
過去数年間にリリースされたほとんどすべてのパーソナルコンピューターには、少なくともデュアルコアプロセッサが搭載されています。 読者が非常に古いコンピューターや予算の少ないラップトップではない場合、おそらくマルチプロセッサーシステムの所有者です。 それでもゲームをプレイしたい場合は、約100のGPUコアにアクセスできます。 ただし、このすべての力がほこりを集める時間の大部分を占めています。 修正してみましょう。
はじめに
ごくまれに、複数のプロセッサー(またはコア)のフルパワーを使用して日常のタスクを解決し、強力なGPUの使用がコンピューターゲームに帰着することがよくあります。 個人的に、私はそれが好きではありません。私は働いています-なぜプロセッサを休ませるのですか? 混乱。 マルチプロセッサ(マルチコア)のすべての機能と利点を考慮し、可能なすべてを並列化して、時間を大幅に節約する必要があります。 また、ボード上の何百ものコアを備えた強力なビデオカードも接続する場合、これはもちろん狭い範囲のタスクにのみ適合しますが、それでも計算を非常に大幅に高速化します。
Linuxはこの点で非常に強力です。 第一に、すぐに使えるほとんどのディストリビューションでは、並列実行に適したツールを使用できます。第二に、マルチコアシステムを念頭に設計された多くのソフトウェアが記述されています。 設定の柔軟性について話す必要さえありません。 発生する可能性のある唯一の問題は、ビデオカードのドライバーですが、何もする必要はありません。
まず、並列化の方法を決めましょう。 それらの2つがあります:タスクを完了するためにいくつかの並列スレッド(マルチスレッド)を起動するアプリケーション自体によって。 別の方法は、アプリケーションの複数のコピーを実行することです。各コピーは、データの特定の部分を処理します。 この場合のオペレーティングシステムは、コアまたはプロセッサ間でプロセスを独立して分散します(マルチタスク)。
ターミナルで直接並列化します
端末ウィンドウから直接プロセスを並列起動することから始めましょう。 ターミナルで長時間実行されているプロセスを実行しても問題はありません。 しかし、このようなプロセスが2つ必要な場合はどうでしょうか? 「問題ではありません」と言います、「2番目のプロセスは別のターミナルウィンドウで開始するだけです」 そして、あなたは10以上を実行する必要がある場合はどうなりますか? うーん...最初に思い浮かぶのは、xargsユーティリティを使用することです。 彼女にオプション--max-procs = nを与えると、ソフトウェアは同時にn個のプロセスを実行します。 公式マニュアルでは、引数によるグループ化と--max-procsオプション(オプション-n)の使用を推奨しています。これがないと、並列起動で問題が発生する可能性があります。 たとえば、多数の大きな(または小さな)ファイルをアーカイブする必要があるとします。
$ cd folder/with/files $ ls | xargs -n1 --max-procs=4 gzip
どれくらいの時間を獲得しましたか? これを気にする必要がありますか? ここでは、番号を指定するのが適切です。 クアッドコアプロセッサでは、それぞれが約400 MBの5つのファイルの通常のアーカイブに1分40秒かかりました。
xargs --max-procs=4
を使用する
xargs --max-procs=4
経過時間がほぼ4倍に短縮されました(34秒)。 質問に対する答えは明らかだと思います。
もっと面白いものを試してみましょう。 たとえば、lameを使用してWAVファイルをMP3に変換します。
$ ls *.wav | xargs -n1 --max-procs=4 -I {} lame {} -o {}.mp3
厄介に見えますか? 同意します。 ただし、プロセスの並列実行はxargsの主なタスクではなく、その機能の1つにすぎません。 さらに、xargsは、スペースや引用符などの特殊文字ではあまりうまく動作しません。 そして、ここでGNU Parallelという素晴らしいユーティリティが私たちの助けになります。 Softinaは標準のリポジトリで使用できますが、そこからインストールすることはお勧めしません。たとえば、Ubuntuリポジトリでは、2年前にバージョンに遭遇しました。 ソースから新しいバージョンをコンパイルすることをお勧めします:
$ wget ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2 $ tar xjf parallel-latest.tar.bz2 $ cd parallel-20130822 $ ./configure && make # make install
ユーティリティ自体の名前は、その狭い専門性を物語っています。 実際、Parallelは並列化に非常に便利であり、その使用はより論理的に見えます。 xargsの代わりにParallelを使用した上記の例は、次のようになります。
$ ls *.wav | parallel lame {} -o {}.mp3
ところで、UbuntuまたはKubuntuの下に座っている場合、この例は機能せず、奇妙なエラーが発生します。 これは、キー '--gnu'を追加することで修正されます(次の例に適用)。 問題の詳細については、 こちらをご覧ください 。
そして、なぜ同時に実行されるプロセスの数を設定しないのですか? Parallelが私たちのためにそれを行うので、コアの数を決定し、カーネルでプロセスを実行します。 もちろん、-jオプションを使用してこの番号を手動で設定することもできます。 ところで、異なるマシンでタスクを実行する必要がある場合、移植性を向上させるには、このオプションを-j +2形式で設定すると便利です。この特定の場合は、「システムにコンピューティングユニットがあるよりも2つのプロセスを同時に実行する」ことを意味します。
PythonとParallelの友達を作ると、並列タスクのための強力なツールが手に入ります。 たとえば、WebからWebページをダウンロードし、その後の処理は次のようになります。
$ python makelist.py | parallel -j+2 'wget "{}" -O - | python parse.py'
しかし、Pythonがなくても、このユーティリティには多くの機能があります。 必ずmanを読んでください-興味深い例がたくさんあります。
もちろん、Parallelとxargsに加えて、同様の機能を持つユーティリティは他にもたくさんありますが、最初の2つではできないことは何も知りません。
私たちはそれを理解しました。 先に進みます。
並列コンパイル
ソースから何かを収集することは、Linuxで一般的なことです。 ほとんどの場合、重要ではない何かを収集する必要があります。そのようなプロジェクトでは、並列コンパイルは考えられません。 しかし、時にはより大きなプロジェクトに出くわし、ビルドが完了するのを待つのにほとんど永遠を要します。例えば、ソース(1スレッドで)からAndroid(AOSP)をビルドするには、約5時間かかります。 そのようなプロジェクトでは、すべてのコアを使用する必要があります。
まず、コンパイル自体(GCCなど)が並列化されていないことは明らかだと思います。 しかし、大規模なプロジェクトは、多くの場合、同時にコンパイルできる、またコンパイルする必要のある多数の独立したモジュール、ライブラリ、およびその他のもので構成されています。 もちろん、コンパイルを並列化する方法について考える必要はありません。makeがこれを処理しますが、makefileに依存関係が書き込まれている場合にのみです。 そうしないと、makeはどの順序でアセンブルするのか、何を同時に収集できるのか、何を収集できないのかを知りません。 また、メイクファイルは開発者の関心事であるため、私たちにとってはすべてコマンドの実行に帰着します
$ make -jN
その後、makeはプロジェクトの構築を開始し、同時に最大N個のタスクを起動します。
ところで、-jオプションの値の選択について。 Webでは、多くの場合、1.5 * <コンピューティングユニットの数>を使用することをお勧めします。 しかし、これは必ずしも真実ではありません。 たとえば、クアッドコアで総重量250 MBのプロジェクトをビルドするのは、-jパラメーター値が4の場合に最速でした(画面を参照)。
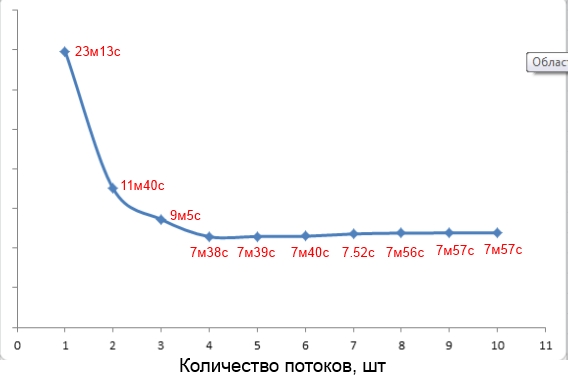
コンパイル時間のパラメーター値への依存
さらに時間を稼ぐために、-pipeスイッチをGCCに追加できます。 このキーを使用すると、コンパイルのさまざまな段階間でのデータ転送が一時ファイル経由ではなくパイプ経由で行われるため、プロセスが少し(非常に)速くなります。
makeに加えて、Pythonで作成された並列ビルドシステムであるpmakeを試すこともできます。 juzvereysの場合、その使用はmakeとそれほど変わりませんが、標準ツールよりも広範な機能を備えているため、開発者にとっては非常に興味深い場合があります。
並列Rsync
Rsyncを使用して膨大な数の小さなファイルをリモートサーバーと同期したことがある場合、受信ファイルリストの段階でかなりの遅延が発生していることに気付いたでしょう。 この段階は並列化によって加速できますか? もちろんできます。 ネットワークの遅延に多くの時間が費やされます。 これらの一時的な損失を最小限に抑えるために、Rsyncのコピーをいくつか実行し、同じファイルがコピーされないように、各コピーをたとえば別のディレクトリに設定します。 これを行うには、-includeオプションと--excludeオプションの組み合わせを結合します。たとえば、次のようになります。
$ rsync -av --include="/a*" --exclude="/*" -P login@server:remote /localdir/ $ rsync -av --include="/b*" --exclude="/*" -P login@server:remote /localdir/
異なる端末で複数のコピーを手動で開始できますが、パラレルに接続できます。
$ cat directory_list.txt | parallel rsync -av --include="/{}*" --exclude="/*" ...
SSH Turbo Jetファイルコピー
通常、2つのホスト間でディレクトリを同期するには、SSHの上でRsyncを実行します。 SSH接続を高速化して、Rsyncの作業を高速化します。 また、SSHはOpenSSH HPNパッチセットを使用することで高速化できます。これにより、SSHのサーバー部分とクライアント部分をバッファリングするメカニズムのボトルネックが解消されます。 さらに、HPNはAES-CTRアルゴリズムのマルチスレッドバージョンを使用します。これにより、ファイルの暗号化速度が向上します(
-oCipher=aes[128|192|256]-ctr
によってアクティブ化されます)。 OpenSSH HPNがインストールされているかどうかを確認するには、ターミナルに入力します。
$ ssh -V
HPN部分文字列エントリを探します。 通常のOpenSSHがある場合は、次のようにHPNバージョンをインストールできます。
$ sudo add-apt-repository ppa:w-rouesnel/openssh-hpn $ sudo apt-get update -y $ sudo apt-get install openssh-server
次に、行を
/etc/ssh/sshd_config
追加し
/etc/ssh/sshd_config
。
HPNDisabled no TcpRcvBufPoll yes HPNBufferSize 8192 NoneEnabled yes
その後、SSHサービスを再起動します。 次に、Rsync / SSH / SCP接続を再度作成し、ゲインを評価します。

HPNサポートを有効にする
ファイル圧縮
上記で行ったすべての加速は、同じプロセスの複数のコピーの同時起動に基づいています。 オペレーティングシステムのプロセススケジューラは、マシンのコア(プロセッサ)間のこれらのプロセスを解決しました。これにより、アクセラレーションが得られました。 いくつかのファイルを圧縮した例に戻りましょう。 しかし、1つの巨大なファイルを圧縮し、さらにbzip2を遅くする必要がある場合はどうでしょうか? 幸い、ファイル圧縮は並列処理に非常に適しています。ファイルはブロックに分割され、独立して圧縮されます。 ただし、gzipやbzip2などの標準ユーティリティにはこの機能はありません。 幸いなことに、これを行うことができる多くのサードパーティ製品があります。 そのうちの2つだけを考えてみましょう:gzipの並列アナログ-pigzとbzip2のアナログ-pbzip2 。 これらの2つのユーティリティは、標準のUbuntuリポジトリで利用できます。
pigzを使用することは、スレッド数とブロックサイズを指定する機能を除いて、gzipを使用することとまったく違いはありません。 ほとんどの場合、ブロックサイズはデフォルトのままでかまいませんが、スレッドの数として、システムのプロセッサ(コア)の数に等しい(または1〜2以上)数を示すことが望ましいです。
$ pigz -c -p5 backup.tar > pigz-backup.tar.gz
620 MBのbackup.tarファイルでこのコマンドを実行すると12.8秒かかり、結果のファイルの重量は252.2 MBになりました。 gzipで同じファイルを処理する:
$ gzip -c backup.tar > gzip-backup.tar.gz
43秒かかりました。 同時に、結果のファイルの重量は、前のファイルの252.1 MBよりも100 KB少なくなりました。 繰り返しになりますが、ほぼ4倍の加速が得られました。これは朗報です。
Pigzは圧縮のみを並列化できますが、解凍はできません。これは、pbzip2とは言えません-両方を行うことができます。 ユーティリティの使用は、非並列バージョンに似ています。
$ pbzip2 -c -p5 backup.tar > pbzip-backup.tar.bz2
同じbackup.tarファイルを処理するのに38.8秒かかりました。結果のファイルのサイズは232.8 MBでした。 通常のbzip2を使用した圧縮には1分53秒かかり、ファイルサイズは232.7 MBでした。
すでに述べたように、pbzip2を使用すると、展開も高速化できます。 ただし、ここでは1つのニュアンスを考慮する必要があります-並行して解凍できるのは、以前に並行してパックされたもの、つまりpbzip2を使用して作成されたアーカイブのみです。 通常のbzip2アーカイブのいくつかのストリームへの展開は、1つのストリームで実行されます。 さて、さらにいくつかの数字:
- 通常の開梱-40.1秒;
- 5つのストリームでのアンパック-16.3秒。
pigzとpbzip2を使用して作成されたアーカイブは、対応する非パラレルを使用して作成されたアーカイブと完全に互換性があることを追加するだけです。
暗号化
デフォルトでは、eCryptfsはUbuntuおよびすべての派生ディストリビューションのホームディレクトリの暗号化に使用されます。 執筆時点では、eCryptfsはマルチスレッドをサポートしていませんでした。 これは、多数の小さなファイルがあるフォルダーで特に顕著です。 したがって、マルチコアを使用している場合、eCryptfsは実用的ではありません。 より良い代替手段は、dm-cryptまたはTruecryptシステムを使用することです。 確かに、パーティションまたはコンテナ全体のみを暗号化できますが、マルチスレッドをサポートしています。
情報
NetBSD 6.0 NPFパケットフィルターを使用すると、最小数のロックで並列マルチスレッドパケット処理を行うため、マルチコアシステムで最大のパフォーマンスを実現できます。
ディスク全体ではなく特定のディレクトリのみを暗号化する場合は、 EncFSを試すことができます。 これはeCryptfsと非常によく似ていますが、後者とは異なり、カーネルモードではなく、FUSEを使用して動作し、eCryptfsよりも潜在的に遅くなります。 ただし、マルチスレッドをサポートしているため、マルチコアシステムでは速度が向上します。 さらに、インストール(ほとんどの標準リポジトリで利用可能)は非常に簡単です。 あなたがする必要があるのは
$ encfs ~/.crypt-raw ~/crypt
パスフレーズを入力するだけです。.crypt-rawでは暗号化されたファイルが存在し、cryptでは暗号化されていないバージョンが存在します。 EncFSをアンマウントするには、次の手順を実行します。
$ fusermount -u ~/name
もちろん、これはすべて自動化できます。 ここでこれを行う方法について読むことができます 。
カーネルが耕す様子を見るのが好きです
プロセッサを完全にロードしますが、その動作を監視する必要がある場合があります。 原則として、ほとんどすべてのディストリビューションには、個々のコアまたはプロセッサに関する情報など、プロセッサの使用状況を監視するための優れたスナップインがあります。 たとえば、Kubuntuでは、KSysGuardは現在のカーネル負荷を非常にうまく表示します(画面「クアッドコアシステム上のKSysGuard」を参照)。
クワッドシステム上のKSysGuard
しかし、プロセッサを熟考できる他の興味深いユーティリティがあります。 コンソールソリューションのファンは、よりカラフルでインタラクティブなtopの類似物であるhtopを好むでしょう。 また、強力で簡単にカスタマイズできるシステムモニターであるConkyに注意することをお勧めします。 各コアとプロセッサ全体の負荷を監視するように設定するのは非常に簡単です。 コアごとに、個別のグラフを表示できます。 スクリーンショットでは、ユーティリティ設定オプションを確認できます。

それがコンキーのようです
動作中のHtop
ここに投稿した対応する構成ファイルの内容。 ちなみに、ネットワークには、基礎として使用して自分でリメイクできる興味深い構成がたくさんあります。
ただし、これらのユーティリティは、ワークロードに関する情報のみを提供しますが、多くの場合、十分ではありません。 sysstatコレクションのMpstatは、各コアのアイドル時間、I / Oの待機に費やされた時間、割り込みの処理に費やされた時間など、より興味深い情報を提供します。

Mpstatユーティリティの出力
ゲームだけでなくGPU
最新のGPUの計算能力が非常に大きいことは周知の事実です。 しかし、GPUコアには特別なアーキテクチャと使用可能なコマンドの限られたセットがあるという事実のため、GPUは狭い範囲のタスクを解決するのにのみ適しています。 以前は、シェーダーの達人だけがGPUコンピューティングを実行できました。 現在、ビデオカードメーカーは、プロジェクトでグラフィックプロセッサのパワーを使用したい愛好家や開発者の生活を簡素化するために、可能なすべてを行っています。NVIDIAのCUDA、AMD FireStream、オープンスタンダードOpenCL 。 毎年、GPUコンピューティングはますますアクセスしやすくなっています。
ハッシュ計算
これまで、GPUで起動されたタスクのうち、ハッシュの計算がおそらく最も一般的です。 そして、これはすべて、実際にはハッシュを計算することであるビットコインマイニングによるものです。 ほとんどのビットコインマイナーはLinuxで利用できます。 Bitcoinsをマイニングしたい場合、およびGPUがOpenCLをサポートしている場合(CUDAをサポートしている場合はOpenCLも)、 bfgminerに注意することをお勧めします :セットアップはそれほど簡単ではありませんが、高速で便利で機能的です。
GPU Snortアクセラレーション
Gnortと呼ばれる非常に興味深い概念は、ギリシャの研究所FORTH(研究技術財団-Hellas)の研究者によって開発されました。 彼らは、正規表現をチェックするコードをGPUに転送することで、Snort攻撃の検出効率を高めることを提案しています。 公式の研究PDFに記載されているグラフによると、Snortのスループットはほぼ2倍に増加しました。
しかし、私たちは単一のビットコインとして生きているわけではありません。 ブルートフォースハッシュにGPUのパワーを使用することを妨げるものは何もありません(パスワードを忘れた場合、もちろんそれ以上のことはありません)。 この問題を解決するために、 oclHashcat-plusユーティリティはそれ自体が実証済みです-本物のハッシュハーベスタです。 salt、SHA-1、NTLM、キャッシュされたドメインパスワード、MySQLデータベースパスワード、GRUBパスワードの有無にかかわらずMD5ハッシュを取得できます。これはリストの半分でもありません。
GPU暗号化
KGPUプロジェクトの一環として、ユタ大学のWeibin SunとXing Linの学生は、GPU容量の非常に興味深いアプリケーションを発表しました 。 プロジェクトの本質は、Linuxカーネルコードの一部の実行をCUDA互換GPUに転送することです。 最初の開発者は、GPUにAESアルゴリズムを導入することにしました。 残念ながら、プロジェクトの開発はそこで停止しましたが、開発者は作業を継続すると約束しました。 ただし、これに加えて、既存のエクスペリエンスを使用してeCryptfsおよびdm-cryptのAES暗号化を高速化できます。カーネルバージョン3.0以降がサポートされていないのは残念です。
GPUパフォーマンスモニタリング
どうして?もちろん、各コアGPUの負荷を調べることはできませんが、GPUで何が起こっているかについて少なくともいくつかの情報を取得できます。CUDA-Zプログラム(ほぼWindows GPU-Zプログラムの類似物)は、GPUに関するさまざまな静的情報に加えて、動的情報(GPUとマシン間のデータ交換の現在の速度、およびフロップ内のすべてのGPUコアの全体的なパフォーマンス)も受信できます。
GPUパフォーマンス情報を含むCUDA-Zタブ
結論
マルチコアまたはマルチプロセッサのワークステーションは、私たちの日常生活に長い間含まれてきました。それらを操作するとき、私たちのシングルスレッドのアプローチを変える時が来ました。実際、このようなシステムでのタスクの並列化は、これまで見てきたように、時間の大幅な増加をもたらします。
便利なリンク
- JVM Java EE :
bit.ly/JavaTuning- CPU MPI-: bit.ly/MPIbenchmark
- , , : https://boinc.berkeley.edu

2013年10月付けのHacker誌に最初に掲載されました。
Issuu.comに公開する
ハッカーを購読する

