エントリー
プレイヤーが特定の文字セットから単語を検索する必要のあるゲームがたくさんあります。 最も人気のある2つを次に示します。
1.4 Pics 1ワード(4 Pics 1ワード) AppStore 、 Google Play
このゲームには多くの実装がありますが、誰もが1つのアイデアを持っています。
2.スロベニア(Wordsmania) AppStore 、 Google Play
最初のゲームの本質:4枚の写真、推測された単語の長さ、文字のセットが与えられ、任意の順序で文字を選択できます。

2番目の本質は、文字で満たされた4x4フィールドで、できる限り多くの単語を見つける必要があることです。各セルから次、垂直、水平、斜めに移動できます。

私は、これらのゲームが引き起こす問題に対するソフトウェアソリューションのアイデアに興味がありました。 私はゲームを不誠実にするための目標を設定するのではなく、自分のために設定されたタスクに純粋にスポーツの関心を向けます。 これらのゲームの人気のピークはすでに過ぎているので、誰かが少し不正直にプレイしてもそれほど怖くはありません。
問題の声明
問題をより正式に検討する場合、ゲームのルールに基づいて可能な組み合わせを列挙する必要があります。 ゲームごとに2つのブルートフォースアルゴリズムが実装されます。 次に、辞書内のこれらの組み合わせの存在を確認する必要があります。そのためには、辞書内の単語の存在の要求に効果的に応答できる構造を実装する必要があります。 ホウ素が使用されます。
なぜホウ素
標準C ++ライブラリでは、mapやunordered_map(ハッシュマップ)などの単一の要求にすばやく応答できる構造が既に実装されています。 しかし、これらの構造の助けを借りたタスクの実装は、タスクの特徴を考慮に入れるため、ホウ素に比べて漸近的に劣ります。 値の列挙は、各文字から次の値を再帰的に検索しようとするため、ツリーになります。 Borはツリーでもあるため、単語の検索は、アルゴリズムが辞書に存在しない遷移に達するまで、検出されたすべての単語の合計長と反復回数の最悪の場合に行われます。実際には、このような遷移は非常に迅速に達成されます。 アルゴリズムは、辞書に属する文字列Pをプレフィックスとして含む文字列Sがある場合により効率的に機能します。この場合、検索は長さSを超え、他のすべてのPは検索Sとして回答に追加されます。
次に、ソートされた形式で単語を表示する必要があります。
実装
問題の解決策を部分的に実装することを検討してください。
含まれるもの
コンソールとファイルI / O、iostream、fstreamを提供する必要があります。 標準のSTLテンプレートが必要です。ベクター-ボロン、ストリング、セットを作成するため-結果を保存し、見つかった同一の単語をカットするため、ソートのためのアルゴリズム。
含まれるもの
#include <iostream> #include <fstream> #include <vector> #include <string> #include <set> #include <algorithm>
お知らせ
ローカライズを有効にせずにロシア語の文字を使用して、そのようなコードを他のエンコーディングに簡単に調整できるようにするため、単純なサンプル文字列を入出力に使用することにしました。 これは、ロシア語のアルファベットConsoleSampleを入力したときに取得したサンプルと、FstreamSampleファイルから読み取ったときに取得したサンプルです。
次に、ホウ素の各頂点の構造について説明します。各文字ごとに遷移を格納します。遷移がない場合は0を格納します。構造内のisLeaf変数を使用して、特定の単語がこの頂点で終了することも示されます。
ボロン、結果のバッファ、およびフォーマットされた出力を保存するコンテナを宣言します。
お知らせ
#define ALPHABET_SIZE 33 const char ConsoleSample[ALPHABET_SIZE] = { -96, -95, -94, -93, -92, -91, -15, -90, -89, -88, -87, -86, -85, -84, -83, -82, -81, -32, -31, -30, -29, -28, -27, -26, -25, -24, -23, -20, -21, -22, -19, -18, -17 }; const char FstreamSample[ALPHABET_SIZE] = { -32, -31, -30, -29, -28, -27, -72, -26, -25, -24, -23, -22, -21, -20, -19, -18, -17, -16, -15, -14, -13, -12, -11, -10, -9, -8, -7, -4, -5, -6, -3, -2, -1 }; typedef struct { unsigned child[ALPHABET_SIZE]; bool isLeaf; } node; node NullNode = {NULL}; vector<node> Trie; set<string> Res; vector<string> Output;
borに単語を追加
関数は入力としてラインを受け取り、それを通過し、同時にホウ素に沿って移動します。頂点からの遷移がない場合、新しい頂点がホウ素に追加され、追加された頂点への遷移がインデックスを使用して現在の頂点に書き込まれます。 最後の遷移を追加すると、最後の頂点のisLeaf変数の値がtrueに変わり、ここで単語が終了します。
言葉を追加する
void TrieAddWord(string &S) { unsigned CurrentNode(0); for (auto i(S.begin()); i != S.end(); ++i) { if (Trie[CurrentNode].child[*i] == 0) { Trie.push_back(NullNode); Trie[CurrentNode].child[*i] = Trie.size() - 1; CurrentNode = Trie.size() - 1; } else { CurrentNode = Trie[CurrentNode].child[*i]; } } Trie[CurrentNode].isLeaf = true; }
辞書をダウンロードする
便宜上、すべての単語について、要求の処理中に、シンボル番号がシフトされます。つまり、シンボル「a」の値は0になり、シンボル「i」の値は32になります。Encode関数は、 。 このような実装は簡単ですが、辞書をロードするのに余分な時間がかかりますが、それほど重要ではありません。辞書が一度ロードされると、プログラムに複数回リクエストを送信できます。
文字列エンコーディング
void EncodeString(string &S, const char Sample[]) { for (auto i(S.begin()); i != S.end(); ++i) { for (char j(0); j != ALPHABET_SIZE; ++j) { if (*i == Sample[j]) { *i = j; break; } } } }
辞書読み込み関数は、ファイル名を受け取り、そこからすべての単語を読み取り、行をエンコードしてから、フォレストに追加します。 すべてのファイルに対して実行する場合、関数は複数の辞書を一度にロードできます。
辞書をダウンロードする
void LoadDictonary(char *Filename) { ifstream in(Filename); string Buff; while (!in.eof()) { in >> Buff; EncodeString(Buff, FstreamSample); TrieAddWord(Buff); } in.close(); }
出力ソート
最初にスロボマニアのゲームで最も長い単語を取得するには、コンソールに出力するときにテキストが下から上にスクロールするため、行を逆順に並べる必要があります。したがって、最も長い単語を最後に表示する必要があります。 ゲームでは、単語が大きいほど、明らかに多くのポイントが与えられます。 これを行うには、アルゴリズムからソートするために単純なコンパレータ関数を作成する必要があります。
コンパレータ
bool cmp(string A, string B) { if (A.size() >= B.size()) { return false; } else return true; }
Wordソリューションを推測する
このゲームには多くの認識と名前があるため、単に「単語を推測する」と呼びます。
はじめに、ホウ素バイパス機能。 ここでは、通常の再帰的なDFSアルゴリズムを使用します。各文字から、指定された文字列から以前に使用されていなかったものに移動し、同時に、ホウ素にそのような遷移の存在を確認し、遷移が存在する場合は、さらに続行し、そうでない場合は、さらに進行を停止このスレッドで。 ゲームでは、特定の長さの単語を推測する必要があるため、行の長さに等しい深さまでしか下がらないことに注意することが重要です。それ以上下がっても意味がありません。 isLeaf変数がtrueであり、見つかった単語の長さが指定された値と等しい場合、isLeaf変数を確認することを忘れないでください。次に、単語を追加してResを設定します。
バイパス
void GuessWordBypass(unsigned N, __int8 X, bool Used[], string &S, string W, short &L) { if (W.size() > L) return; for (__int8 i(0); i != S.size(); ++i) { if (i == X) continue; if (!Used[i]) { if (Trie[N].child[S[i]] != 0) { Used[i] = true; GuessWordBypass(Trie[N].child[S[i]], i, Used, S, W + S[i], L); Used[i] = false; } } if (Trie[N].isLeaf && W.size() == L) { Res.insert(W); } } }
そして、単語のすべての文字の走査の最初の開始を実装する関数。
打ち上げ
void GuessWord(string &S, short &L) { bool *Used = new bool [S.size()]; memset(Used, 0, S.size()); for (__int8 i(0); i != S.size(); ++i) { if (Trie[0].child[S[i]] != 0) { Used[i] = true; GuessWordBypass(Trie[0].child[S[i]], i, Used, S, S.substr(i, 1), L); Used[i] = false; } } delete [] Used; }
ゲームスロベニアのソリューションの実装
一般に、バイパス自体に違いはありませんが、違いは、ここでは隣接セルにのみ移動でき、どのセルにも移動できないことです。検索では、任意の長さの単語が検索されるはずです。 4x4フィールドは1次元配列で表されるため、隣接セルに移動する方法は明らかではないため、これを実装する方法を検討します。
セルがフィールドの境界にない場合は、-5から5までの数字を追加し、それらから-2、0、2を除外します。
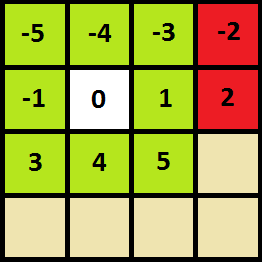
セルが境界線上にある場合、境界線を越える他のセルへの移行を禁止することも必要です。

バイパス
void WordsmaniaCheatBypass(unsigned N, __int8 X, bool Used[], string &S, string W) { __int8 TransitDenied[11] = {0}; for (__int8 i(-2); i <= 2; i += 2) TransitDenied[i + 5] = true; if (X % 4 == 0) for (__int8 i(-5); i <= 3; i += 4) TransitDenied[i + 5] = true; if (X < 4) for (__int8 i(-5); i <= -3; ++i) TransitDenied[i + 5] = true; if (X % 4 == 3) for (__int8 i(-3); i <= 5; i += 4) TransitDenied[i + 5] = true; if (X >= 12) for (__int8 i(3); i <= 5; ++i) TransitDenied[i + 5] = true; for (__int8 i(-5); i <= 5; ++i) { if(TransitDenied[i + 5]) continue; __int8 tmp = X + i; if (!Used[tmp]) { if (Trie[N].child[S[tmp]] != 0) { Used[tmp] = true; WordsmaniaCheatBypass(Trie[N].child[S[tmp]], tmp, Used, S, W + S[tmp]); Used[tmp] = false; } } if (Trie[N].isLeaf) { Res.insert(W); } } }
打ち上げ
void WordsmaniaCheat(string &S) { bool Used[16] = {0}; for (__int8 i(0); i != 16; ++i) { if (Trie[0].child[S[i]] != 0) { Used[i] = true; WordsmaniaCheatBypass(Trie[0].child[S[i]], i, Used, S, S.substr(i, 1)); Used[i] = false; } } }
主な機能
メイン関数では、ホウ素が初期化され、メインループが実行され、リクエストが処理されます。 「1」または「2」は、使用するアルゴリズムに応じて最初の引数であり、次にアルゴリズムのパラメーターです。 結果を処理、ソート、表示した後。 最初のアルゴリズムでは、文字のシーケンスを入力し、次に単語の長さを入力する必要があります。2番目のアルゴリズムでは、フィールドの行に書き込まれます。つまり、そのようなフィールドでは、文字列「無制限」(引用符なし)を入力する必要があります
メイン
int main() { Trie.push_back(NullNode); LoadDictonary("Dictonary.txt"); string Word; char mode; while (true) { cin >> mode; switch (mode) { case '1': short L; cin >> Word >> L; EncodeString(Word, ConsoleSample); GuessWord(Word, L); break; case '2': cin >> Word; EncodeString(Word, ConsoleSample); WordsmaniaCheat(Word); break; } cout << "==================" << endl; for (auto i(Res.begin()); i != Res.end(); ++i) { Output.push_back(*i); } Res.clear(); if(mode == '2') sort(Output.begin(), Output.end(), cmp); for (auto i(Output.begin()); i != Output.end(); ++i) { for (auto j((*i).begin()); j != (*i).end(); ++j) { cout << ConsoleSample[*j]; } cout << endl; } cout << "==================" << endl << endl; Output.clear(); } return 0; }
次は何ですか
完全なコードは次のとおりです 。Windowsでテストされています。他のプラットフォームでは、入力サンプルと出力サンプルを置き換える必要があります。
ただし、 辞書は大小の辞書です ( 大規模な辞書を使用する場合は、名前の末尾の数字2を削除することを忘れないでください)。 大規模な辞書には、最初のフォームだけでなく、Microsoft Wordamentに適していますが、フィールドのセルに常に1文字あるとは限りません。 ほとんどの場合、説明されている2つのゲームの小さな辞書で順位表のトップになります。
誰もこのように多くプレイしないことを願っていますが、ほとんどのプレイヤーはフェアでプレーし続けます。