
FEALコードの強度はDESと同じです。 さらに、キーの長さの増加(DESの56ビットと比較して64ビット)により、列挙が困難になります。 FEAL暗号には、ランダムに近い暗号テキストの良好な分布があります。 また、DESと比較してFEALを支持しています。これは、1987年のFEAL暗号化アルゴリズム仕様の要約です。
永遠に続くものはありません。 このトピックでは、オープンクローズテキストが40ペアしかない場合に、数分で完全なFEAL4キーを取得する方法を説明します。
差分暗号解読
まず、ロシアの耳を愛careする「差分暗号解析」という名前の下に隠されているものを把握しましょう。
差分暗号解読は、選択されたクリアテキストによる攻撃です。 これは、DCを使用するために、絶対にあらゆる量のテキストを絶対に暗号化できる必要があることを意味します。
DCを使用する攻撃者の目標は、キーに関する情報を取得することです。これにより、キーが完全に侵害され(非常にまれ)、キーを選択する際に何らかの利点が得られます。
すべて次のように機能します。 2つの事前に選択された暗号文P 1およびP 2について、攻撃者は「差分」ΔP= P 1⊕P 2を計算します。 そして、ΔPの助けを借りて、彼はΔ= C 1⊕C2の暗号文の「差分」がどうあるべきかを決定しようとしています。 多くの場合、Δの値を100%の精度で予測することは不可能です。 攻撃者ができる唯一のことは、暗号が所定のΔPに対してさまざまなΔ値を返す頻度を決定することです。 この知識により、攻撃者はキーの一部またはキー全体を開くことができます。
例として、次の図に示す3ラウンドブロック暗号を見てみましょう。
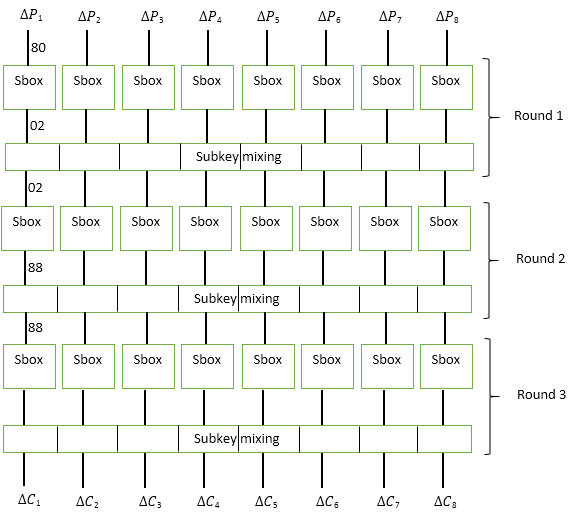
この暗号には、64ビットのブロックサイズと128ビットのキーがあります。
各ラウンドで、入力ブロックは8バイトに分割され、各バイトはSbox置換関数を通過します 。 その後、データは64ビットのサブキーサブキーと混合されます。 シャッフル機能は通常のXORです。
攻撃者が差分0x80を確認することにしたと仮定します。 これを行うために、任意のバイトX 1を生成し、X 2 = X 1⊕80を計算します。
次に、攻撃者はSbox関数を介してX 1とX 2を実行し、Y 1とY 2の値を受け取ります。 差分が80であるこのようなペアX 1およびX 2ごとに、攻撃者は差分ΔYを取得できます。 攻撃者は、取得した値を分析して、発生する可能性が高いΔY値を選択します。
例に戻って、すべての256のペアX 1とX 2のうち、192の場合Y 1⊕Y 2 = 02と仮定します。 したがって、特定のΔX= 80の場合、値ΔY= 02の確率は192/256 = 3/4です。 これは、順番に、与えられたΔX= 80に対して、確率P 1 = 3/4で、2つの値U 1とU 2が 、ΔU= 02のように、第2ラウンドの入力に到達することを意味します。
キーが差分の値に影響することは決してないことに注意してください。 異なるテキストを暗号化し、XORを使用してキーシーケンスと混合する場合、キーは変更されないため、ΔUを計算する場合、キーのバイトは相互に除外されます。
2回目のラウンドの特性を明らかにするために、攻撃者は入力バイトX 1とX 2の新しい256ペアを生成します(X 1⊕X 2 = 02)。 X 1とX 2の各ペアのSbox関数を計算した後、攻撃者は256のΔY= 88のうち64の場合に気づきます。 つまり 与えられたΔX= 02に対してΔY= 88である確率は、P 2 = 64/256 = 1/4です。
したがって、攻撃者は確率の簡単な計算を行って、バイトX 1とX 2の各ペアの指定された暗号について、ΔX= 80、確率P = P 1 * P 2 = 3/4 * 1/4 = 3であることを理解します/ 16、最後のラウンドの前の暗号の内部状態の差分はΔY= 88です。
この知識を所有している攻撃者は、ΔP= 808080808080となるテキストのペアをいくつか生成し、3番目のサブキーのバイト単位の選択に進みます。
サブキーの最初のバイトを開く方法を示します。
最初のサブキーバイト[0]の256個の可能なバリアントのそれぞれと、暗号文ペア{C 1 、C 2 }ごとに、攻撃者はU 1 = Sbox(C 1⊕サブキー[0])およびU 2 = Sbox(C 2⊕サブキー[0])。
サブキー[0]が正しく推測された場合、ΔUを計算するとき、U 1とU 2の 16組ごとに約3が88になります。
このようにサブキーサブキーの最も可能性の高い最初のバイトを選択すると、攻撃者は2番目のバイトに移動し、同様に3回目のラウンドのキー全体を開くことができます。
最後のラウンドのキーが明らかになった後、攻撃者は最後から2番目のラウンドを攻撃し始めることができ、この方法で行動することは最終的にすべてのラウンド暗号キーに関する情報を受け取ります。
FEAL暗号の説明
次に、上記のアクションを実行しようとする暗号化アルゴリズムを検討します。
したがって、FEAL4はブロック暗号であり、ブロックサイズとキー長は64ビットです。
FEAL4アルゴリズムには同等の説明がいくつかありますが、差分暗号化のデモンストレーションに最も便利なものを使用します。
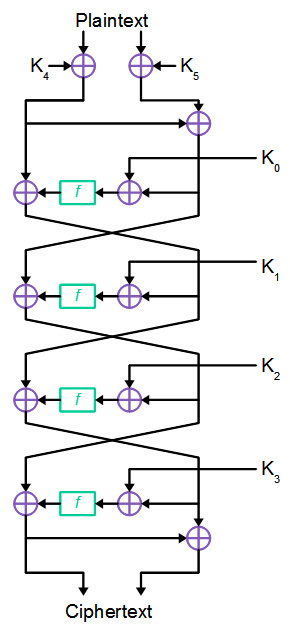
暗号は4ラウンドで構成され、メインキーから生成された6つの32ビットサブキーを使用します(将来、各サブキーは独立して生成されるため、抵抗しきい値を2 64から2 192に 「増やす」ことを想定しています)。
初期段階では、平文はそれぞれ32ビットの2つのブロックに分割されます。 左と右のブロックは、それぞれ32ビットのサブキーK [4]とK [5]で2を法として加算されます。 次に、左側の部分は変更されずに残り、左側のブロックにモジュロ2を追加することで右側が形成されます。
その後、4ラウンドの暗号化が実行され、それぞれのラウンドで右ブロックがラウンドK [i]の接続で2を法として合計され、結果が置換関数Fを介して実行されます。置換の結果はテキストの左側に追加されます。 これらの操作の後、左右のブロックが交換され、結果が次のラウンドの入力に送られます。
最終ラウンドは他の皆とは少し異なります。 前のラウンドのように、左右のブロックは場所を変えません。
代わりに、右側のブロックが左側のブロックと2を法として加算され、結果が暗号文の右側として返されます。 4ラウンド後の左側の部分は変更されないままで、受信した暗号文の最初の32ビットを構成します。
作成者によって記述された元の暗号スキームは、上記とわずかに異なりました。 元の説明では、6つの32ビットサブキーの代わりに、12の16ビットサブキーを使用します。 ただし、両方のオプションは同一であり、必要に応じて、32ビットキーを元の説明から16ビットキーとして簡単に表すことができます。
暗号の説明にある唯一の白い点は関数Fです。図では、次のように表すことができます。
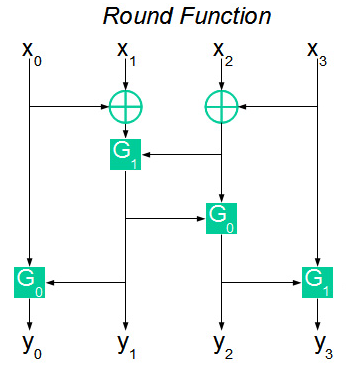
入力で、関数Fは4バイトX 1 、X 2 、X 3 、X 4を受け取ります。 次に、入力バイトが混合され、関数G 0またはG 1を通過します。 関数G xの計算後に取得された4バイトは、関数Fの32ビット出力シーケンスを形成します。
関数G 0およびG 1は、16ビットの入力シーケンスを8ビットの結果に変換します。
関数G 0は次のように表現できます。
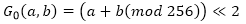 ここで、<<は左への循環シフトです。
ここで、<<は左への循環シフトです。
関数G 1の定義は次のとおりです。
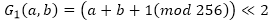 。
。
アルゴリズムの復号化も同じ原則に従います。 実際、暗号文は左右のブロックに分割され、すべての暗号化操作は逆の順序で実行されます。
つまり 最初に、最後のラウンドのデコード、次に最後から2番目のラウンドなどが続きます。
CでのFEAL4の実装#
class FEAL4 { private byte G0(byte a, byte b) { return (byte)((((a + b) % 256) << 2) | (((a + b) % 256) >> 6)); } private byte G1(byte a, byte b) { return (byte)((((a + b+1) % 256) << 2) | (((a + b+1) % 256) >> 6)); } public byte[] F(byte[] x) { byte[] y = new byte[4]; y[1] = G1((byte)(x[0] ^ x[1]), (byte)(x[2] ^ x[3])); y[0] = G0(x[0], y[1]); y[2] = G0(y[1], (byte)(x[2] ^ x[3])); y[3] = G1(y[2], x[3]); return y; } private void AddKeyPart(byte[] P, byte[] K) { for (int i = 0; i < 4; i++) { P[i] = (byte)(P[i] ^ K[i]); } } private byte[] XOR(byte[] a, byte[] b) { byte[] c=new byte[a.Length]; for (int i = 0; i < c.Length; i++) { c[i] = (byte)(a[i] ^ b[i]); } return c; } public byte[] Encrypt(byte[] P, byte[][] K) { byte[] LeftPart = new byte[4]; byte[] RightPart = new byte[4]; Array.Copy(P, 0, LeftPart, 0, 4); Array.Copy(P, 4, RightPart, 0, 4); AddKeyPart(LeftPart, K[4]); AddKeyPart(RightPart, K[5]); byte[] Round2Left = XOR(LeftPart, RightPart); byte[] Round2Right = XOR(LeftPart, F(XOR(Round2Left, K[0]))); byte[] Round3Left = Round2Right; byte[] Round3Right = XOR(Round2Left,F(XOR(Round2Right,K[1]))); byte[] Round4Left = Round3Right; byte[] Round4Right = XOR(Round3Left, F(XOR(Round3Right, K[2]))); byte[] CipherTextLeft = XOR(Round4Left,F(XOR(Round4Right,K[3]))); byte[] CipherTextRight = XOR(Round4Right, CipherTextLeft); byte[] CipherText = new byte[8]; Array.Copy(CipherTextLeft, 0, CipherText, 0, 4); Array.Copy(CipherTextRight, 0, CipherText, 4, 4); return CipherText; } public byte[] Decrypt(byte[] P, byte[][] K) { byte[] LeftPart = new byte[4]; byte[] RightPart = new byte[4]; Array.Copy(P, 0, LeftPart, 0, 4); Array.Copy(P, 4, RightPart, 0, 4); byte[] Round4Right = XOR(LeftPart, RightPart); byte[] Round4Left = XOR(LeftPart, F(XOR(Round4Right, K[3]))); byte[] Round3Right = Round4Left; byte[] Round3Left = XOR(Round4Right, F(XOR(Round3Right, K[2]))); byte[] Round2Right = Round3Left; byte[] Round2Left = XOR(Round3Right, F(XOR(Round2Right, K[1]))); byte[] Round1Right = Round2Left; byte[] Round1Left = XOR(Round2Right, F(XOR(Round1Right, K[0]))); byte[] TextLeft = Round1Left; byte[] TextRight = XOR(Round1Left,Round1Right); AddKeyPart(TextLeft, K[4]); AddKeyPart(TextRight, K[5]); byte[] Text = new byte[8]; Array.Copy(TextLeft, 0, Text, 0, 4); Array.Copy(TextRight, 0, Text, 4, 4); return Text; } }
FEAL4暗号の差分暗号解読
上記の例のように、置換関数Fを調べることにより、暗号の暗号解析を開始します。これは、FEAL暗号全体の最も重要な欠陥が隠されている場所です。 実際、関数Fは安全性の観点から壊滅的な性質を持っています。 X 1とX 2の任意の2つの値(X 1⊕X 2 = 0x80800000の差分)は、Y 1とY 2に変換されます。 さらに、ケースの100%での差分Y 1⊕Y 2 = 0x02000000。
これが起こる理由を理解するために、関数Fを計算するときに発生する微分変換を見てみましょう。
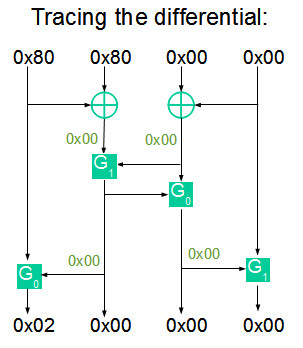
最初のバイトの位置でのみ、ゼロ以外の値が関数Gに入力されることに気付くのは簡単です。 したがって、出力は
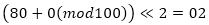 。
。
この特性により、暗号が差分暗号解析に対して絶対に脆弱になることは容易に理解できます。 特定の差分ΔYの100%の確率により、攻撃に必要なオープンテキストとクローズテキストのペアの数を最小限に抑えることができます。
最後のラウンドKのキーを解読するために、攻撃者がとるべきステップを検討してください[3]。
攻撃者は、ΔP= 0x8080000080800000になるように、いくつかのプレーンテキストペアP 1とP 2を生成します。 上記の関数Fの特性を知っている攻撃者は、暗号化のほぼすべてのラウンドで差分を計算できます。
次の図で差分の動作を追跡できます。
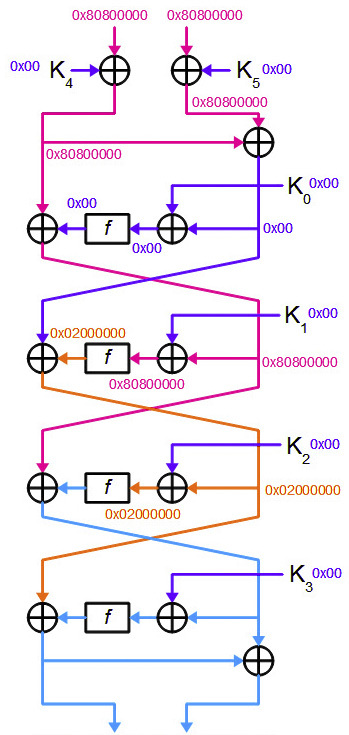
ご覧のように、最終ラウンドまでの差は誤って計算されます。 しかし、これがなくても、攻撃者はすでに最後のラウンドキーを開くのに十分な情報を持っています。
以下の図は、FEAL4暗号の最後の2ラウンドを示しています。
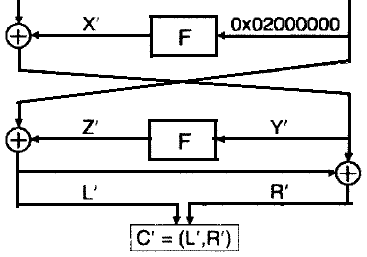
暗号文のペアC 1とC 2を持っているため、攻撃者はΔCを計算し、LとRの値を取得できます。
これに基づいて、彼はZ '= L'⊕02を計算できます。
一方、暗号文C 1とC 2の各ペアに対して、攻撃者はY 1とY 2を計算できます。
Y 1とY 2を知って、攻撃者はキーKの列挙を開始します[3]。 可能なキーKposごとに、Z 1 = F(Y 1⊕Kpos)およびZ 2 = F(Y 2⊕Kpos)が計算されます。 Z 1⊕Z 2のモジュロ2値を追加すると、攻撃者は結果の値を以前に計算されたZ 'と比較します。 Z '= Z 1⊕Z2の場合、KposはおそらくサブキーK [3]です。
エラーの可能性を減らすために、受信したKposキーを暗号文のいくつかのペアでチェックする必要があります(実装では10ペアを使用しました)。
上記の攻撃には関数Fの2 32の計算が必要であることを計算するのは簡単です。これは暗号の作成者が主張する2 64ではありませんが、特に4つの丸いキーすべてを計算したい場合、この数字はまだあまり快適ではありませんが、これは間違いなく必要です。
幸いなことに、攻撃は簡単になり、計算の数は非常に快適になります2 17 。
これを行うために、関数の定義を導入します
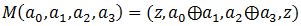 、ここで、aはバイトのセット、zはゼロバイトです。
、ここで、aはバイトのセット、zはゼロバイトです。
各A =(z、a 0 、a 1 、z)に対して、攻撃者はQ 0 = F(M(Y 0 )⊕A)およびQ 1 = F(M(Y 1 )⊕A)を計算します。
A = M(K [3])の場合、値Q 0⊕Q 1の2番目と3番目のバイトが値Z 'の2番目と3番目のバイトと一致することを確認するのは簡単です。 したがって、潜在的なキーKposの2バイトに関する情報を取得します。
その後、b 0およびb 1のすべての値について、攻撃者はシーケンスKpos =(b 0 、b 0⊕a0、b 1⊕a1、b 1 )を計算し、上記のように結果のシーケンスをチェックします。
サブキーK [3]を開いた後、攻撃者は3回目のラウンドの後に暗号が置かれた値を復元することができ、これによりサブキーK [2]を同様の方法で攻撃する機会が与えられます。 ただし、ここで、キーK [2]を攻撃するには、異なる初期差分を使用する必要があることに注意してください。 2回目のラウンドでの差分ΔP= 0x8080000080800000は、使用されるキーに対して常に値Z '= 0x02000000になります。 そして、これは2回目のラウンドのキーを推測することはできません。
次の値は、各サブキーを開くための差分として使用できます。
ラウンド4:0x8080000080800000
ラウンド3:0x0000000080800000
ラウンド2:0x0000000002000000
ラウンド1:0x0200000080000000
各ラウンドの4つのキーすべてを開いた後、キーK [5]およびK [4]を計算するのは簡単です。このため、4ラウンドの復号化を通して暗号文を駆動し、結果の値を2を法とする既知の平文を追加するだけで十分です。
攻撃ソースのダウンロードに興味がある場合は、 こちらから入手できます 。