結果によると、8つのカテゴリーの商品から78,300の製品が挿入されました。
データベースのテスト入力の結果は、200〜400の接続で1秒あたり約20製品です。 それほど高い結果ではありません-MysqlとCassandraは、1秒あたり約10〜2万の挿入(10フィールド、1つのプライマリインデックス、1つのインデックス)を生成しました。 ただし、挿入速度は重要ではありません。製品を編集した後、バックグラウンドでデータグラフを更新できます。 ただし、データサンプリングの速度は重要です。
ディスク上のテストデータベースのサイズは1781メガバイトです。 78,300の製品、4,000の基準、156.66万から31320000の接続を保存します。 オブジェクト(ノードとリンク)の総数は3,200万未満で、エンティティあたり平均55バイトです。 私については少しですが、主な要件はサンプルの速度であり、データベースのサイズではありません。
サンプリング速度をテストする最初の試みは失敗しました-Neo4jサーバーは再び100%プロセッサ負荷モードに「移行」し、数分でリクエストに応答しませんでした。
MATCH (c {criteriaId: 1})<--(a)-->(b {criteriaId: 3}) RETURN a.wareId;
先に進むには、Neo4jでリクエストを最適化する方法を理解する必要があります。 最初は、START命令を使用して、選択範囲内のノードの開始セットを制限したかった
START n=node:nodeIndexName(key={value}) MATCH (c)<--(a)-->(b) RETURN a.wareId;
これを行うには、データベースにインデックスが必要です。 Neo4jでは、現在のインデックスのリストを表示するコマンドは見つかりませんでしたが、Neo4j Webアプリケーションではコマンドを入力できます
:schema
次のコマンドでインデックスを追加できます
CREATE INDEX ON :Criteria(criteriaId)
チームが一意のインデックスを作成できます
CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE;
上記のコマンドで追加されたインデックスは、STARTディレクティブでは使用できません。 彼らはどこでしか使用できないと主張している
Cypherを介して作成されたインデックスはスキーマインデックスと呼ばれ、START句では使用されません。 START句のインデックスルックアップは、自動インデックス作成または非暗号化APIを介して作成するレガシーインデックス用に予約されています。
作成したユーザーインデックスを使用するには、次のようにします。
マッチn:ユーザー
ここで、n.name = "aapo"
nを返します。
ドキュメントを正しく理解していれば、STARTの代わりにWHEREを安全に使用できます。
STARTはオプションです。 明示的な開始点を指定しない場合、Cypherはクエリから開始点を推測しようとします。 これは、クエリに含まれるノードラベルと述語に基づいて行われます。 詳細については、第14章、スキーマを参照してください。 一般に、START句は、レガシーインデックスを使用する場合にのみ本当に必要です。
最初の仕事の依頼が生まれました
MATCH (a:Ware)-->(c1:Criteria {criteriaId: 3}),(c2:Criteria {criteriaId: 1}),(c3:Criteria {criteriaId: 2}) WHERE (a)-->(c2) AND (a)-->(c3) RETURN a;
テストデータベースにインデックスが見つからなかったため、テスト用に別のデータベースを別の方法で作成します。 Neo4jで独立したデータセット(MySQLのデータベースの類似物)を作成する機能が見つかりませんでした。 したがって、テストのために、Neo4j Community(データベースの場所)の設定でデータストアへのパスを変更しました
注意深い読者は、test_fill_1.phpコードにいくつかのコメントを見つけたかもしれません。
$c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - commitBatch $neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save()
Neo4jphpのバッチモードでは、ノードにラベルを追加できず、何らかの理由でインデックスが保存されませんでした。 Cypherが中国語の手紙でなくなったことを考えると、純粋なCypherでデータベースのハードコアを埋めることにしました。 だから、test_fill_2.phpになりました
<?php use Everyman\Neo4j\Client, Everyman\Neo4j\Index\NodeIndex, Everyman\Neo4j\Relationship, Everyman\Neo4j\Node, Everyman\Neo4j\Cypher; require_once 'example_bootstrap.php'; $neoClient = new Client(); $wareTemplatesCount = 100; // $criteriasCount = 50; // $waresCount = 250; // $minRelations = 20; // $maxRelations = 40; // if($maxRelations > $criteriasCount) { throw new \Exception("maxRelations[".$maxRelations."] should be bigger, that criteriasCount[".$criteriasCount."]"); } $query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE;", array()); $result = $query->getResultSet(); $query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Ware) ASSERT n.wareId IS UNIQUE;", array()); $result = $query->getResultSet(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) { $time = time(); $queryTemplate = "CREATE "; print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") ..."; $criterias = array(); for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) { // (w1:Ware{wareId:1}) $cId = $criteriaId + $criteriasCount*$wareTemplateId; $queryTemplate .= "(c".$cId.":Criteria{criteriaId:".$cId."}), "; $criterias[] = $cId; } for($wareId = 1;$wareId <=$waresCount;$wareId++) { $wId = $wareId + $waresCount*$wareTemplateId; // (w1:Ware{wareId:1}) $queryTemplate .= "(w".$wId.":Ware{wareId:".$wId."}), "; // (w1)-[:SUIT]->(c1) $possibleLinks = array_merge(array(), $criterias); // clone $criterias for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) { $linkId = $possibleLinks[array_rand($possibleLinks)]; unset($possibleLinks[$linkId]); $queryTemplate .= "w".$wId."-[:SUIT]->c".$linkId.", "; } } $queryTemplate = substr($queryTemplate,0,-2); // ", " $build = time(); $query = new Cypher\Query($neoClient, $queryTemplate, array()); // $queryTemplate 42 10000 , 500 , 200-400 - $result = $query->getResultSet(); print " Query build in ".($build - $time)." seconds, executed in ".(time() - $build)." seconds\n"; // die(); }
データを追加する速度は、第1の実施形態よりも予想以上に速かった。
30,000個のノードとcypher上の500,000〜1,000,000個の接続を追加したテストスクリプトは140秒間機能し、データベースは62 MBのディスクスペースを使用しました。 $ waresCount = 1000(10,000個の製品は言うまでもなく)でスクリプトを実行しようとすると、「スタックオーバーフローエラー」エラーが表示されました。 を使用してスクリプトを書き直しました。
MATCH (a {wareId: 1}), (b {criteriaId: 2}) MERGE (a)-[r:SUIT]->(b)
これにより壊滅的な速度低下が生じ、修正されたスクリプトは約1時間働きました。 いくつかの基準でサンプリング速度をテストし、後で高速データ挿入の問題に戻ることにしました。
<?php use Everyman\Neo4j\Client, Everyman\Neo4j\Index\NodeIndex, Everyman\Neo4j\Relationship, Everyman\Neo4j\Node, Everyman\Neo4j\Cypher; require_once 'example_bootstrap.php'; $neoClient = new Client(); $time = microtime(); $query = new Cypher\Query($neoClient, "MATCH (a:Ware)-->(b:Criteria {criteriaId: 3}),(c:Criteria {criteriaId: 1}),(c2:Criteria {criteriaId: 2}) WHERE (a)-->(c) AND (a)-->(c2) RETURN a;", array()); $result = $query->getResultSet(); print "Done in ".(microtime() - $time)." seconds\n";
上記のスクリプトは0.02秒で機能しました。 一般に、これはまったく許容できますが、商品のプロパティを更新するときにノード間の多数の接続を迅速に維持する方法の問題は残ります。
代替ソリューション
MySQLをリポジトリとして使用することを「良心を取り除く」ことにしました。 ノード間のリンクは、追加情報なしで別のテーブルに保存されます。
CREATE TABLE IF NOT EXISTS `edges` ( `criteriaId` int(11) NOT NULL, `wareId` int(11) NOT NULL, UNIQUE KEY `criteriaId` (`criteriaId`,`wareId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
以下のデータベースを埋めるためのテストスクリプト
<?php mysql_connect("localhost", "root", ""); mysql_select_db("test_nodes"); $wareTemplatesCount = 100; $criteriasCount = 50; $waresCount = 250; $minRelations = 20; $maxRelations = 40; $time = time(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) { $criterias = array(); for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) { $criterias[] = $wareTemplateId * $criteriasCount + $criteriaId; } for($wareId = 1;$wareId <=$waresCount;$wareId++) { $edges = array(); $wId = $wareTemplateId * $waresCount + $wareId; $links = array_rand($criterias,rand($minRelations,$maxRelations)); foreach($links as $linkId) { $edges[] = "(".$criterias[$linkId].",".$wareId.")"; } // mysql_query("INSERT INTO edges VALUES ".implode(",",$edges)); } print "."; } print " [added ".$wareTemplatesCount." templates in ".(time() - $time)." sec]"; $time = time();
データベースの入力には12秒かかりました。 テーブルのサイズは37メガバイトです。 2つの基準による検索には0.0007秒かかります
SELECT e1.wareId FROM `edges` AS e1 JOIN edges AS e2 ON e1.wareId = e2.wareId WHERE e1.criteriaId =17 AND e2.criteriaId =31
別のオプション
mysqlには完全なグラフデータウェアハウスがありますが、テストしていません。 ドキュメントから判断すると、Neo4jよりもはるかに原始的です。
結論
Neo4jは非常にクールなものです。 Neo4jで「私が好きなミュージシャンが書いたサウンドトラックを鳴らす映画に出演した映画俳優が好きなユーザーの連絡先を選択する」といった要求は簡単に解決されます。 このようなもの
MATCH (me:User {userId:123})-[:Like]->(musicants:User)-[:Author]->(s:Soundtrack)-[:Used]->(f:Film)<-[:Starred]-(actor: User)<-[:Like]-(u:User) RETURN u
SQLの場合、これははるかに面倒な作業です。
完全なグラフデータベースとMySQLの裸のインデックステーブルを比較することは正しくありませんが、私の問題の解決策の一部として、Neo4jを使用しても利点はありませんでした 。
更新 画像のURLを変更しました。理論的には、それらはすべてロードする必要があります。
更新2 。 彼らはさらにいくつかのオプションを提案しました-MongoDB、elasticsearch、solr、sphinx、OrientDB。 MongoDBをテストする予定です。テスト結果をすぐに投稿します。