
現在、かなりの数のインターフェースが利用可能であり、それぞれが有用で必要であると主張しています。 1G、10G、40Gを使用した従来のイーサネット。 InfiniBand FDR 56GおよびQDR 40G; FiberChannel 8G、16G、32Gを約束しました。
誰もが幸福を約束し、日常生活における彼らの極端な必要性と有用性について話します。 それをどうするか、何を選ぶか、落とし穴はどこにあるのか?
テスト方法:
各サーバーにあるすべてのギガビットの従来型に参加して、40Gイーサネット、QDRおよびFDR InfiniBand、10Gはかかりませんでした。 FCは離脱インターフェイスであると考えており、現在収束が進んでいることに注意してください。 32Gはまだ利用できません。16Gは高速ソリューションの仲間入りをしていません。
制限を明確にするために、HPCメソッドを使用して行うのに便利な最小遅延と最大スループットを達成するためのテストを実施し、同時にHPCアプリケーションに対する40Gイーサネットの適合性をテストしました。
セントラルコントロールセンターの同僚がフィールドテストを実施し、Intel ONSベースのスイッチをテスト用に提出したことにより、非常に貴重な支援が提供および実施されました。
ところで、最も興味深いプロジェクトへの切り替えの配布は継続しています。
ハードウェア:
- 40Gイーサネットスイッチ
- 通信アダプターMellanox ConnectX-3 VPIアダプターカード。 シングルポートQSFP; FDR IB(56Gb / s)および40GigE; PCIe3.0 x8 8GT / s
- Intel®Xeon®E5-2680 v2を搭載したデュアルプロセッサシステム
- OFED-3.5(Mellanoxのドライバーと低レベルライブラリ )
- ConnectX®EN 10および40ギガビットLinuxドライバー
ソフトウェア:
- パフォーマンス測定は、 Intel MPI Benchmark v3.2.3テストスイートの合成ピンポンテストを使用して実行されました。
- 使用されるMPIライブラリS-MPI v1.1.1のバージョンは、Open MPIのクローンです。
準備の過程で、Mellanoxアダプターのニュアンスが明らかになりました-イーサネットモードへの強制的な転送が必要です。 何らかの理由で、接続されたネットワークのタイプの自動決定の宣言された機能が機能しないため、修正できます。
「従来」のパフォーマンスを評価するために、長さ4バイトのメッセージを送信するためのレイテンシ値と、長さ4 MBのメッセージを送信するための帯域幅を調べます。
実験の始まり:
通常のイーサネットモードを使用します。 私たちの用語では、tcpファクトリーが使用されました。 つまり、MPIライブラリはメッセージの送信にソケットインターフェイスを使用します。 ドライバー、スイッチ、およびMPIのデフォルト構成。
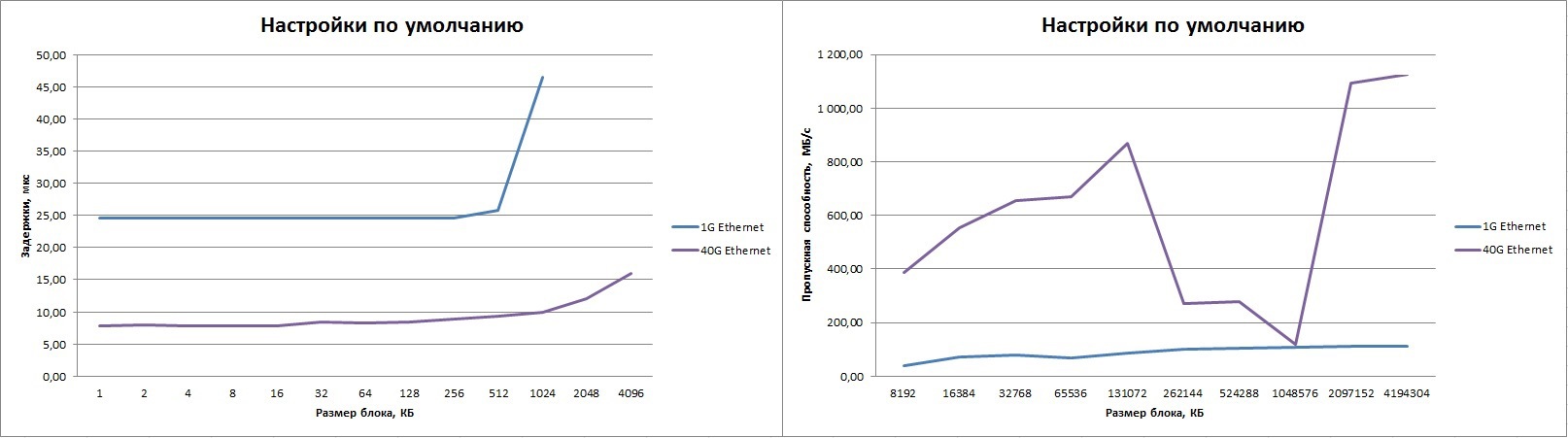
左側の表は1Gイーサネットの結果を示し、右側は40G(スイッチを使用)の結果を示しています。 256K-1Mメッセージストリップに「ディップ」が見られ、10Gイーサネットに適した最大の結果が得られます。 明らかに、ソフトウェアを構成する必要があります。 もちろん、遅延は非常に大きくなりますが、標準のTCPスタックを通過する場合、期待することが多く、それだけの価値はありません。 1Gイーサネットよりも3倍優れた敬意を払わなければなりません。
Mpirun –n 2 –debug-mpi 4 –host host01,host02 –nets tcp --mca btl_tcp_if_include eth0 IMB-MPI1 PingPong
| mpirun -n 2 -debug-mpi 4 -host host01,host02 -nets tcp --mca btl_tcp_if_include eth4 IMB-MPI1 PingPong
|
クリック可能:
私たちは続けます:
ドライバーを更新します。 メラノックスのウェブサイトからドライバーを取得します 。
256K〜1Mの範囲の「ドローダウン」を減らすには、MPI設定を使用してバッファーのサイズを増やします。
export S_MPI_BTL_TCP_SNDBUF=2097152
export S_MPI_BTL_TCP_RCVBUF=2097152
mpirun -n 2 -debug-mpi 4 -host host1,host2 -nets tcp --mca btl_tcp_if_include eth4 IMB-MPI1 PingPong
クリック可能:

その結果、改善は1.5倍になり、障害が減少しますが、それでも小さなものであり、小さなパケットの遅延でさえ大きくなりました。
もちろん、高速イーサネットインターフェイスを使用するときに帯域幅を改善するには、超長イーサネットフレーム(ジャンボフレーム)を使用するのが理にかなっています。 MTU 9000を使用するようにスイッチとアダプターを構成すると、著しく高い帯域幅が得られますが、帯域幅は20 Gb / sのままです。
クリック可能:
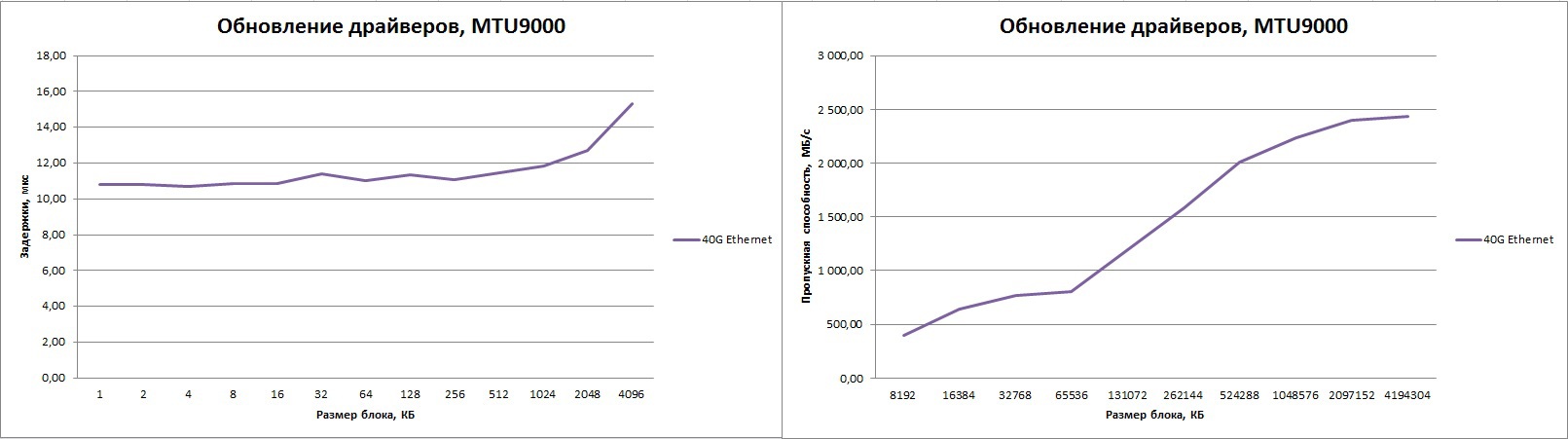
小さいパケットの遅延が再び増加しています。
他のパラメーターを変更しようとしましたが、根本的な改善はありませんでした。 一般的に、彼らは「彼らを調理する方法がわからない」と決めた。
どちらを見るか?
もちろん、パフォーマンスを探す場合は、TCPスタックをバイパスしてこれを行う必要があります。 明らかな解決策は、RDMAテクノロジーを試すことです。
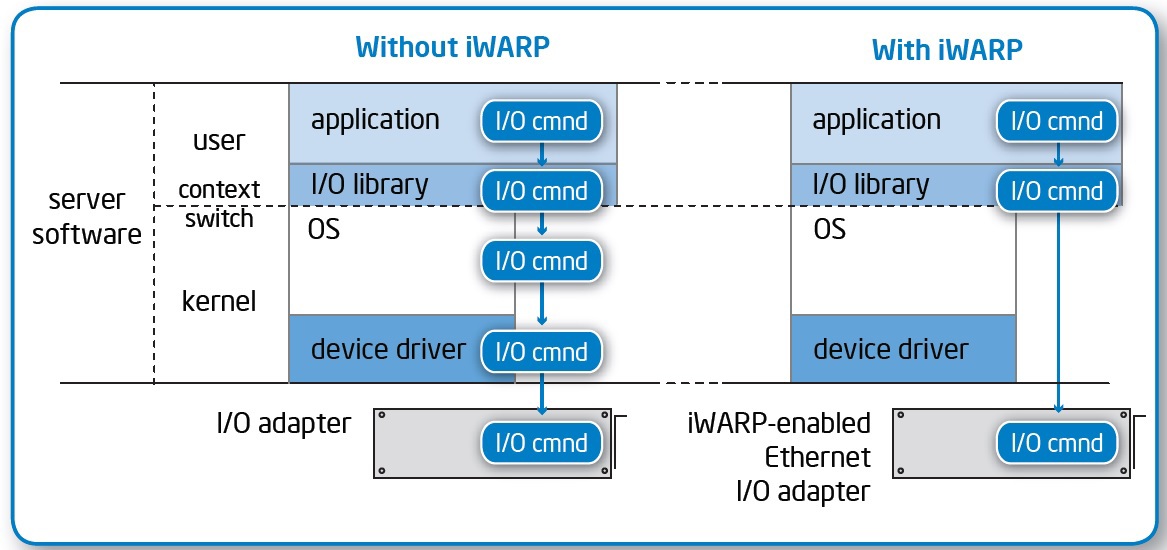
技術の本質:
- カーネルモードとユーザーモードの間でアプリケーションコンテキストを切り替えることなく、ユーザーの環境に直接データを配信します。
- アダプタからのデータは、中間バッファなしで、アプリケーションメモリにすぐに配置されます。
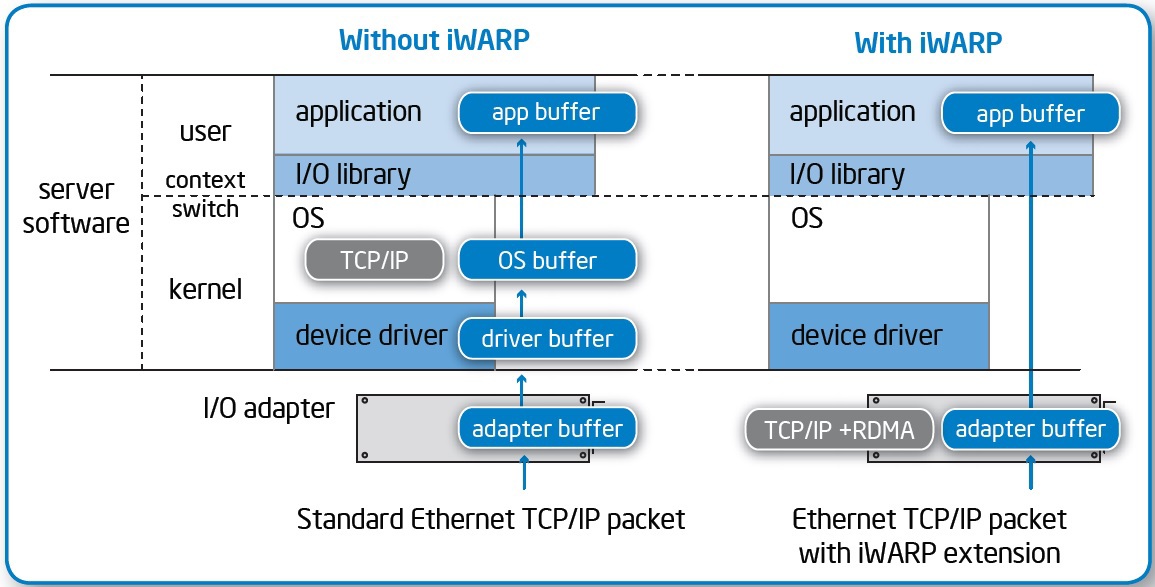
- ネットワークコントローラーは、プロセッサを使用せずにトランスポート層を処理します。
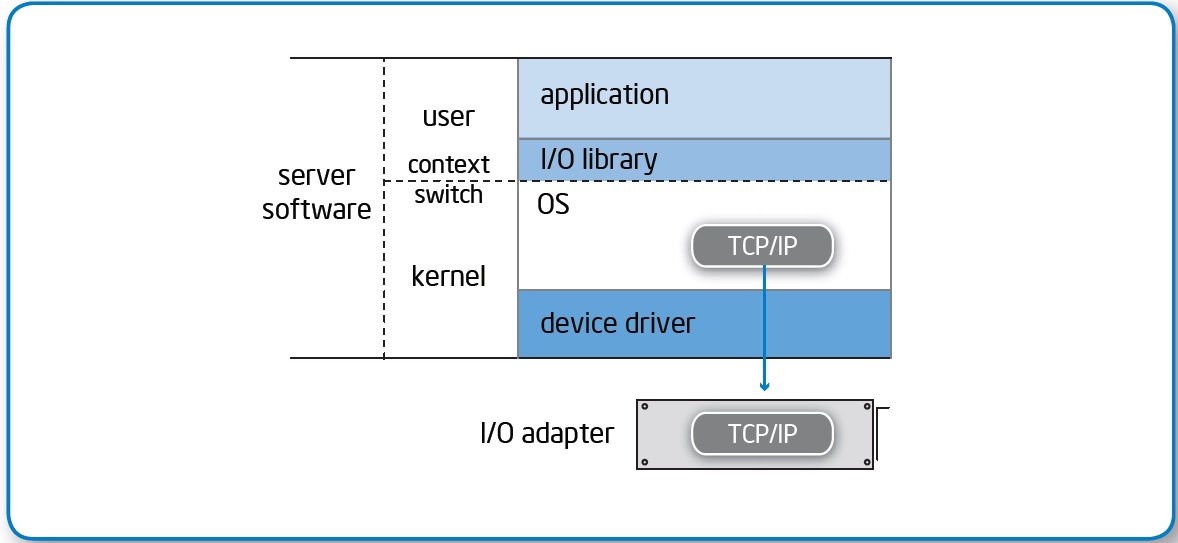
その結果、アクセス遅延が大幅に減少します。
競合する2つの標準、インターネットワイドエリアRDMAプロトコル(iWARP)とRDMA over Converged Ethernet(RoCE)があり、それらの競争とサポーターが互いにdrれようとする努力は、別のホリバーとボリュームのある素材に値します。 写真はiWARP用ですが、本質は一般的です。
MellanoxアダプターはRDMA over Converged Ethernet(RoCE)をサポートしています。OFED-3.5.2を使用しています。
その結果、優秀な数字が得られました。 遅延は1.9μsで、帯域は4613.88 MB / sです(これはピークの92.2%です!)ジャンボフレームを使用する場合。 デフォルトでMTUサイズのままにすると、帯域は低くなり、約4300 MB /秒になります。
mpirun -n 2 -debug-mpi 4 -host host1,host2 --mca btl openib,self --mca btl_openib_cpc_include rdmacm IMB-MPI1
クリック可能:
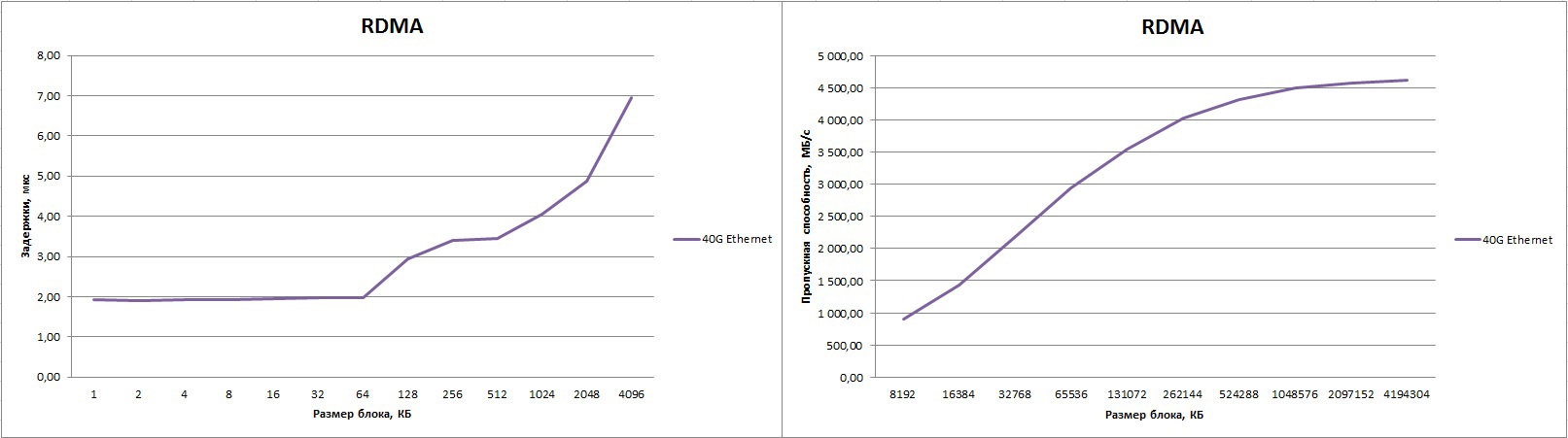
Pingpongテストでは、遅延時間を最大1.4μsまで改善できます;このため、プロセスはネットワークアダプターに「近い」CPUに配置する必要があります。 これは実際の生活でどのような実用的な意義がありますか? 以下は、小さなイーサネットの比較ラベルとInfiniBandです。 原則として、このような「トリック」は任意のインターコネクトに適用できるため、以下の表は一部のネットワークファクトリの値の範囲を示しています。
| 1Gイーサネット(TCP) | 40Gイーサネット(TCP) | 40Gイーサネット(RDMA) | InfiniBand QDR | InfiniBand FDR | |
| レイテンシー、usec | 24.5 | 7.8 | 1.4-1.9 | 1.5 | 0.86-1.4 |
| 帯域幅、メガバイト/秒 | 112 | 1126 | 4300-4613 | 3400 | 5300-6000 |
40GおよびFDRのデータは、プロセスが実行されているコアとネットワークアダプターを担当するコアとの距離に応じて変動します。何らかの理由で、この効果はQDRではほとんど見えません。
40GイーサネットはIB QDRを大幅に上回りましたが、IB FDRが絶対数に追い付かない前に、これは驚くことではありません。 ただし、40Gイーサネットは効率性でリードしています。
これから何が続きますか?
コンバージドイーサネットテクノロジーの勝利!
MicrosoftがRDMAに依存するSMBダイレクトの機能を着実に推進しているのも不思議ではありません; NFSにはRDMAサポートも組み込まれています。
ブロックアクセスを使用するには、ネットワークコントローラーにiSCSIオフロードテクノロジーがあり、RDMA(iSER)プロトコル用のiSCSI拡張機能があり、麻酔医はFCoEを試すことができます:-)
そのようなスイッチを使用する場合:

多数の興味深い高性能ソリューションを構築できます。
たとえば、40Gインターフェイスを備えたFS200 G3や10Gアダプターを備えたサーバーファームなどのソフトウェア構成のストレージシステム。
このアプローチでは、データ専用のネットワークを構築する必要がなく、ケーブルも接続して半分に敷設する必要があるため、スイッチの2番目のセットの費用とソリューションの展開時間の両方を大幅に節約できます。
合計:
- イーサネットでは、超低遅延の高性能ネットワークを構築できます。
- RDMAをサポートする最新のコントローラーを積極的に使用すると、ソリューションのパフォーマンスが大幅に向上します。
- Intelの400 nsのカットスルーレイテンシは素晴らしい結果を得るのに役立ちます:-)