
専用サーバーのリソースのスケーリングの問題には多くの困難が伴います。メモリやディスクを追加することはダウンタイムなしでは不可能であり、ディスクサブシステムのアップグレードには、多くの場合、古いサーバーから新しいサーバーへのすべてのデータ(非常に大量になる可能性がある)の完全な転送が含まれます。 あるサーバーから別のサーバーにディスクを単純に移動することも非常に頻繁に不可能になります。その理由は、インターフェースの非互換性、異なるRAIDコントローラーの使用、サーバー間の地理的距離などです。 ネットワークを介したデータのコピーには非常に長い時間がかかり、その間サービスはアイドル状態になります。 サービスのダウンタイムを最小限に抑えて、新しいサーバーにデータを転送するにはどうすればよいですか?
私たちはこの問題について長い間考えていましたが、今日、私たちにとって最も成功していると思われる解決策を幅広い聴衆の注目を集めています。
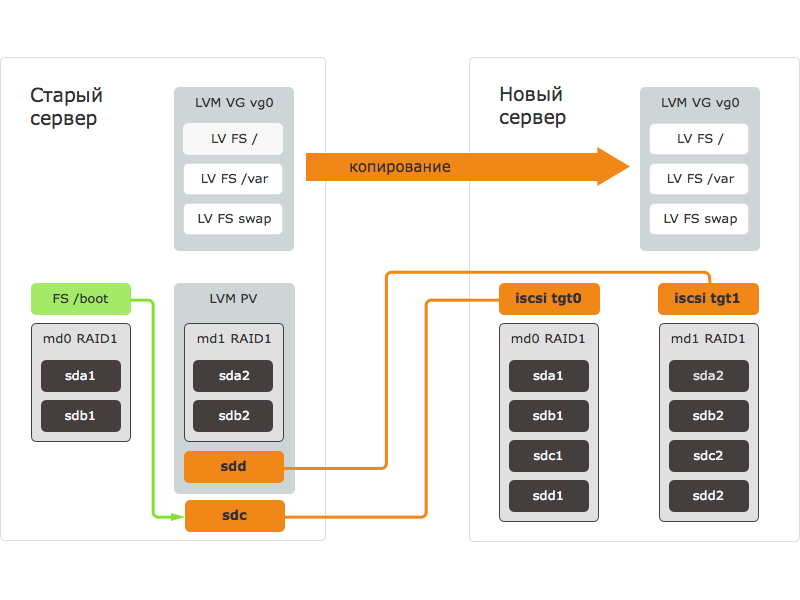
この記事で説明した方法を使用したデータ転送手順は、次の手順で構成されています。
- 新しいサーバーは外部メディアからロードされ、ブロックデバイスが準備されます。ディスクはマークアップされ、RAIDアレイが作成されます。
- 新しいサーバーのブロックデバイスは、iSCSI経由でエクスポートされます-iSCSIターゲットが作成されます。
- 古いサーバーで、iSCSIイニシエーターが起動し、新しいサーバーのターゲットに接続します。 古いサーバーでは、新しいサーバーのブロックデバイスが表示され、使用可能になります。
- 古いサーバーでは、新しいサーバーのブロックデバイスがLVMグループに追加されます。
- データは、LVMのデータミラーリングを使用して、新しいサーバーのブロックデバイスにコピーされます。
- 古いサーバーはシャットダウンします。
- 外部メディアからロードされたままの新しいサーバーに、転送されたFSがマウントされ、設定に必要な変更が加えられます。
- 新しいサーバーがディスクから再起動し、その後すべてのサービスが開始されます。
新しいサーバーで問題が検出された場合、サーバーはシャットダウンします。 古いサーバーがオンになり、すべてのサービスが古いサーバーで引き続き機能します。
提案する手法は、論理パーティションにLVMを使用し、iSCSIターゲットとイニシエーターを設定できるすべてのオペレーティングシステムに適しています。 Debian Wheezyは、提案された方法をテストしたサーバーにインストールされました。 他のオペレーティングシステムでは、他のプログラムとコマンドを使用できますが、手順は似ています。
すべての操作は、OSの自動インストール中のサーバーの標準であるディスクレイアウトのサーバーで実行されました。 サーバーが異なるディスクレイアウトを使用している場合、一部のコマンドのパラメーターを変更する必要があります。
当社のデータ転送方法は、LVM、mdraid、iSCSIが何であるかをよく知っている経験豊富なユーザー向けに設計されています。 コマンドのエラーにより、データが完全または部分的に失われる可能性があることを警告します。 データ転送を進める前に、重要な情報を外部ストレージまたはストレージにバックアップする必要があります。
新しいサーバーの準備
異なるハードウェア構成のサーバーにデータを転送する場合(ディスクコントローラーに特に注意する必要があります)、古いサーバーと同じOSディストリビューションと、作業に必要なドライバーをインストールします。 すべてのデバイスが検出され、動作していることを確認します。 必要なアクションを保存/書き留めます。将来、新しいサーバーが転送後に起動できるように、転送されたシステムで実行する必要があります。
次に、外部メディアから新しいサーバーを起動します。 サーバーの起動制御メニューを使用して、Selectel Rescueを起動することをお勧めします。
ダウンロードが完了したら、SSHを介して新しいサーバーに接続します。 新しいサーバーを将来のホスト名に設定します。 これは、新しいサーバーでmdraidを使用する場合に必要です。RAIDアレイを作成するとき、ホスト名は含まれるすべてのディスク上のRAIDアレイのメタデータに保存されます。
#ホスト名cs940
次に、ディスクにマークを付けます。 この場合、各ディスクに2つのメインパーティションが各サーバーに作成されます。 最初のセクションは/ boot用のRAID1を構築するために使用され、2番目のセクションはメインデータが配置されるLVM物理ボリューム用のRAID10を構築するために使用されます。
#fdisk / dev / sda コマンド(ヘルプはm):p ... デバイスブートスタートエンドブロックIDシステム / dev / sda1 * 2048 2099199 1048576 fd Linux raid autodetect / dev / sda2 2099200 1953525167 975712984 fd Linux raid autodetect コマンド(ヘルプはm):w
すべてをシンプルかつ高速にするために、最初のディスクのみをパーティション分割し、残りのパーティションをコピーできます。 次に、mdadmユーティリティを使用してRAIDアレイを作成します。
#sfdisk -d / dev / sda | sfdisk / dev / sdb -f #mdadm --create / dev / md0 --level = 1 --raid-devices = 4 / dev / sda1 / dev / sdb1 / dev / sdc1 / dev / sdd1 #mdadm --create / dev / md1 --level = 10 --raid-devices = 4 / dev / sda2 / dev / sdb2 / dev / sdc2 / dev / sdd2 #mdadm --examine --scan ARRAY / dev / md / 0メタデータ= 1.2 UUID = e9b2b8e0:205c12f0:2124cd91:35a3b4c8 name = cs940:0 ARRAY / dev / md / 1メタデータ= 1.2 UUID = 4be6fb41:ab4ce516:0ba4ca4d:e30ad60b name = cs940:1
次に、iSCSIターゲットを設定および構成して、ネットワーク経由でRAIDアレイをコピーします。 tgtを使用しました。
#aptitude update #aptitude install tgt
tgtを実行するときに、不足しているカーネルモジュールの読み込みエラーが発生した場合、心配しないでください:必要ありません。
#tgtd librdmacm:ABIバージョンを読み取れませんでした。 librdmacm:想定:4 CMA:RDMAデバイスリストを取得できません (null):iser_ib_init(3263)RDMAの初期化に失敗しました。 カーネルモジュールをロードしますか? (null):fcoe_init(214)(null) (null):fcoe_create_interface(171)インターフェイスが指定されていません。
次のステップは、LUNを構成することです。 LUNを作成するとき、ターゲットへの接続を許可する古いサーバーのIPを指定する必要があります。
#tgt-setup-lun -n tgt0 -d / dev / md0 10.0.0.1 #tgt-setup-lun -n tgt1 -d / dev / md1 10.0.0.1 #tgt-admin -s
新しいサーバーの準備ができました。古いサーバーの準備に移りましょう。
古いサーバーの準備とデータのコピー
次に、SSHを介して古いサーバーに接続します。 iSCSIイニシエーターをインストールして構成し、新しいサーバーからエクスポートされたブロックデバイスをそれに接続します。
#apt-get install open-iscsi
許可データを構成ファイルに追加します。これらがないと、イニシエーターは機能しません。
#nano /etc/iscsi/iscsid.conf node.startup =自動 node.session.auth.username = MY-ISCSI-USER node.session.auth.password = MY-ISCSI-PASSWORD discovery.sendtargets.auth.username = MY-ISCSI-USER discovery.sendtargets.auth.password = MY-ISCSI-PASSWORD
それ以降の操作にはかなり時間がかかります。 SSHが閉じられたときに中断された場合の不快な結果を避けるために、画面ユーティリティを使用します。 その助けを借りて、実行中のコマンドを完了せずにSSH経由で接続および切断できる仮想端末を作成します。
#apt-getインストール画面 #画面
次に、ポータルに接続し、使用可能なターゲットのリストを取得します。 新しいサーバーの現在のIPアドレスを示します。
#iscsiadm --mode discovery --type sendtargets --portal 10.0.0.2 10.0.0.2:3260,1 iqn.2001-04.com.cs940-tgt0 10.0.0.2:3260,1 iqn.2001-04.com.cs940-tgt1
次に、使用可能なすべてのターゲットとLUNを接続します。 このコマンドの結果として、新しいブロックデバイスのリストが表示されます。
#iscsiadm --mode node --login [iface:default、target:iqn.2001-04.com.cs940-tgt0、portal:10.0.0.2,3260](複数)へのログイン [iface:default、target:iqn.2001-04.com.cs940-tgt1、portal:10.0.0.2,3260](複数)へのログイン [iface:default、target:iqn.2001-04.com.cs940-tgt0、portal:10.0.0.2,3260]へのログインに成功しました。 [iface:default、target:iqn.2001-04.com.cs940-tgt1、portal:10.0.0.2,3260]へのログインに成功しました。
システム上のiSCSIデバイスの名前は、通常のSATA / SASと同じです。 しかし、同時に、メーカーの名前は2種類のデバイスで異なります。iSCSIデバイスの場合、IETとして示されます。
#cat / sys / block / sdc / device / vendor IET
これで、データを転送する準備ができました。 まず、ブートをアンマウントして、新しいサーバーにコピーします。
#umount / boot #cat / sys / block / sdc /サイズ 1999744 #cat / sys / block / md0 /サイズ 1999744 #dd if = / dev / md0 of = / dev / sdc bs = 1M 976 + 1レコード 976 + 1レコード 1023868928バイト(1.0 GB)コピー、19.6404秒、52.1 MB /秒
注意! 今後、VGをアクティブにせず、新しいサーバーでLVMユーティリティを実行しないでください。 同じブロックデバイスで2つのLVMを同時に操作すると、データが破損または損失する可能性があります。
次に、データの転送を開始します。 新しいサーバーからエクスポートされたRAID10アレイをVGに追加します。
#vgextend vg0 / dev / sdd #pvs PV VG Fmt Attr PSize PFree / dev / md1 vg0 lvm2 a-- 464.68g 0 / dev / sdd vg0 lvm2 a-- 1.82t 1.82t
/ dev / sddはRescueにロードされた新しいサーバーからエクスポートされた/ dev / md1であることを忘れないでください:
#lvs LV VG Attr LSize Pool Origin Data%Move Log Copy%Convert ルートvg0 -wi-ao-- 47.68g swap_1 vg0 -wi-ao-- 11.44g var vg0 -wi-ao-- 405.55g
ここで、lnconvertコマンドを使用して、新しいサーバー上の各論理ボリュームのコピーを作成します。 --corelogオプションを使用すると、ミラーログの下に別のブロックデバイスなしで実行できます。
#lvconvert -m1 vg0 / root --corelog / dev / sdd vg0 /ルート:変換済み:0.0% vg0 /ルート:変換済み:1.4% ... vg0 /ルート:変換済み:100.0%
LVMのミラー化されたコピーを作成するとき、すべての書き込み操作は同期的に実行されるため、サーバー間のチャネルの速度、オープンiSCSIパフォーマンス(500 mb / s)、およびネットワーク遅延が記録速度に影響します。 すべての論理ボリュームのコピーを作成したら、それらがすべて同期されていることを確認します。
#lvs LV VG Attr LSize Pool Origin Data%Move Log Copy%Convert ルートvg0 mwi-aom- 47.68g 100.00 swap_1 vg0 mwi-aom- 11.44g 100.00 var vg0 mwi-aom- 405.55g 100.00
この段階で、すべてのデータがコピーされ、古いサーバーのデータが新しいリモートサーバーと同期されます。 ファイルシステムの変更を最小限に抑えるには、すべてのアプリケーションサービス(データベースサービス、Webサーバーなど)を停止する必要があります。
すべての重要なサービスを停止した後、iSCSIデバイスを切断し、アクセスできなくなったLVMのコピーを除外します。 古いサーバーのiSCSIデバイスを切断すると、多数のI / Oエラーメッセージが表示されますが、これは心配する必要はありません。すべてのデータはブロックデバイスの上にあるLVMに保存されます。
#iscsiadm --mode session -u #vgreduce vg0 --removemissing --force #lvs LV VG Attr LSize Pool Origin Data%Move Log Copy%Convert ルートvg0 -wi-ao-- 47.68g swap_1 vg0 -wi-ao-- 11.44g var vg0 -wi-ao-- 405.55g
これで、古いサーバーをオフにできます。 すべてのデータがそこに残り、新しいサーバーで問題が発生した場合は、いつでも使用できます。
#パワーオフ
新しいサーバーを起動する
データ転送後、新しいサーバーはセルフロードの準備と起動が必要です。
sshを介して接続し、iSCSIターゲットを停止し、LVMコピーをアクティブ化します。
#tgtadm --lld iscsi --mode target --op delete --tid 1 #tgtadm --lld iscsi --mode target --op delete --tid 2 #pvscan
次に、LVMから古いサーバーのコピーを除外します。 後半の不在の報告には注意を払いません。
#vgreduce vg0 --removemissing --force uuid 1nLg01-fAuF-VW6B-xSKu-Crn3-RDJ6-cJgIaxのデバイスが見つかりませんでした。 vg0 / swap_1のミラー同期ステータスを判別できません。 vg0 / rootのミラー同期ステータスを判別できません。 vg0 / varのミラー同期ステータスを判別できません。 一貫性のあるボリュームグループvg0を作成しました
すべての論理ボリュームが適切に配置されていることを確認した後、それらをアクティブにします。
#lvs LV VG Attr LSize Pool Origin Data%Move Log Copy%Convert ルートvg0 -wi ----- 47.68g swap_1 vg0 -wi ----- 11.44g var vg0 -wi ----- 405.55g #vgchange -ay ボリュームグループ「vg0」内の3つの論理ボリュームがアクティブになりました
また、すべての論理ボリューム上のファイルシステムをチェックすることをお勧めします。
#fsck / dev / mapper / vg0-root
次に、コピーしたシステムをchrootし、最終的な変更を行います。 これは、Selectel Rescueで利用可能なinfiltrate-rootスクリプトを使用して実行できます。
#infiltrate-root / dev / mapper / vg0-root
次に、chrootからサーバー上のすべてのアクションを実行します。 すべてのファイルシステムをfstabからマウントします(デフォルトでは、chrootはルートファイルシステムのみをマウントします)。
Chroot:/#mount -a
次に、mdadm構成ファイルで新しいサーバーのRAIDアレイに関する情報を更新します。 古いRAIDアレイ(「ARRAY」で始まる行)に関するすべてのデータを削除し、新しいアレイを追加します。
Chroot:/#nano /etc/mdadm/mdadm.conf Chroot:/#mdadm --examine --scan >> /etc/mdadm/mdadm.conf
有効なmdadm.confの例:
Chroot:/#cat /etc/mdadm/mdadm.conf デバイスパーティション #Debian標準権限でデバイスを自動作成 CREATEオーナー=ルートグループ=ディスクモード= 0660自動=はい #新しいアレイをローカルシステムに属するものとして自動的にタグ付けする ホームホスト #監視デーモンにメール警告の送信先を指示します MAILADDRルート #既存のMDアレイの定義 ARRAY / dev / md / 0メタデータ= 1.2 UUID = 2521ca82:2a52a408:565fab6c:43ba944e name = cs940:0 ARRAY / dev / md / 1メタデータ= 1.2 UUID = 6240c2db:b4854bd7:4c4e1510:d37e5010 name = cs940:1
その後、initramfsを更新して、新しいRAIDアレイを見つけて起動できるようにする必要があります。 また、ディスクにGRUBブートローダーをインストールし、構成を更新します。
Chroot:/#update-initramfs -u Chroot:/#grub-install / dev / sda --recheck インストールが完了しました。 エラーは報告されていません。 Chroot:/#grub-install / dev / sdb --recheck インストールが完了しました。 エラーは報告されていません。 Chroot:/#update-grub grub.cfgを生成しています... Linuxイメージが見つかりました:/boot/vmlinuz-3.2.0-4-amd64 initrdイメージが見つかりました:/boot/initrd.img-3.2.0-4-amd64 やった
ネットワークインターフェースとMACアドレスの名前が一致するudevファイルを削除します(次回のブート時に再作成されます)。
Chroot:/#rm /etc/udev/rules.d/70-persistent-net.rules
これで、新しいサーバーを起動する準備ができました。
Chroot:/#umount -a Chroot:/#exit
サーバー管理メニューの最初のハードドライブから起動するように起動順序を変更し、再起動します。
#再起動
次に、サーバーが起動したことをKVMコンソールで確認し、IPアドレスでサーバーへのアクセスを確認します。 新しいサーバーに問題がある場合は、古いサーバーに戻ることができます。
稼働中のOSに古いサーバーと新しいサーバーを同時にロードしないでください。同じIPでロードされるため、アクセスが失われるなどの問題が発生する可能性があります。
移行後のファイルシステムの適応
すべてのデータが転送され、すべてのサービスが機能しており、さらにアクションをゆっくり実行できます。 検討中の例では、データは大量のディスク容量を持つサーバーに移行されました。 このすべてのディスク領域を使用する必要があります。 これを行うには、まず物理パーティションを展開し、次に論理パーティションを展開し、最後にファイルシステム全体を展開します。
#pvresize / dev / md1#pvs PV VG Fmt Attr PSize PFree / dev / md1 vg0 lvm2 a-- 1.82t 1.36t#vgs VG #PV #LV #SN Attr VSize VFree vg0 1 3 0 wz-n- 1.82t 1.36t#lvextend / dev / vg0 / var / dev / md1論理ボリュームvarを1.76 TiBに拡張します論理ボリュームvarが正常にサイズ変更されましたg swap_1 vg0 -wi-ao-- 11.44g var vg0 -wi-ao-- 1.76t#xfs_growfs / var meta-data = / dev / mapper / vg0-var isize = 256 agcount = 4、agsize = 26578176 blks = sectsz = 512 attr = 2 data = bsize = 4096ブロック= 106312704、imaxpct = 25 = sunit = 0 swidth = 0 blks命名=バージョン2 bsize = 4096 ascii-ci = 0 log =内部bsize = 4096ブロック= 51910、バージョン= 2 = sectsz = 512 sunit = 0 blks、lazy-count = 1 realtime = none extsz = 4096ブロック= 0、rtextents = 0データブロックが106312704から472291328に変更されました2%/ udev 10M 0 10M 0%/ dev tmpfs 1.6G 280K 1.6G 1%/ run / dev / mapper / vg0-root 47G 660M 44G 2%/ tmpfs 5.0M 0 5.0M 0% /実行/ロックtmpfs 3.2G 0 3.2G 0%/実行/ shm / dev / md0 962M 36M 877M 4%/ boot / dev / mapper / vg0-var 1.8T 199M 1.8T 1%/ var
おわりに
その複雑さにもかかわらず、私たちが説明したアプローチにはいくつかの利点があります。 まず、サーバーの長時間のダウンタイムを回避できます。データのコピー中もすべてのサービスが引き続き機能します。 第二に、新しいサーバーに問題が発生した場合、クイックスタートの準備が整った古いサーバーは予備のままです。 第三に、これは普遍的であり、サーバーで実行されているサービスに依存しません。
同様に、他のオペレーティングシステム(CentOS、OpenSUSEなど)で移行できます。当然、この場合、いくつかの微妙な違いがあります(新しいサーバーで起動するOSの準備、ブートローダー、initrdなどの設定)。
私たちが提案している手法は理想的とは考えられないことをよく知っています。 その改善のためのコメントや提案に感謝します。 読者のいずれかが、サーバーを停止せずにデータを転送するという問題に対する独自のバージョンのソリューションを提供できる場合、私たちはそれに慣れて喜んでいるでしょう。
Habréの投稿にコメントできない読者は、私たちのブログを歓迎します。