すべての動物は平等ですが、一部の動物は他の動物よりも平等です。 アニマルファーム、ジョージオーウェル( オリジナル )。
Habréについてのかなり多くの記事が多くのコメントを集めています。たとえば、「 今月のベスト 」という記事には、通常100を超える記事があります。 Habrを読んで長年にわたって、最初のレベルのコメントの約半分のケースで、ここにそのような写真があるように見えました
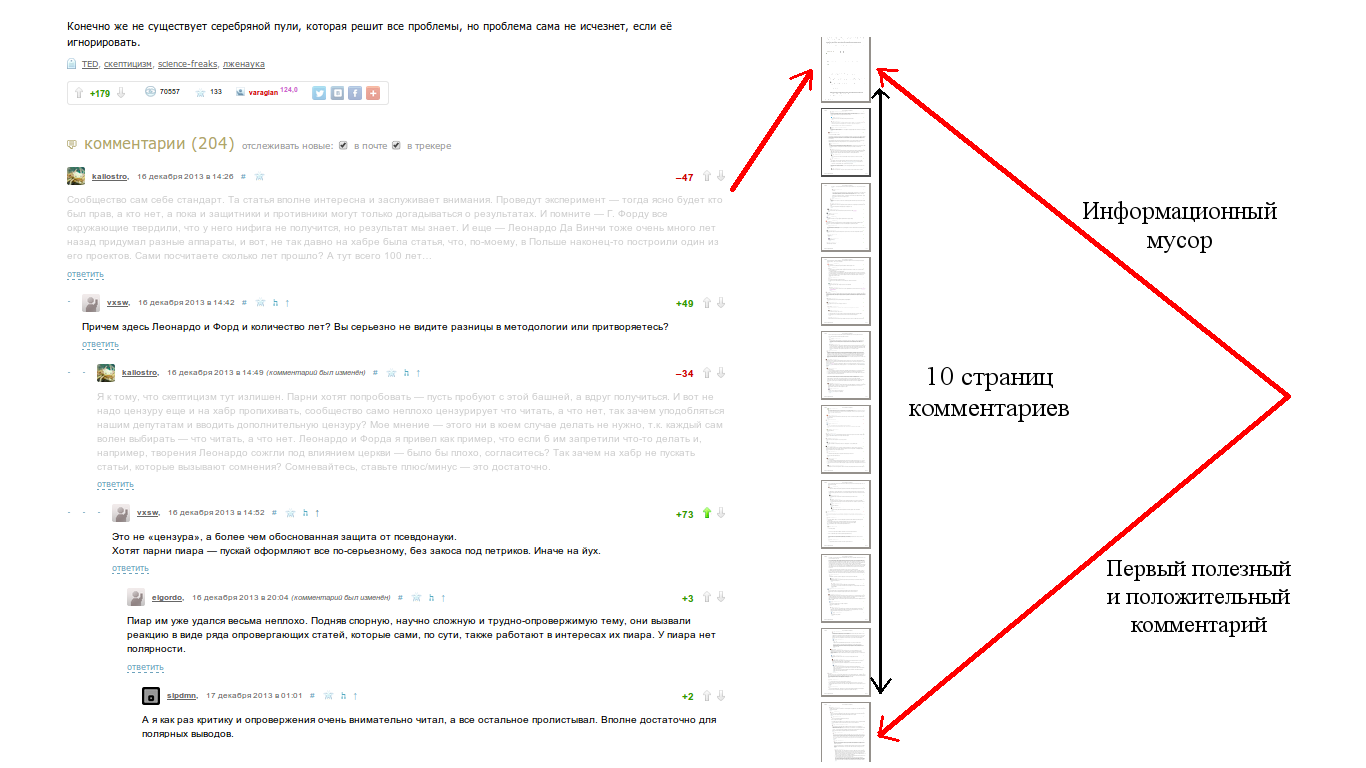
(写真はhabrの記事「懐疑論者のリスト」に基づいて作成されました)。
カットの下には、ストーリー、コメントのソートの種類、コメントの適用場所、コメントのソート方法(および理由)の簡単な説明があります。
一般的に言って、コメント、投稿、その他すべての並べ替えの問題は新しいものではありません。Facebookインフォグラフィック 、redditのコメントの並べ替え、 こことここ、 diggからのアルゴリズムパラメータの簡単な説明です 。
第1レベルのコメントをソートするための基本的な方法
単純なものから複雑なものへと進み、メソッドを簡単に説明し、特徴づけます。 最も単純で最も単純な方法から始めましょう:平均化とそのバリエーション(詳細はここで説明します )。
以下、特に指定のない限り、コメントによって「トップレベルのコメント」を意味します。 意味はおおよそ次のとおりです。トップレベルのコメントは記事自体に宛てられ、2番目、3番目などのコメントはコメントに関する議論です。 コメントのブランチ全体を考慮する方法については、記事の最後で簡単に説明します。
タスクは、特定のスコアをコメントに割り当て(コメントの重み)、このパラメーターでリスト全体をソートします。
プラスの数からマイナスの数を引いたもの

これは都市辞書のオンライン辞書で使用されています。
この方法は最も単純ですが、ユーザーの期待と最も一致するものとはほど遠いものです。 たとえば、上の図では、肯定的な評価の72%の説明は、肯定的な評価の70%の説明よりも低くなっています。
相対的な平均評価:評価の総数に対するプラスの数
Amazonの並べ替えオプションの1つは、相対的な平均評価です。 トースターを探していて、ユーザーレビューによる並べ替えが含まれているとします。
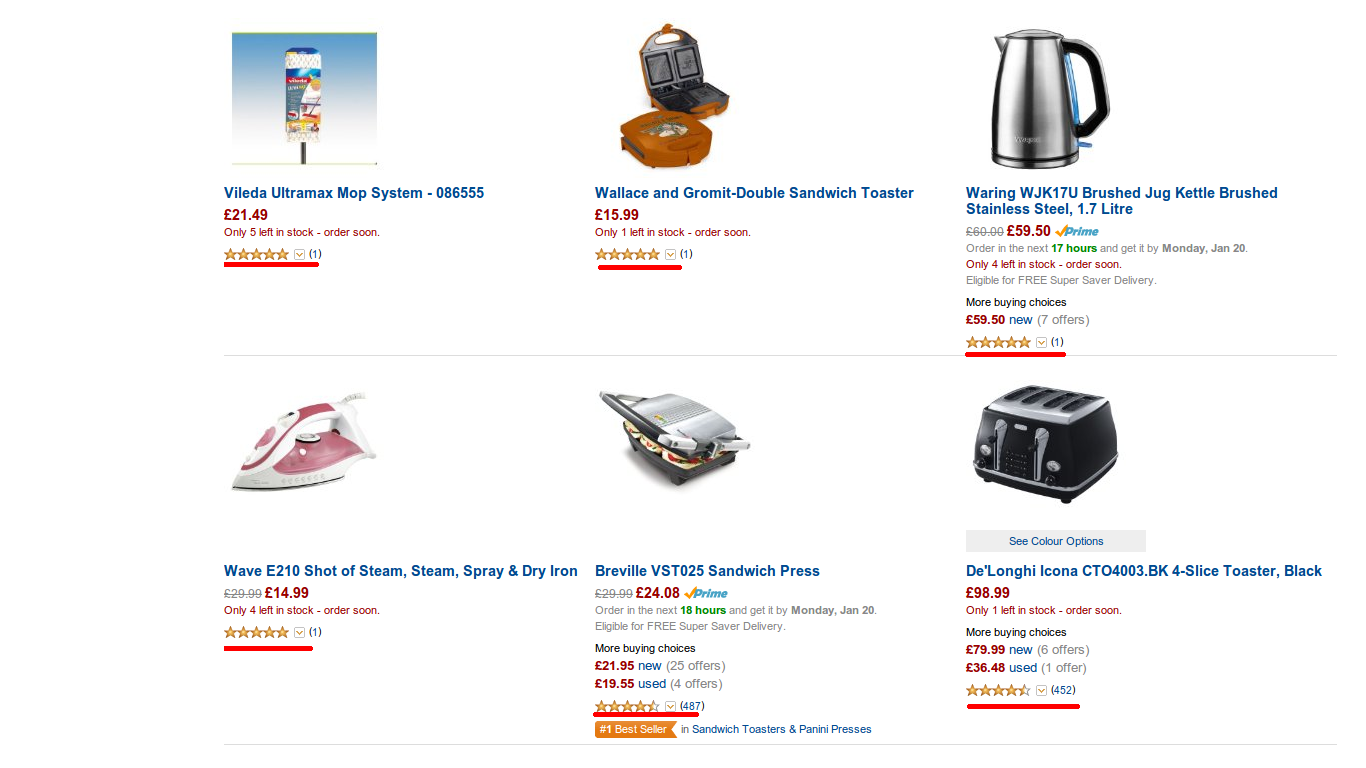
5 *の単一票を持つ要素は、これらの評価の数に関係なく、少なくとも1つの他の評価(4 *、3 *、2 *、1 *)を持つ要素よりも常に高いことがわかります。 簡単に言えば、9,999の評価が5 *と1つに4 *の製品がある場合、この製品は単一の評価が5 *の製品よりも低くなります。
肯定的な評価を待つ確率
選挙の前には、世論調査が常に行われ、少数の回答者によると、世界の全体像を取り戻そうとしています。 私たちが利用できる少数の測定値から、少なくとも0.85の確率で観測された評価数(製品に対する賛否両論)を持ち、肯定的な評価の「本当のシェア」とは何ですか?
このようなことは、本に書かれたアクセス可能な言語で通常どのように計算されるか:
ハッカーのための確率的プログラミングとベイジアン手法
簡単に言えば、このような計算には時間がかかりすぎるため、ウィルソン信頼区間の下限の式を使用します (つまり、推定値を使用する必要があります)。
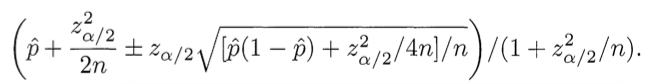
p̂は観測されたプラスの相対数、nは推定の総数、zα / 2はテーブルから取得され、これは標準正規分布の分位点(1-α/ 2)です(15%の場合z = 1-85%の信頼度、5%の場合z = 1.6-95%の信頼度)
このように何かが上に書かれているように思われる場合:

その理解できる言語と詳細はここで説明されています 。最後にここで説明されています 。 ここでは、説明した方法(および他の多くの明確な写真)の短くて理解可能な実装を見つけることができます。
さまざまなバリエーションで、このメソッドはreddit、digg、およびyelpをランキングアルゴリズムの一部として使用します。
Randal Munroeの説明と例(xkcdの作者。彼はこのアルゴリズムをredditでも紹介しました):
解説にプラスとゼロのマイナスが1つしかない場合、プラスの相対数は1.0ですが、データがほとんどないため[n-約 著者]、システムはそれをリストの最後に配置します。 そして、10のプラスと1のマイナスがある場合、システムには十分な信頼があります[ある意味で-証拠; 裏付けとなる証拠]このコメントを配置することは、40プラスと20マイナスのコメントよりも高い-コメントが40プラスを受け取るまでに、ほぼ確実に20マイナス未満になることを考慮してください。 また、システムの主な魅力は、間違っている場合(15%の場合)、より少ないデータでコメントを最上部に表示するのに十分なデータをすばやく取得できることです。
一般に、類似のベイジアン推論方法の直感は次のとおりです。たとえば、投稿に対して平均で投票する方法がいくつかあります。たとえば、0.7の確率でプラスを獲得し、0.3の確率でマイナスを獲得することができます。 特定のコインに関する新しい情報を受け取ったので、ベイズの規則に従ってその考えを修正します。
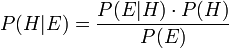
ここで、Hは仮説(仮説)、Eは観測データ(証拠)、P(E | H)=結果Eが得られる確率です。仮説Hが真の場合、観測結果Eで仮説Hの確率とは何かを言う機会が与えられます。
並べ替えの新しいオプション
上記のアルゴリズムでは、プラスとマイナスの数のみを使用します。 このパートでは、他のパラメーターがコメントのランキングに影響を与える可能性があるものを見つけます。
主な情報源は次の記事です。
Reddit、Stumbleupon、Del.icio.us、Hacker News Algorithms Exposed!
Hacker Newsランキングアルゴリズムの仕組み
Redditランキングアルゴリズムの仕組み
時間
なぜ誰かが時系列のソート以外の時間を使用する必要があるのでしょうか? 「彼らは何を議論していますか?」からのリンクを介して記事に行くと想像してください。ユーザーが議論と新鮮なコメントを期待することは非常に論理的です(もちろん、他の評価的判断と同様ですが、議論の余地があります)。
カスタムコンテンツを持つ他の大規模なサイトはどうですか? redditとハッカーのニュースを見ていきます
投稿のRedditアルゴリズム
Redditは、投稿用とコメント用の2つの異なるランキングアルゴリズムを使用します。 コメントの場合、上記のオプションはウィルソン信頼区間の下限で使用されますが、投稿の場合は時間が考慮されます。
アルゴリズムを簡単に説明する
Aが投稿が公開された秒数、Bはredditリソースの作成時間(秒)、t
t = A-B
つまり 秒単位の相対的なポストライフタイム。
x =投稿のプラスとマイナスの数の差。
z = | x | x!= 0の場合、そうでない場合はz = 1。
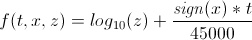
ハッカーニュースアルゴリズム
このリソースは、同じアルゴリズムを使用してコメントと投稿をソートします。
tを公開後の時間数、vを投票数、Gを定数とします(デフォルトでは1.8と言います)。
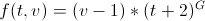
そして、なぜヤギボタンアコーディオンですか?
解説の場合、評価は十分であり、時間は重要な役割を果たすべきではないように思われます。 一方、コメントの数が増えると、多くのユーザーは最後まで到達しません(300〜400のコメントをスクロールしてみてください)。 可能な代替方法は、1つではなく、いくつかのパラメーターでソートすることです。 他の条件が等しい場合、時間を考慮してください。 たとえば、すべてのコメントに0票がある場合、古いコメントには一定のプラスを獲得する時間があったため、「新鮮なコメント」が古いコメントよりも優先されます。
または、redditの投稿やハッカーのニュースコメントなどのランキング関数で、小さな重み減衰要素として時間を使用できます。
支店全体のランキング
自然な仮定は、ブランチ内のレベル/位置に応じた重みを持つ1つのブランチのコメントを考慮することです(些細なケースでは、ブランチ全体をピアコメントのセット、つまり同じ重みで考えることができます)。 v i +がコメントiのプラスの数(マイナスと同じ表記)であり、l iがコメントiのネストレベルであり、Iがブランチ内のすべてのコメントインデックスのセットであると仮定すると、最初の方法の簡単な一般化を提供できますブランチ全体を考慮に入れて:

(ここで、v i + 、l iは実際にはコメントインデックスによってスカラーを返す関数であるため、入力には含まれません)。
同様の(単純な)方法で、コメントをランク付けする他の方法を一般化できます。 なぜこれが必要なのですか? ランキングで第一レベルの解説が重要であるだけでなく、たとえばディスカッション全体が重要であると考える場合、ブランチ全体をランク付けすることが本当に重要です。 記事の冒頭の写真に注目すると、最初のコメントが「大きく不揃い」であるにも関わらず(そして、私が思うに)、最初のスレッドでかなり興味深い議論が展開されています。
体重とユーザープロファイル
正確なdiggアルゴリズムは一般には知られていませんが、少なくともおおよそどのパラメーターがそこに含まれているかはわかっています(アルゴリズムのソース ):
- 時間枠に与えられた投票数:短期間の多数票、長期の多数票よりも良い
- リンクソース(これはdiggに固有であり、ニュースポイントはソースを持つ特定のサイトを指します):このソースからの記事はどれくらいの頻度でトップに到達しますか? (プロを取得)
- 著者プロフィール
- 出発時間:午前3時に多数の人々が同時に記事を追加する場合、ここで何かが間違っている可能性があります[論争の的になるパラメーターですね。 -約 著者]
- digg自体に同様のリンクが存在する(重複)
- 有権者のプロフィール
- コメント数
- ビューの数
- ....
一般的に、彼らは複雑なアルゴリズムを持っています。 しかし、原則としてそれから何を学ぶことができますか? さまざまな方法でさまざまなパラメータに応じて投稿のコメントと投票の重みを考慮することができ、これらのパラメータの十分な数は他のリソースのアルゴリズムからすでにわかっています。
多くの点で、アイデアは時間に似ています。追加パラメータ:ceteris paribus、コメントをランク付けするときに、ユーザーの体重(または特定のハブへの貢献も)を考慮することができるため、記事に多くのコメントがある場合、「信頼できる意見」が上に上がります残りは読み取り可能になります。
おわりに
コメントのランキングは、多くのリソースで人気があり、しばしば有用な要素です。 これがハブで必要な質問かどうか 特定の記事に関するコメントが豊富にあることで本当に問題がありますか? そうでない場合、今後表示されますか? 他の並べ替えツールは必要ですか?
ただし、リソースの主なものはコメントの並べ替えではなく、コンテンツの品質であることを常に覚えておく必要があります。