
最後に、私は集まってこのシリーズの別の記事を書きました。 次に、Apache SolrでDrupalをロシア語で全文検索する方法について説明します。
- Apache Solrパート1でのDrupal 7検索-基本設定
- Apache SolrでのDrupal 7 Searchパート2-インデックスの調整方法の学習
- Apache SolrでDrupal 7を検索するパート3-カスタムフィールドとオプションをインデックスに追加する方法を学ぶ
- Apache Solrパート4-ファセットフィルターでDrupal 7を検索する
- Apache SolrによるDrupal 7の検索パート5-ファセットフィルターウィジェット
- Apache Solrパート6を使用してDrupal 7で検索する-Apache Solr + Tomcatを構成する
- Apache SolrによるDrupal 7検索パート7-ロシア語の全文検索
原則として、この資料はどの言語にも適用できますが、明らかな理由から、ロシア語を選択しました。 このシリーズの最初の記事の終わりに、ロシア語の検索を改善する方法について書きました。 この方法は簡単ですが、あまり効果的ではありません。 デフォルトで可能な最大値は、単語の終わりで動作することです。 簡単な例を考えてみましょう。 「気候」という言葉は、気候という言葉に含まれています。

しかし、すでに気候という言葉では結果はありません。
検索をより柔軟にするために、追加の辞書を接続します。 ステミングにHunspellStemFilterFactoryクラスを使用しました。
ここからロシア語の辞書をダウンロード-download.services.openoffice.org/files/contrib/dictionaries/ru_RU-pack.zip
ru_RU.affとru_RU.dicの2つのファイルが必要です。 それらはutf-8に変換する必要があります。そうしないと、apache solrはそれらで動作しません。
最初は、iconvを使用してエンコーディングを変更しようとしましたが、solrはそれらを使用しませんでした。
最後に、Krusaderを介してファイルをUTF-8に再保存しました-その後、すべてが正常に機能しました。
ファイルを変換したら、schema.xmlがある同じsolrフォルダーにファイルを配置する必要があります
スキーマ(schema.xml)で、HunspellStemFilterFactoryと辞書を使用することを示します。
<filter class="solr.HunspellStemFilterFactory" dictionary="ru_RU.dic" affix="ru_RU.aff" ignoreCase="true" />
<fieldType name="text" class="solr.TextField" indexed="true" stored="true" multiValued="true" positionIncrementGap="100"> <analyzer type="index"> ... <filter class="solr.HunspellStemFilterFactory" dictionary="ru_RU.dic" affix="ru_RU.aff" ignoreCase="true" /> ... <analyzer type="query"> ... <filter class="solr.HunspellStemFilterFactory" dictionary="ru_RU.dic" affix="ru_RU.aff" ignoreCase="true" /> ...
さらに、インデックスのアナライザーでHunspellStemFilterFactoryを定義した後、単語を部分(グラム)に分割するための設定を追加します。 これにより、検索がより柔軟になります。
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="25" side="front" /> <filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="25" side="back" />
ポーターフィルターを有効にしていた場合
<filter class="solr.SnowballPorterFilterFactory" language="Russian" protected="protwords.txt"/>
コメントアウトすることを忘れないでください。
solrをリロードして、コンテンツのインデックスを再作成します。 検索がはるかにうまく機能していることがわかります! 次に例を示します。
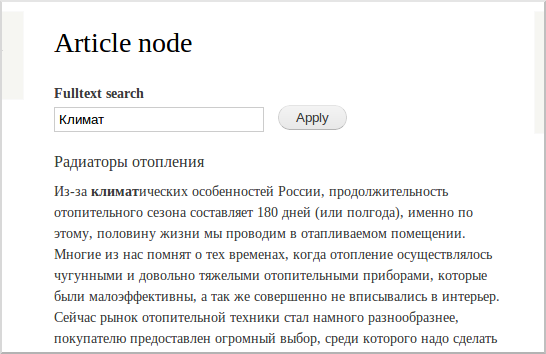

他の言語の辞書でも同じことができます。 辞書の全リスト-download.services.openoffice.org/files/contrib/dictionaries
既製の辞書を使用するだけでなく、独自のルールを作成することもできます。
ロシア語のsolrの辞書には「wombat」という単語がないことに気付き、追加することにしました。 これを行うには、最初にru_RU.affファイルに移動し、適切な結末を探します。 「wombat」という語の末尾はゼロであり、次の規則が適用されます。
SFX K 0 a [^ uoy]
SFX K 0 y [^ uoy]
SFX K 0オーム[^ ezhotschshsh]
SFX K 0 e [^ uoy]
SFX K 0 s [^ gezhyhokhshshsh]
SFX K 0および[gzhkhkhshshsh]
SFX K 0彼女
SFX K 0 s [^
SFX K 0 am [^ uoy]
SFX K 0 ami [^ uoy]
Sfx k 0 ah [^ uoy]
ウォンバット、ウォンバット...ウォンバット。
このエンディングのコードはKです。
ru_RU.dicファイルを開き、対応するコードで新しい単語を追加します

コードは、単語がどのように変化するかを説明します。 もちろん、スクリーンショットは単なる例であり、新しい単語をアルファベット順に挿入する必要があります。
solrをリロードし、コンテンツのインデックスを再作成して結果を確認します

私はapachesolr 3.6.1を使用していることを思い出します(これは重要ではありませんが、これまたは一部のバージョンでは動作しないことがあるという事実に出くわしました。 .xml)。
念のため、 スキームを添付します。何か問題が解決しない場合は、使用してみてください。