ゆっくりとインターネットをサーフィンして、私は運命の意志により、GEOTAR-Media Publishing Groupの一員であるLLC Polytechresursに命を吹き込んだサイト「Student Consultant」を見つけました。 私たちの将来の患者をよりよく知りましょう。
学際的な教育リソース「Student Consultant」(www.studentlibrary.ru)は、著作権所有者との直接契約に基づいて取得した教育文献および追加資料へのインターネットアクセスを提供する電子図書館システム(ELS)です。 このサイトは企業ユーザー向けです-大学、短大、およびその他の教育機関。有料でリソースのサブスクリプションを取得することにより、学生やスタッフに電子版の書籍の全文への無料アクセスを提供します。 個人のリソースへのアクセスは現在提供されていません。
さて、この大胆な発言がどのように真実であるかを確認しましょう。 サイトにアクセスして、 インターネット分析などのランダムな本を選択します。 Webリソース内の情報の検索と評価 。 「目次」を見てみると、サイトがレビュー用のいくつかのページを提供しており、登録を提案していることがわかります。

本のデモページは写真の形式で表示されますが、これはあまり面白くありませんが、各デモページの下部に次のリンクがあります。

開発者から親切に提供された機会を活用して、それについて突いてから、結果のページを調べます。
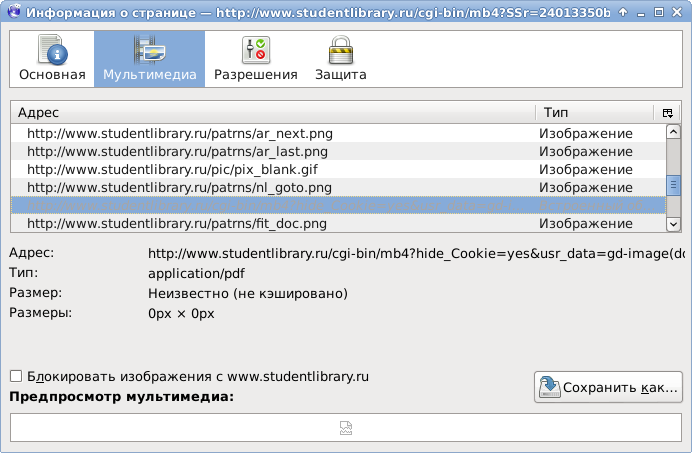
ページ上の画像の代わりに、非常に興味深いアドレスを持つ新しいオブジェクトが表示されたことがわかります。
www.studentlibrary.ru/cgi-bin/mb4?hide_Cookie=yes&usr_data=gd-image(doc,ISBN9785804105694-SCN0000,0002.pdf,-1,,00000000)
目次の次のページで同じことを行った後、別のリンクを取得します。
www.studentlibrary.ru/cgi-bin/mb4?hide_Cookie=yes&usr_data=gd-image(doc,ISBN9785804105694-SCN0000,0003.pdf,-1,,00000000)
明らかに、パラメータISBN9785804105694-SCN0000は本のISBNと章番号であり、0002.pdfと0003.pdfはページを担当するパラメータです。
したがって、サイトに登録しなくても、制限なしで章番号とページ番号を置き換えると、書籍のどのページも直接pdfで受け取ることができます。 唯一の不便は、各章に特定のページ番号があることです。 そして、このページが本のこの章に対応していない場合、サイトのメインページにリダイレクトされます。 したがって、この対応関係を経験的に排他的に決定する必要があります。
利便性を高めるために、ブックを個別のページとして保存する小さなスクリプトを作成します。
# -*- coding: utf-8 -*- import urllib import os def main(*argv): isbn = 'ISBN9785804105694' scn_amount = 3 page_amount = 78 for scn in range(0, scn_amount + 1): for current_page in range(0, page_amount + 1): current_page_formated = (4 - len(str(current_page))) * '0' + str(current_page) scn_formatted = (4 - len(str(scn))) * '0' + str(scn) url = 'http://www.studmedlib.ru/cgi-bin/mb4?hide_Cookie=yes&usr_data=gd-image(doc,' + isbn + '-' + 'SCN' + scn_formatted + ',' + current_page_formated + '.pdf,-1,,00000000)' print 'getting ', url urllib.urlretrieve(url, 'pages/' + str(scn) + '_' + str(current_page) + '.pdf') f1 = open('pages/' + str(scn) + '_' + str(current_page) + '.pdf', 'r') if '<HTML>' in f1.read(): os.remove('pages/' + str(scn) + '_' + str(current_page) + '.pdf') if __name__ == "__main__": main()
操作の原理は非常に不器用です:
- isbn-ISBNブック、
- scn_amount-チャプターの数、
- page_amount-ページ数。
各章のページ数はわからないため、すべてを並べ替えます。受け取ったファイルにhtmlタグがある場合、これは明らかにpdfページではないため、このファイルを削除する必要があります。 もちろん、結果のページをすぐに単一のpdfに接着することは可能ですが、経験上、ページは完全に連続して保存されておらず、手動で組み立てる必要があることが示されています(実際、最終的には皮肉の程度を知る必要があります)。
結論として、特定の結論は控えたいと思います。 誰もが自分で作ってみましょう。 この研究は情報提供のみを目的としており、著作権侵害や著作権侵害に対する控訴を構成するものではないことを思い出してください。