はじめに
こんにちは親愛なる読者。
この投稿では、OpenCLオブジェクトのメモリ割り当ての機能について検討します。
OpenCLは、クロスプラットフォームの異種コンピューティング標準です。 実行速度が必要なときにプログラムが書き込まれるのは秘密ではありません。 原則として、このようなコードには包括的な最適化が必要です。 すべてのGPGPU開発者は、メモリ操作が多くの場合プログラムの速度の最も弱いリンクであることを知っています。 自然界ではOpenCLをサポートするハードウェアプラットフォームが非常に多いため、メモリオブジェクトを整理する問題は頭痛の種になります。 ローカルメモリを備え、ワイドバスでグローバルに接続されているNvidia Teslaで適切に機能するものは、完全に異なるアーキテクチャを持つSoCで許容可能なパフォーマンスを示すことを拒否します。
この投稿では、共有メモリCPUおよびGPUを搭載したシステムのメモリ割り当ての機能について説明します。 画像メモリタイプの使用は避け、最も一般的なタイプのバッファに焦点を当てます。 標準として、バージョン1.1が最も一般的であると考えます。 初めに、短い理論コースを実施してから、いくつかの例を検討します。
理論
メモリは、clCreateBuffer API関数を呼び出すことによって割り当てられます。 構文は次のとおりです。
cl_mem clCreateBuffer ( cl_context context, cl_mem_flags flags, size_t size, void *host_ptr, cl_int *errcode_ret)
私たちは主に、メモリが正確に割り当てられる方法を担当するフラグに関心があります。 有効な値は次のとおりです。
最も簡単なオプション。 メモリは、読み取り/書き込み/書き込み専用/読み取り専用モードでOpenCLデバイス側に割り当てられます。CL_MEM_READ_WRITE CL_MEM_WRITE_ONLY, CL_MEM_READ_ONLY
オブジェクトのメモリは、ホストのメモリから、つまりメインメモリから割り当てられます。 このフラグは、共有CPUおよびGPUメモリを備えたシステムにとって重要です。CL_MEM_ALLOC_HOST_PTR
オブジェクトは、指定されたアドレスに既に割り当てられている(プログラムによって使用されている)ホストメモリを使用します。 この標準では、デバイスの側で中間バッファとしてメモリを割り当てることができます。 このフラグとCL_MEM_ALLOC_HOST_PTRは相互に排他的です。 完成したアプリケーションにOpenCLサポートを追加し、既存のメモリを使用してデバイス側で作業したい場合、このフラグは興味深いです。CL_MEM_USE_HOST_PTR
このフラグは、オブジェクトの作成時に、指定されたアドレスからアナログmemcpyが生成されることを意味します。CL_MEM_COPY_HOST_PTR
練習する
実際に、「オンボード」の独自のメモリとGPUがRAMのメモリを使用するディスクリートグラフィックカードの従来のケースに適したメモリ割り当てのオプションを見つけてみましょう。 次のコンピューターがテストシステムとして紹介されます。
- ディスクリートチップシステム:Intel Core i5 4200U、4Gb DDR31600Mhz、Radeon 8670M 128bit GDDR3 1800Mhz
- ビデオチップ内蔵システム:AMD A6700、8Gb DDR31800Mhx、Radeon 7660D 128bit
どちらの場合のオペレーティングシステムもWindows7 SP1であり、開発環境はVisual Studio 2013 Express + AMD APP SDK 2.9です。
テスト負荷として、さまざまなサイズ(65 Kb〜65 Mb)のメモリオブジェクトの読み取り/書き込みおよびマッピング/マッピング解除を行います。
考え直すことなく、チャートに移りましょう。 すべての場合において、横軸はメモリの量をバイト単位で示し、縦軸は操作を完了するまでの時間をマイクロ秒単位で示します。 ディスクリートメモリを搭載したビデオカードは、グラフの名前で「ディスクリートGPU」としてマークされ、CPUを備えた共有メモリを搭載したビデオカードは「Integrated GPU」としてマークされます。
ディスクリートグラフィックスカード

このグラフは、データ転送時間とボリュームの線形関係を示しています。 アダプタは独自のメモリを使用するため、結果は安定しています。
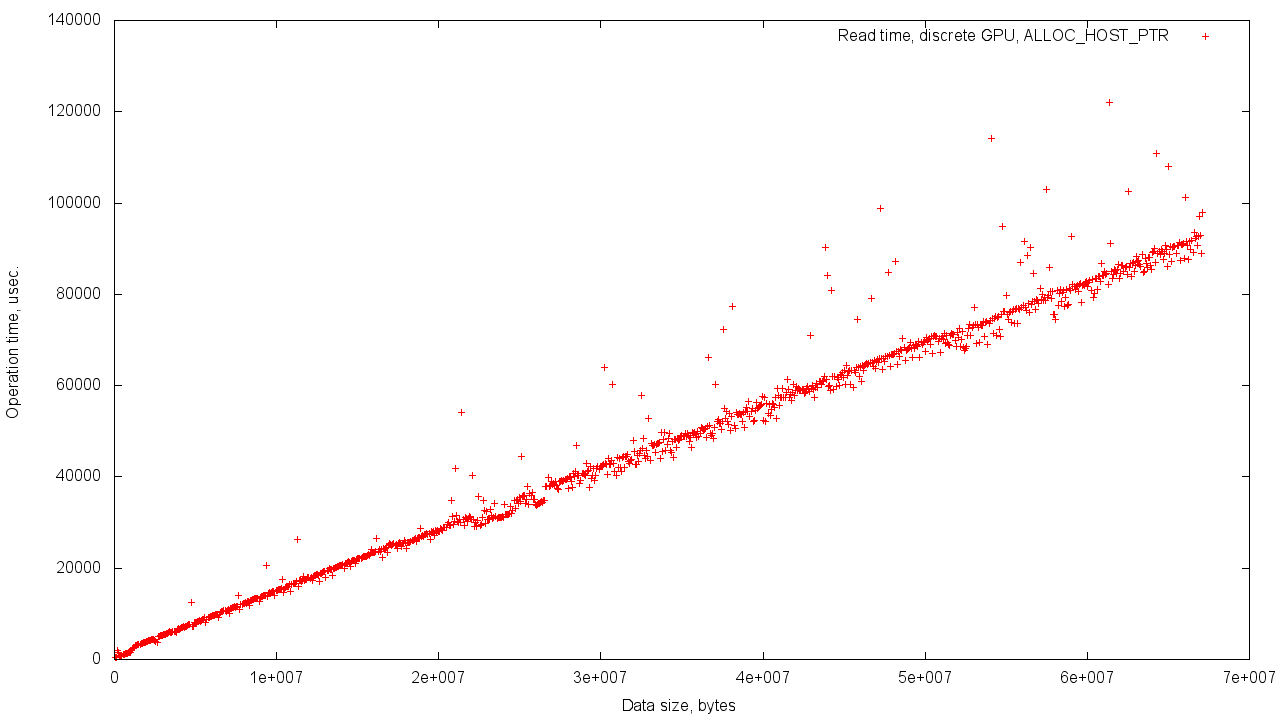
この場合、オブジェクトのメモリはオペレーショナルから割り当てられているため、値の範囲がわずかに大きくなります。
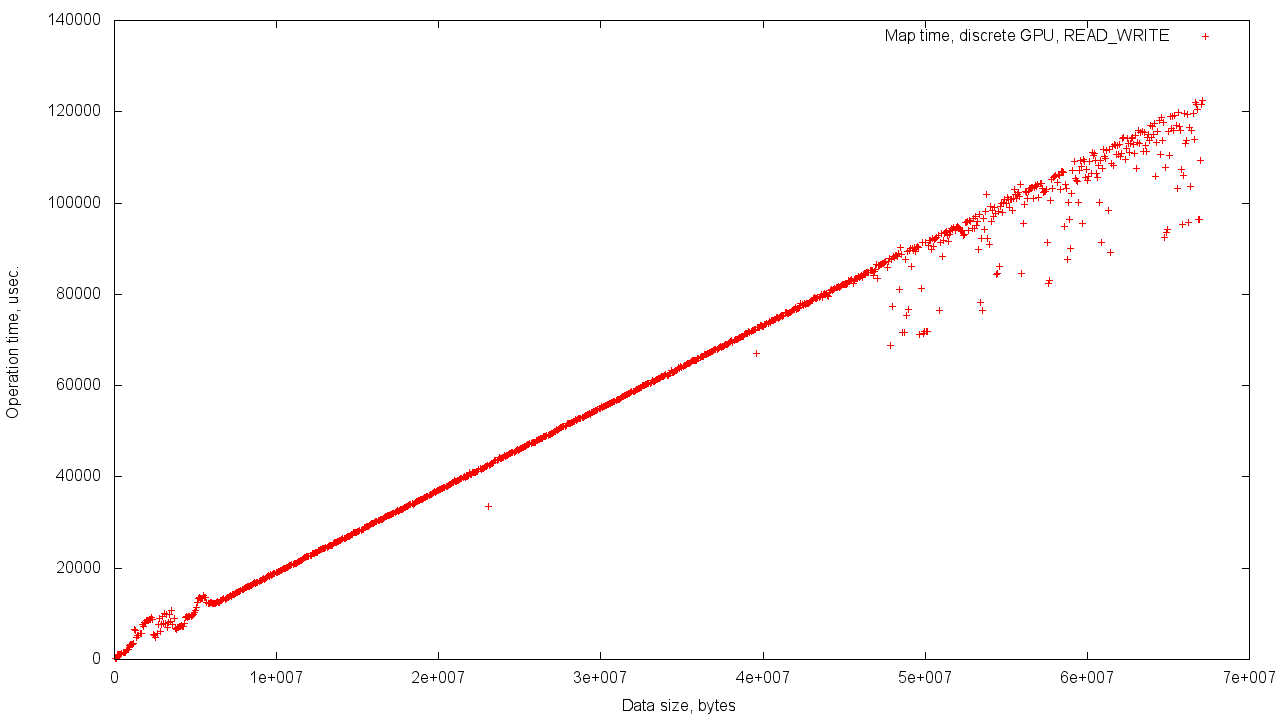

グラフは、GPUメモリから割り当てられたバッファのマッピング/マッピング解除を示しています。 マッピングは、メモリをデバイスのアドレス空間からホストの空間にマッピングする手順です。 マッピング解除は逆のプロセスです。 これらのアドレス空間は、独自のメモリを備えたGPUで物理的に異なるため、表示のために一時バッファへの読み取り/書き込みが行われるのはこのためです。
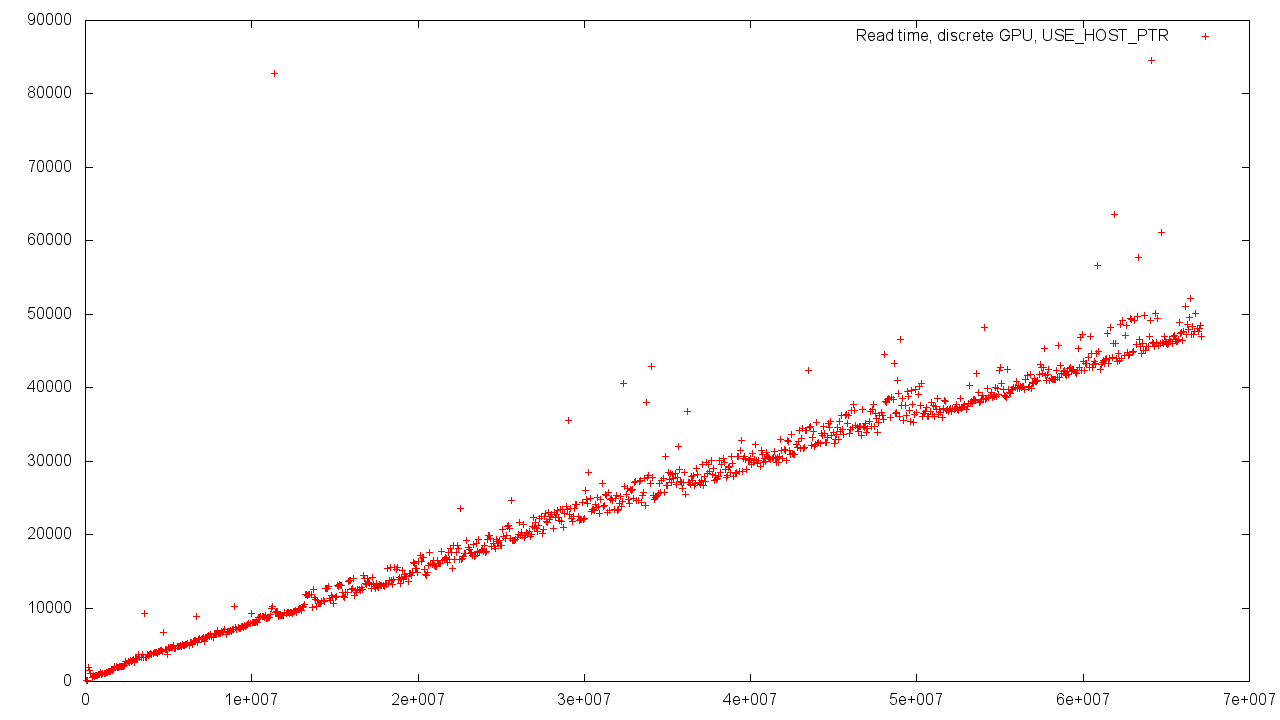

ホスト側に割り当てられた既存のメモリを使用する場合、時間の広がりはより重要です。 これには多くの理由があります-メモリを異なる基本値に揃えること、メモリコントローラの競合負荷など。
統合グラフィックスカード
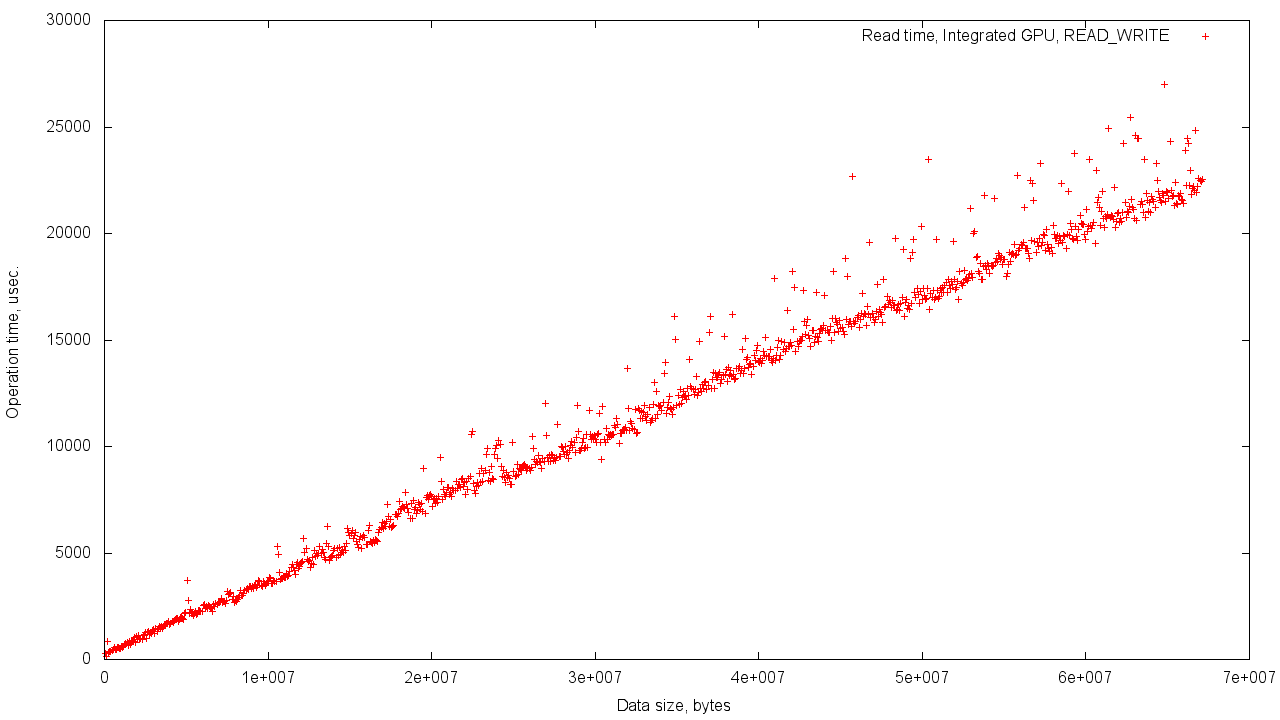
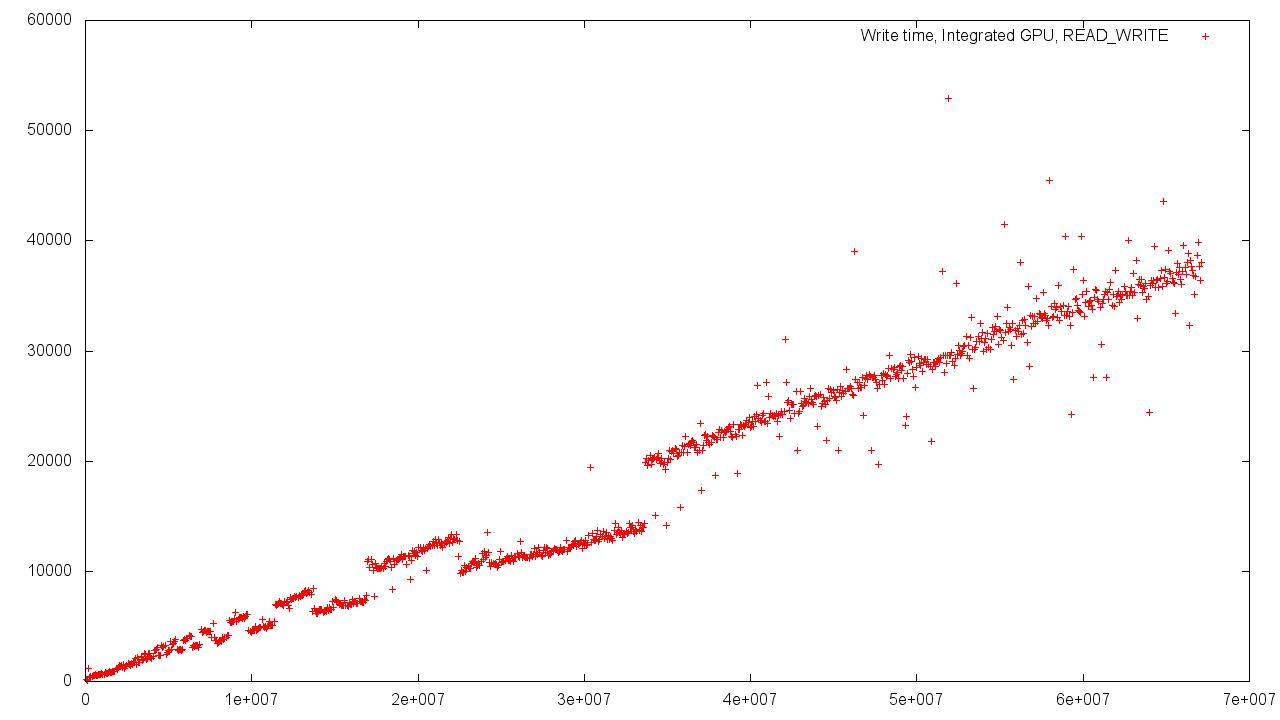
Host'aとDevice'aの間の共有メモリの場合、結果のばらつきはより強くなります。 これは、共有メモリを使用する必要性とコントローラーの負荷の増加によって簡単に説明できます。


RAMからメモリを割り当てる場合、デバイスとホストのメモリオブジェクトは同じ物理アドレス空間にあり、異なる仮想アドレスです。 したがって、アドレス変換時間は一定であり、オブジェクトのボリュームに依存しません。
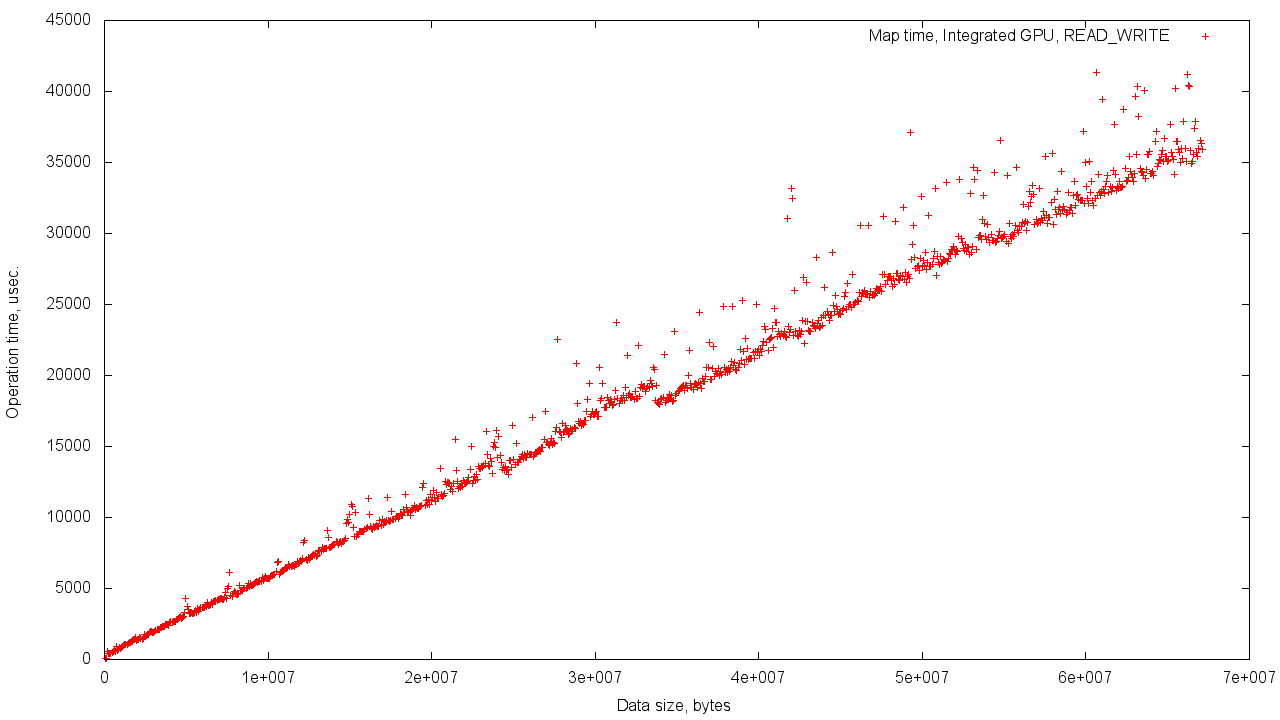
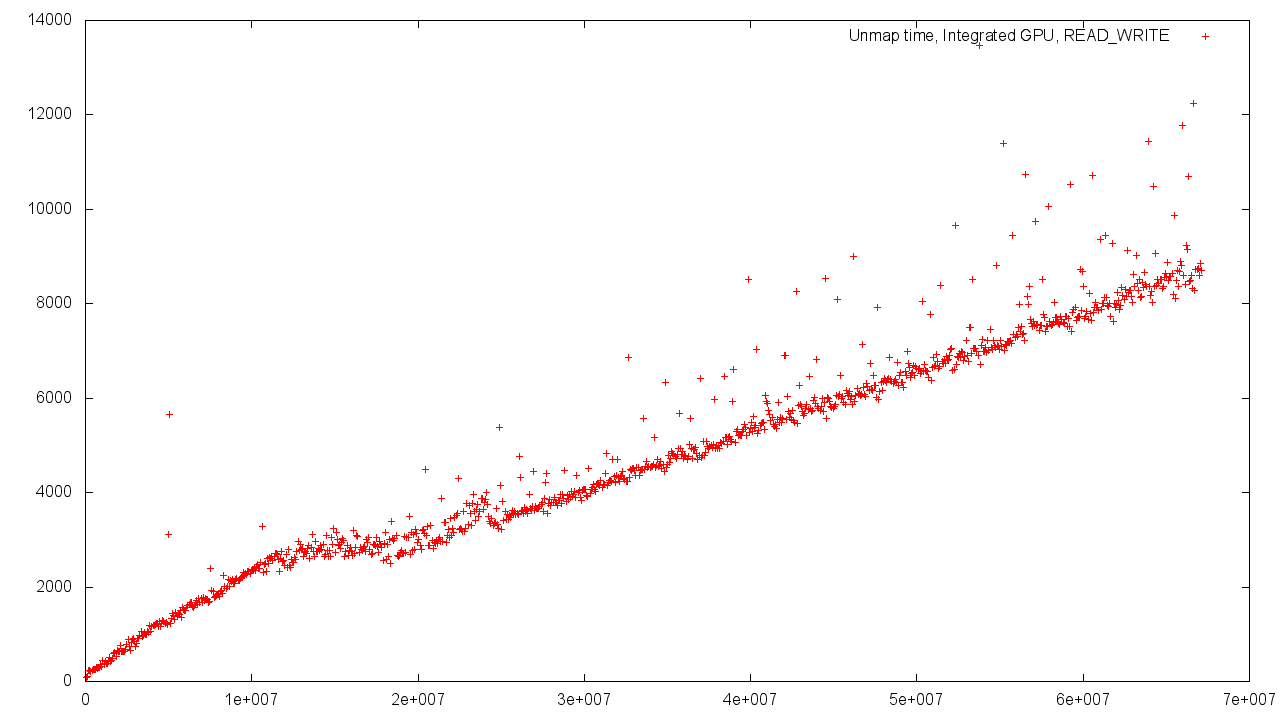
ただし、GPUメモリからオブジェクトにメモリを割り当てると、ランタイムのオブジェクトのボリュームへの依存性は、結果のばらつきが大きくなるように調整された個別のグラフィックスカードを使用する場合と同様になります。
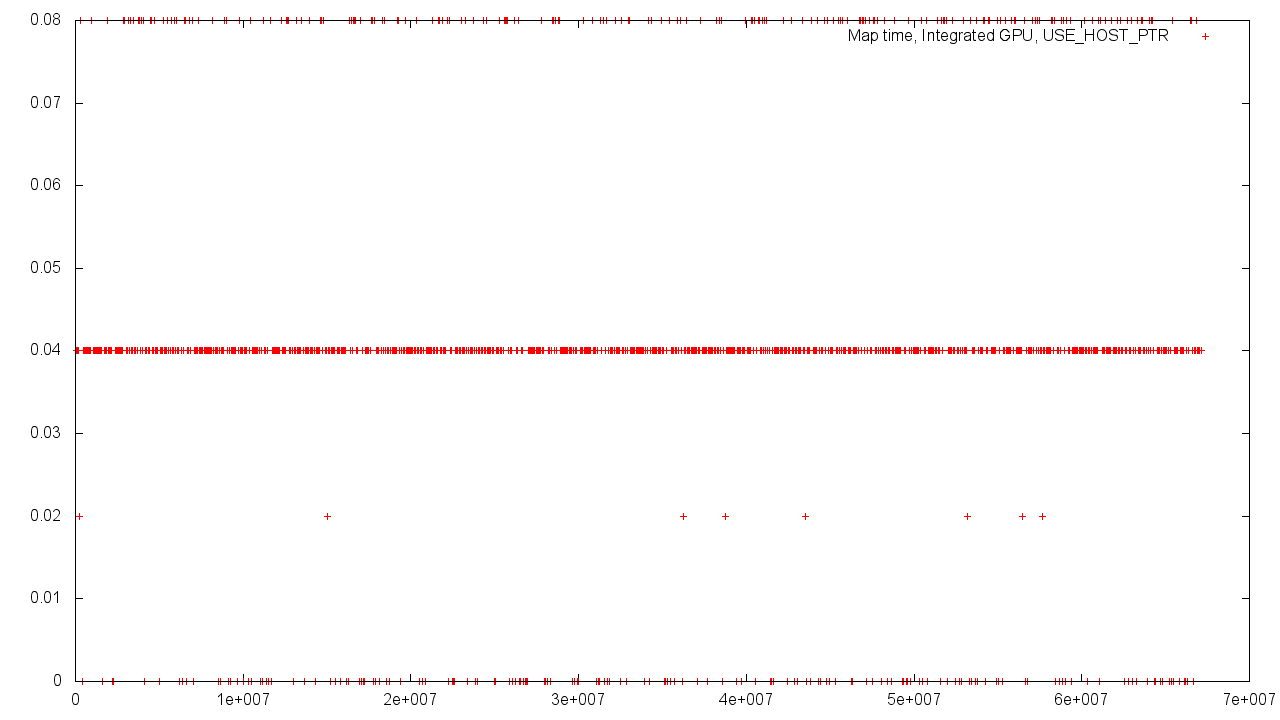
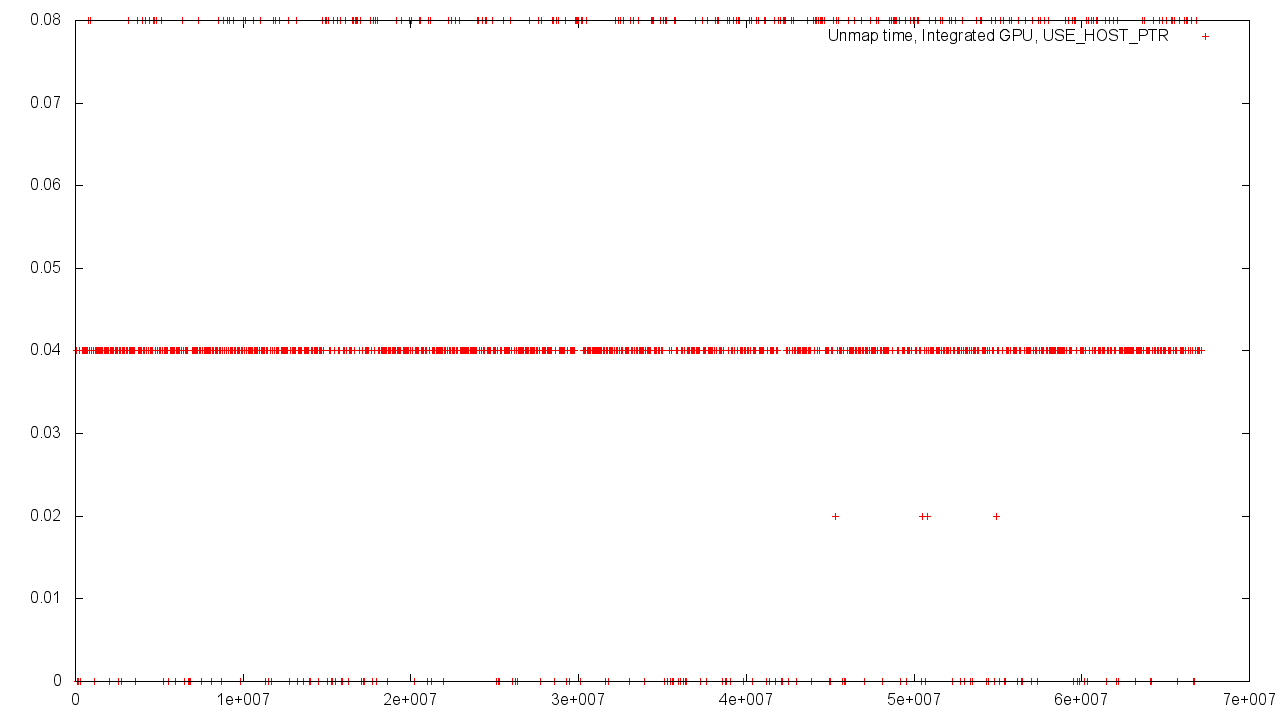
繰り返しますが、ホストによって割り当てられたメモリが使用されている場合、バッファサイズに関係なく、ほぼゼロの操作実行時間が得られます。
結論
実験中に特定された次のパターンに注目する価値があります。
- ディスクリートメモリを搭載したビデオカードを使用すると、ばらつきが少なくなります。 これは、共有メモリを使用しているためです。 それどころか、共有メモリを使用すると、インジケータのばらつきが大きくなります。
- どちらの場合でも、USE_HOST_PTRフラグを使用すると、不均一な結果が増加します。
OpenCLコアを集中アクセスモードで実行するにはディスクリートグラフィックカードのローカルメモリが望ましいという事実にもかかわらず、共有メモリを使用すると、バッファのサイズに関係なく、ほぼゼロの時間でマッピング/マッピング解除を実行できる場合があります。
マッピング手法は、両方の場合に使用できます。 共有メモリを備えたシステムでは、上記の利点が得られます;ディスクリートグラフィックカードを備えたシステムでは、従来の読み取り/書き込み回路と同じ線形時間で動作します。