現在、AWSとプライベートデータセンターの両方で、サイズの異なるいくつかのmongodbシステムを使用しています。 私の使用パターンは、主に珍しいが大量のデータ記録(1日1回)、やや頻繁な大量の読み取り操作(一連のさまざまな分析)、およびフロントエンドデータ供給モードでの一定の読み取りに焦点を当てています。 今後の(6か月後に計算される)ディスクの問題を除き、mongaには特別な問題はありません。 システムのデータが削除されることはなく、最終的にはディスクに収まりません。 AWSでは、MongaはIOPSが保証された比較的高価なEBSボリュームで実行されます。 ディスクスペースの不足の問題に対する従来のソリューション(古いデータを安価な構成で別のMongに転送する)を既に計画していましたが、TokuMXは9回の圧縮の約束に気づきました。 さらに、Mongでの記録のロールバックはクライアントのみによって行われます。これを使用せずにサーバーレベルに転送するのは良いことです。
TokuMXの魔法の仕組みに興味がある場合は、そのサイトにようこそ。 ここでは、その内容と構成方法については説明しませんが、表面テストの結果を共有します。 私のテストは科学的な正確さのふりをせず、主な目標は、MongaからCurrentに切り替えた場合に実際のシステムで何が起こるかを示すことです。
移行の透明性:
これですべてが順調です。 monga(約200)での作業をカバーする私のテストには問題がありませんでした。 mongaで動作するすべてのものがcurrentでも動作します。 統合テストでも問題は明らかになりませんでした。 私の場合、クライアントシステムをTokuMXアドレスにリダイレクトすることができ、代替に気付かずに引き続き動作します。 1つのレプリカセットで現在のmongaのハイブリッド操作のモードをテストしませんでしたが、これは機能すると思われます。
記録テスト:
テストは、20Gドライブと1G RAMのそれぞれに2つのプロセッサを備えた2つの同一の仮想マシンで実行されました。 ホストコンピューター-MBPR i7、SSD、16G RAM。 1日でエントリ(トレードキャンドル)を挿入します。わずか140万本のキャンドルです。 平均記録サイズは270バイトです。 3つの追加インデックス(1つは単純、2つは複合)。

ご覧のとおり、違いがあり、TokuMXは本当に高速です。 もちろん、約束された20回ではなく、悪くもありません。 プロセッサの負荷は非常に高くなりますが、これは圧縮に関連して予想されます。
TokuMXのデータサイズ+インデックスもmongaのデータサイズよりも小さいことが判明しましたが、わずか1.6倍です。
読書テスト:
読書は実際の使用に近いモードでテストされました。 すべてのクイッククエリ(ティッカーによる)は、200ティッカー、10,000クエリのランダムサンプルに対して繰り返し実行され、結果は平均化されました。 間隔(時間内)要求は、ランダムな間隔で10回、繰り返し実行されました。 同じ要求がmonguとcurrentに同じ順序で送信されました。 このテストの主な目的は、できるだけリアルに近いアクティビティを作成することでした。 時間はマイクロ秒単位で与えられます。

私は自分の目を信じていませんが、これらのテストを何度も実行しましたが、同様の結果(小さな変動)が安定して繰り返されました。 私のすべてのテストで、mongoがtokumxを1.5〜3回追い越す同様の違いが常に再現されました。
TokuMXがより多くのCPUを必要とする可能性があると判断したため、4つのプロセッサを備えたtokuを備えた仮想マシンが2つのモンガと競合する不平等な戦いがありました。 結果はわずかに良くなりますが、これらの不均等な条件でもmongoはより高速なままです(差は平均で1.4倍です)。 電流がmonguを通過した(ほぼ2回)唯一のテストは、最後のテスト-1日のすべてのろうそくです。
これをすべてテストする方法を考えて、データセットがメモリに収まらないように、両方の参加者のRAMの量を減らしました。 私は次の結果を得ました:
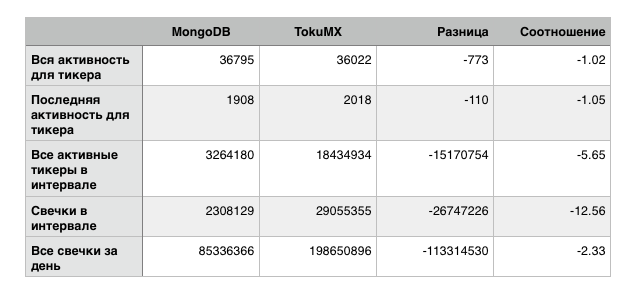
一般に、この結果はさらに悪く見え、12倍の差はそれほど楽観的ではありません。 ただし、最初の2つのテストはモンガに著しく近いため、私の場合、全体的な結果はおそらく同等です。 このような「改善された」リクエストは、大幅に削減するよりも多くあります。
少量のメモリでのテスト中に、現在の奇妙な特性に出くわしました-指定されたキャッシュサイズが使用可能なRAMに収まらない場合、電流は応答によって単純に切断され、もちろんクライアント側はこれにより非常に困惑し、データが予想よりも早く終了したことを叫び始めます。
そしてもう1つ-これらすべてのテストで、「すぐに使える」mongoがありました。 TokuMXについては、前回のテストで安心しました-ダイレクトIOを有効にし、マニュアルで推奨されているようにキャッシュサイズを設定しました。
結論:
私の予備的な結論はこれです。TokuMXが自分自身に書いていること、つまり「箱から出して20倍高速で9倍コンパクト」は、私の場合は完全に真実ではありません。 TokuMXでは、ほとんどすべての読み取り操作が遅く(場合によってははるかに遅く)、応答の恐ろしく静かなトリミングも良くありません。 私にとって、トランザクションサポート、1.4倍の書き込みアクセラレーション(データベースにロックはありませんが、ドキュメントにのみあります)、および1.6倍のデータサイズの増加は、すべての読み取り操作の大幅なパフォーマンス低下に値しません。