
衛星から画像を受け取った瞬間から、それを分析する可能性まで、視覚情報の取得とその後の分析に便利な形にするために、一連の手順を踏む必要があります。
プロセス自体に興味がある人は、猫(トラフィック)を求めます:
非常に本質に移る前に、私はすぐに多くの
デジタル画像自体とそれを取得するプロセス
誰もが知っているように、 デジタル画像はピクセルのマトリックスであり、それぞれの値は、空間座標(xおよびy)、波長、および時間の4つのコンポーネントの平均によって取得されます。
マトリックス自体をコンパイルするプロセスは次のようになります。太陽放射は撮影されたオブジェクトから反射され、センサーの表面に入射するエネルギーはそれによって固定され、その後積分され、そこから積分ピクセル値が設定されます。 整数値は、積分値を電気信号に変換した後に取得されます。 各ピクセルは、情報をバイナリ形式で保存します。 ピクセルごとに割り当てられるビット(メモリ)が多いほど、1ピクセルに対応する値の数が多くなるほど、元の離散信号がより正確に近似され、画像に格納できる情報が増えます。
CCDスキャナーでは、既に述べた検出器が地球をスキャンし、データの連続ストリームをピクセルに分割します。
多くはスキャナーのタイプに依存し、画像を取得する方法を決定します。 したがって、スキャナーには主に3つのタイプがあります。
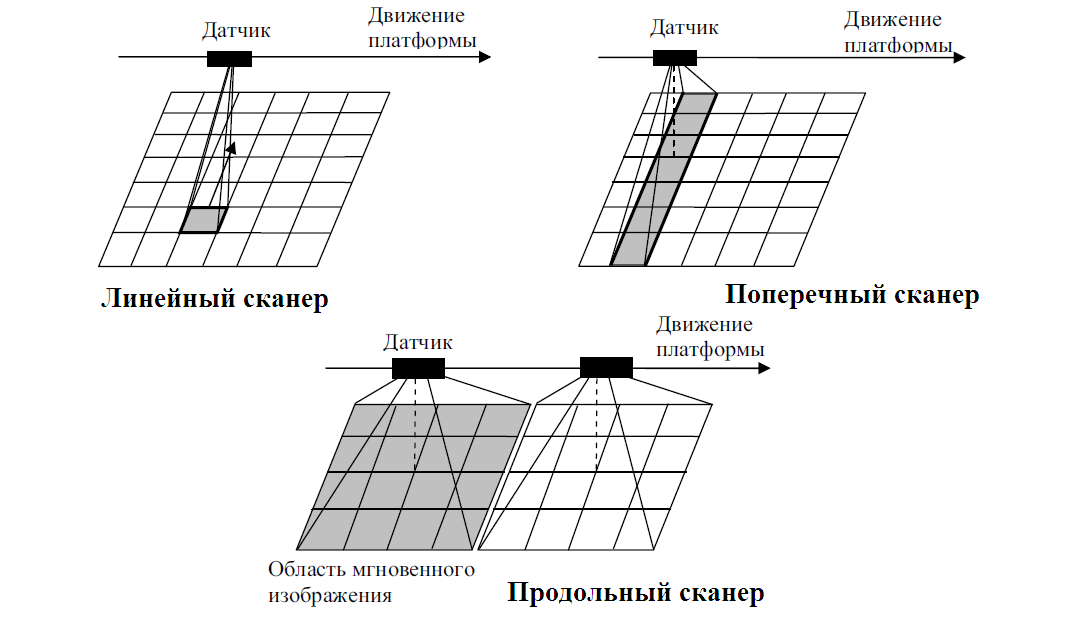
- リニアスキャナー (例-AVHRR)は最も単純なスキャナーで 、検出器要素が1つだけ装備されています。
- クロスCCDスキャナー (GOES、MODIS、TM)-スキャンのために調査経路に沿って配置された検出器のラインを使用します。 地球の並行スキャンは、各ミラーサイクルで実行されます。
- 縦型スキャナー (IKONOS、QuickBird、SPOT)にはCCDラインに数千の検出器があるため、軌道上でプラットフォームを移動するだけで並列スキャンが実行されます。
デジタルショットは 、8ビットグレースケールまたは24ビットスケールのいずれかを使用して表示されます。これは、R、G、Bの異なるシェードの混合に基づいています。元のピクセル値の範囲は、マルチスペクトルデジタル画像の3つのチャンネル。 1つのピクセルは256 ^ 3 RGBベクトルで表示され、1つのベクトルは1つの色です。 放射分解能には他のオプションがあります。 たとえば、QuickBirdには11ビット/ pix、Landsat-8には16ビット/ pixがあります。
光学センサーでのスペクトルチャネルの形成方法:
センサーが受信した光線は、いくつかの光線に分割されます。 独自の光路を通過する各ビームは、スペクトルフィルターを通過します。 スペクトル範囲を分離するには、プリズムと回折格子を使用できます。
予備的な画像処理手順
次の手順は、予備の画像処理サイクルに含まれています。
- 放射補正 -検出器の不適切な動作、地形および大気の影響の結果として発生するピクセル輝度値の変動を排除します。
- 大気補正 - 大気の影響を補正します。 大気の影響により、透明度ウィンドウによる撮影範囲の位置が決まります。
- 幾何学的補正には、縞、抜けライン、 ジオコーディングなどの画像の歪みの補正が含まれます。各画像ポイントが地面上の対応するポイントの座標に割り当てられるように画像をリンクします。 数学的には、ジオリファレンスは通常、べき多項式を使用して行われます。 参照ポイントが存在する場合、バインディングの精度が向上し、参照ポイントが存在するように見えます。 ジオコーディング後、すでに変換された画像の輝度特性は、最近傍、双線形補間、双三次たたみ込みなどのさまざまな方法で決定されます。
- オルソ補正 -地形の標高の違いに起因する画像エラーを排除します。その結果、結果として得られる画像から中心設計の多くの欠陥が排除されます。
以下は、画像品質を改善するためのプロセスです。
- スペクトル変換 -画像のピクセル数とスペクトル輝度の値との関係を示すグラフであるスペクトル図を使用して作成されます。 スペクトル変換では、 コントラストなどのパラメーターが変化します。 これを増やすには、次のようないくつかの方法があります。
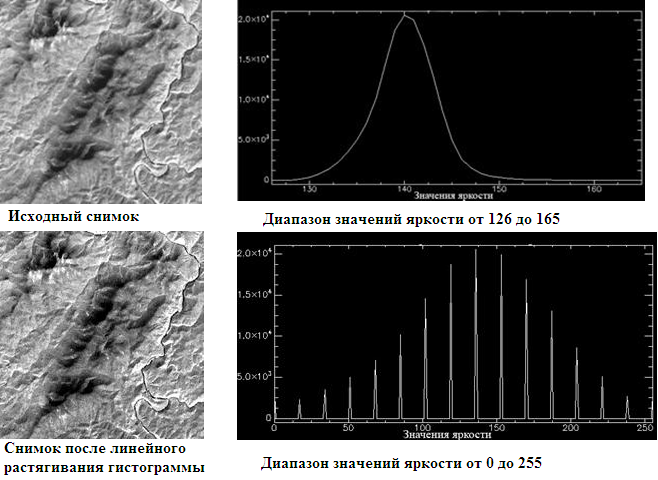
- 0から255までの可能な範囲全体をカバーするために、すべての輝度値に新しい値が割り当てられるという事実から成る、ヒストグラムの線形ストレッチング:
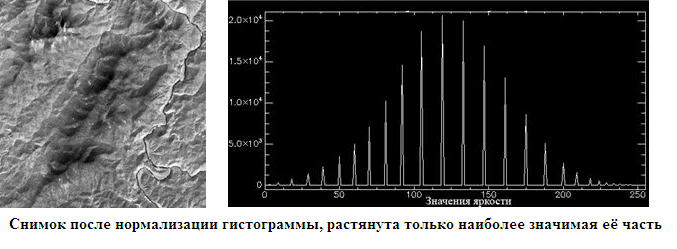
- ヒストグラムの正規化-ダイアグラムの最も強度のある(最も情報量の多い)セクションのみが、輝度値の範囲全体に引き伸ばされます。
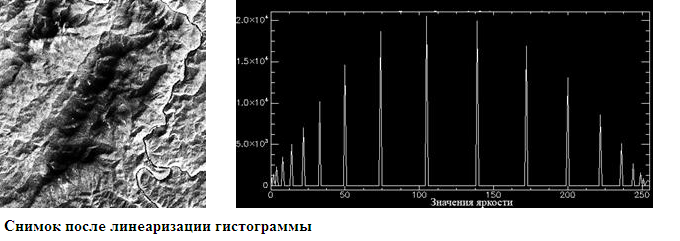
- ヒストグラムの線形化-各輝度レベルがほぼ同じピクセル数になるように、各ピクセルに新しい輝度値が割り当てられます。
- 0から255までの可能な範囲全体をカバーするために、すべての輝度値に新しい値が割り当てられるという事実から成る、ヒストグラムの線形ストレッチング:
- フィルタリング -オブジェクトの再現性を高め、ノイズを除去し、構造線を強調し、画像を滑らかにし、タスクに応じてさらに多くを行います。 フィルタリングプロセス全体は、 スライディングウィンドウの概念に基づいています -重み係数の正方行列(通常は3 * 3または5 * 5行列)。 各ピクセルの輝度値は次のように再計算されます:ピクセルがピクセルからイメージピクセルに移動するウィンドウの中心にある場合、周囲のピクセルの値の関数依存性によって計算される新しい値がそれに割り当てられます。 そのため、ウィンドウは画像のすべてのピクセルにわたって「スリップ」し、その値を変更します。 選択した重みに応じて、結果の画像のプロパティが変わります。 より詳細なフィルタリングについては、UnickSoft Habrauserの投稿で説明されています。
- フーリエ変換は、多くの空間周波数成分に分解することにより、画像の品質を向上させます。 空間内の輝度特性の分布は、周波数領域で与えられた特性を持つ周期関数sinとcosの線形結合として表されます。 たとえば、ノイズを除去するには、発生頻度を特定するだけで十分です。
画像の操作の最終段階-復号化
復号化は、画像内のオブジェクトと地形現象を検出および認識するプロセスです。 画像の視覚的(人間)評価に基づく手動、または機械(自動)のいずれかです。 後者は、私に伝えてくれますが、多くのHabrausersにとって大きな関心事です。 本質的に、機械処理はさまざまな分類メカニズムに帰着します。 まず、すべてのピクセル(スペクトルの明るさ)を、スペクトルフィーチャの空間内のベクトルとして想像する必要があります。 さまざまなオブジェクトのスペクトル輝度の定量的関係を分析する場合、ピクセルはクラスに分割されます。 写真の分類は、トレーニングありの分類とトレーニングなしの分類に分けられます。
トレーニングによる分類
トレーニングによる分類は、各ピクセルの輝度を比較する標準の存在を意味します。 その結果、いくつかの標準が事前に定義されているため、多くのオブジェクトがクラスに分割されます。 この分類は、画像に表示されるオブジェクトが事前にわかっていて、クラスが明確に区別され、その数が少ない場合にのみ機能します。
以下は、トレーニング付きの分類で使用できる方法のほんの一部です。
- 最小距離法 -ピクセル輝度値は、スペクトルフィーチャの空間内のベクトルと見なされます。 これらの値と参照セクションのベクトルの値の間で、スペクトル距離は、ピクセルと参照のベクトルの差の二乗和の根として計算されます(言い換えれば、それらの間のユークリッド距離)。 すべてのピクセルは、ピクセルと参照の間の距離が指定を超えているかどうかに応じてクラスに分割されます。 そのため、距離が短い場合、クラスが定義され、ピクセルは標準に帰属します。

- マハラノビス距離法は最初の方法と非常に似ています。分類のみがベクトル間のユークリッド距離を測定せず、標準の輝度値の分散を考慮したマハラノビス距離を測定します。 このメソッドでは、指定されたピクセルから2つの標準までのユークリッド距離が等しい場合、参照サンプルの分散が大きいクラスが勝ちます。
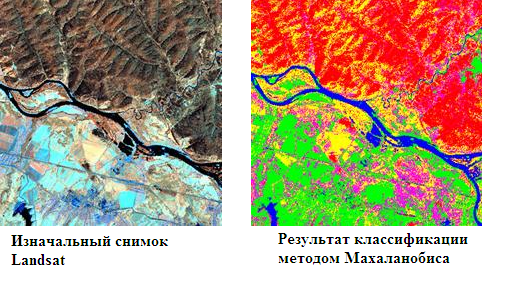
- スペクトル角法 -最初に、スペクトル角の最大値(参照ベクトルとこのピクセルのベクトル間の角度)が設定されます。 スペクトル角度が見つかり、ユークリッド距離と同様に、角度が指定された角度よりも小さい場合、ピクセルは比較が行われる標準クラスに分類されます。
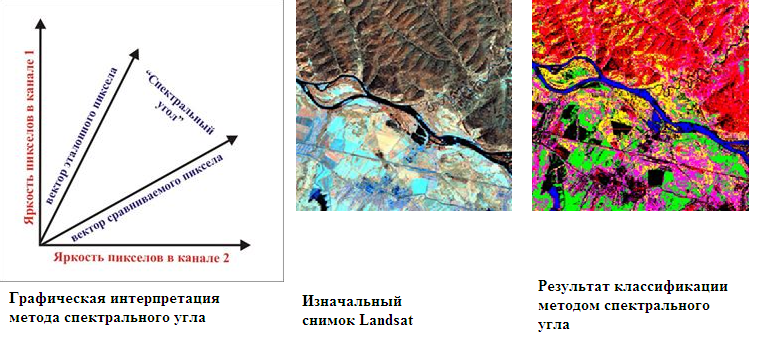
トレーニングなしの分類
トレーニングなしの分類は、ピクセルの輝度値の分布に関する統計に基づくクラスへのピクセルの完全自動分布に基づいています。 このタイプの分類が使用されるのは、画像内に存在するオブジェクトの数が最初にわからない場合、オブジェクトの数が多く、その結果、マシンが受信したクラスを発行し、どのオブジェクトと一致させるかをすでに決定している場合です。
- ISODATA(反復自己組織化データ分析手法アルゴリズム)メソッドは、逐次近似法を使用したクラスター分析に基づいています。 ピクセルの明るさをスペクトルフィーチャの空間内のベクトルとして考慮した後、最も近いものが1つのクラスで決定されます。 各スペクトルゾーンについて、輝度分布の統計パラメーターが計算されます。 すべてのピクセルは、n個の等しい範囲で分割され、それぞれの範囲は平均値です。 範囲内の各ピクセルについて、平均値までのスペクトル距離が計算されます。 最小距離を持つすべてのピクセルは、1つのクラスターで定義されます。 これが最初の反復です。 2回目以降は、各クラスターの実際の平均値がすでに計算されています。 新しい反復ごとに、将来のクラスの境界が改善されます。

- K-meansメソッドは、最初の平均が設定されているという事実を除いて、以前のメソッドと似ています(これは、画像内のオブジェクトが読みやすい場合のみ可能です)。
画像の前処理と品質の向上、復号化のすべてのプロセスは、議論のための巨大な分野を表しており、それぞれが記事全体の機会として機能します(1つではありません)。 特定のトピックに興味がある人は、コメントの後続のプロットの開発にご希望を残してください。 さらに、栄養NDVIなどのさまざまな指標の使用に関する記事が計画され、オブジェクトの解釈と識別が改善されます。
この記事では、サイトの情報を使用しましたが、次のソースも使用しました: 1および2 。
PS。 米国地質調査所のウェブサイトから無料でデジタルデータをダウンロードできます。
画像処理の独自の実験用に、 無料のデモソフトウェア (フルバージョンと比較して機能が制限されていますが、ウォームアップには十分です)ともう1つのソフトウェアがあります。