はじめに
アルゴリズム取引では、メカニカルトレーディングシステム(MTS)を作成する際、取引アルゴリズムの有効期間の問題が非常に重要です。 はい、そして原則としてそれらを見つけることは非常に困難です。 刻々と変化する市場では、遅かれ早かれ、最も先進的で収益性の高いアルゴリズムでさえ損失をもたらし始めます。 そして、彼らが言うように、現在の市場条件下でそれを「ねじる」か最適化することが必要です。 最も一般的なものの1つは、テクニカル分析用のさまざまな指標を備えたローソク足チャートで動作する取引システム(TS)です。
指標に基づいて戦略を構築するために、時間枠、期間、パラメーターの重みなど、さまざまなパラメーターが使用されます。 また、複数の異なる指標が一度に取引戦略で使用される場合、同じ戦略の入力パラメーターの数は桁違いに増加し、現在の市場に最適な値を選択することは非常に困難になります。
これらの問題を解決するために、さまざまなオプティマイザーテスターがあります。
戦略最適化方法
最も明白な解決策は、考えられるすべての戦略を採用し、履歴データをソートしてテストし、最も収益性の高い戦略を選択することです。 ただし、変更可能なパラメーターの数が2、3を超え、これらのパラメーターの範囲で可能な戦略オプションの数が数千から数万になり始めると、そのようなテストの長さのために列挙方法が単に不可能になることがあります。
Wealth-Lab 、 AmiBrokerなどの他のソフトウェア製品には、既製の戦略オプティマイザーがあります。 ただし、独自のスクリプト言語を使用しており、原則として他の制限がいくつかあり、戦略を完全にテストすることはできません。 戦略をそれらに変換する方法は? このテスターで必要なものはすべて揃っていますか? テストには現実が反映されますか? そして、このトピックをより詳細に研究し始めると、他の多くの疑問が生じます。
さらに、これらは「ブラックボックス」であり、実際にどのように計算を行うかは誰にもわかりません。 そして、お金に関して言えば、事故や不確実性のための場所はないはずです。 「言葉で」私はそのようなソフトウェアの作成者を信じていません。 最も深刻な製品で、あらゆる種類の不具合やバグ、手紙、技術サポートの呼び出しに何度も遭遇しました。 同時に、私たちは完全に不必要な人々に依存するようになります。 一般的に、私はそれらに自信がありません。 これらの問題はすべて、アルゴリズムの実装を大幅に遅くするため、時間と費用がかかります。
そして、私は自分自身に尋ねました:「独自のオプティマイザーを書いてみませんか? それは本当に難しいのでしょうか?」 さらに、結果に自信があり、プログラムの設定とアップグレードと修正に自由があります。 実際にこれらの考えで私は仕事に着きました。
確率的最適化に基づいています。 確率的最適化は、最適なアルゴリズムを見つけるプロセスでランダム性を使用する最適化アルゴリズムのクラスです。 確率的最適化アルゴリズムは、目的関数が不連続、ノイズなどを含む複雑な複数極値である場合に使用されます。さらに、それらは、戦略オプションの範囲の一部のみを研究し、得られたデータに基づいて、全体としての空間のアイデアを作ります。
私は、遺伝学、モンテカルロ、粒子の群れ、それらの多様性、その他の方法-主に適用される確率的最適化方法に精通しました。 一般的に、確率論的手法には多くの種類があります。 たとえば、「粒子の群れ」メソッドや、人気のある「遺伝的アルゴリズム」 。 「シミュレーテッドアニーリング」アルゴリズムなどのエレガントなソリューションもあります(右側の美しいGIF、ご覧になることをお勧めします)。
たとえば、後者の方法では、高度な方法でグローバルな極値を見つけることができます。 この方法では、彼は定期的に経路から逸脱し、さらに周辺地域を調査します。 しかし、研究速度は最高ではありません。 メソッドの本質は同じです-ランダムな値を選択し、何らかの方法で分析します。 メソッドごとに変更されるのは、研究の速度と精度という2つのパラメーターのみです。 そして反比例。 テスト速度が速いほど、結果の品質は低下し、逆も同様です。 方法を選択するとき、誰もが彼が何を犠牲にするかを自分で決めます。
極値を検索
たとえば、「シミュレーテッドアニーリング」の方法を使用すると、グローバルな極値を見つけることができます。 ただし、考えてみると、収束しない限り、極値自体は役に立たない。 つまり、極値の周囲の近傍が条件付きで均一に減少しない場合、このグローバルな極値はランダムである可能性が高く、不適切であるため、利益を得られず、計算が台無しになります。 したがって、極値の周りのパラメーターを調べることが非常に重要です。 収束がある場合、システムがあり、この戦略をさらに研究できます。
すべての確率的最適化手法には、1つの共通の欠点があります-極値に達する可能性があり、非常に最適な値を逃す可能性があります。 これを回避するには、サンプルの面積と反復回数を最大化する必要があります。 しかし、計算の速度はこれに苦しんでいます。 したがって、常に中間点を探す必要があります。
計算は複雑で非自明であるため、「シミュレーテッドアニーリング」やその他の「パーティクルのスウォーム」の方法は取っておきます。 その結果、私の場合の最も手頃で便利な方法は、モンテカルロ法を使用した最適化であるという結論に達しました。
テスターオプティマイザー「モンテカルロ」の最初のバージョン
従来の最大検索
彼は、サンクトペテルブルク州立大学のコレクションの記事「モンテカルロ法による非線形確率的最適化」の論理を、最初のテスター最適化の基礎として採用することにしました。 この方向に興味がある人は、彼らのコレクションを読むことをお勧めします。 さまざまな分野での最適化に関する多くの興味深い多目的な記事。 これらの確率論的な方法が当てはまらない場合!
だからここに。 この方法の本質は、さまざまなパラメーターを持つさまざまな戦略で構成される多次元マトリックスを作成することです。 このマトリックスから戦略をランダムに選択してテストし、最も収益性の高い戦略を決定します。 収益性の基準については、これまでのところ期待しています。 したがって、複雑なパラメーターを作成できます。 マトリックス内のこの戦略からポイントを震源とし、震源から設定した深さまで可能な限りマトリックスのエッジをカットします。 したがって、サンプル領域を削減し、結果の削減された領域からランダム戦略を新しい方法でテストし、反復を繰り返します。 したがって、極端に収束するまで続けます。
サンプル領域の減少の大きさを判断する方法は多数あります。 目的関数の勾配の変化を調べる統計的または経験的で、反復ごとに極値自体がどれだけ速く変化するかを調べます。 そして、これらのデータに基づいて、調査をさらに続行するか反復を停止するかを決定し、特定のエラーで既に最大値が見つかったことを受け入れます。 いわゆる停止基準。
しかし、すでに前述したように、極値周辺の領域を調べることが重要であるため、最後に収束し、最後の反復ですべての隣接戦略を完全にチェックすることにしました。 勾配をうまく使用できず、収束を初期サンプルの割合として静的にしました。 つまり、各反復後に多次元行列を1%または20%カットする量は、最初に決定します。 また、すぐに、時間能力を考慮して、テストのために各反復でマトリックスからいくつの戦略を取るかを決定します。 したがって、マトリックスのサイズはまったく重要ではありません。反復の数と実行するボリュームを正確に知っています。 これが確率的手法の美しさです。
上記に基づいて、戦略の最適なパラメーターを検索するプログラムを作成しました。
最適化のための初期データ:
- テスト取引手段
- 歴史の範囲
- ローソク足の時間枠(少なくとも5秒から数時間までのすべて)、
- 考慮される戦略パラメーターの範囲、
- これらの範囲にステップインし、
- 反復後のサンプル領域の減少率、
- サンプル内の要素の数、
- テストのために送信された戦略の数。
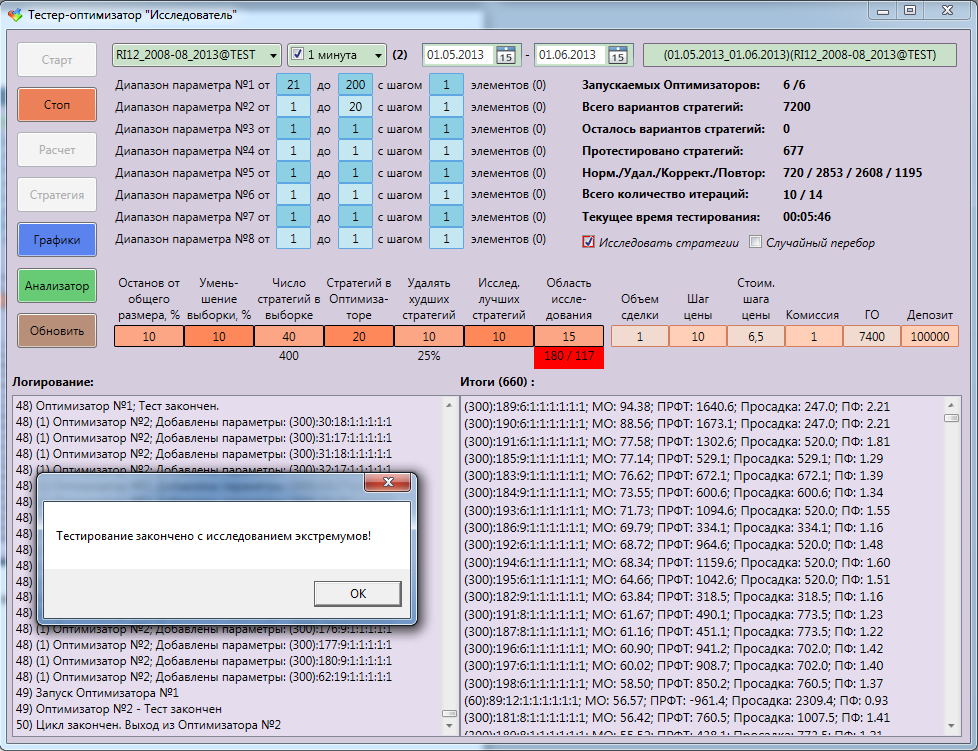
コンソールテスター(私はそれらをいくつか持っており、プロセッサを完全にロードします)は、入力として戦略のパラメーターを受け取り、テストし、最後に結果をバイナリファイルに保存します。 これは、エラーが発生した場合のテストデータの中間ストレージ、およびメモリリークやその他のグリッチに対する保護のために行われます。 そして一般的に、何かの失敗のリスクの多様化。 プログラム自体がすべてのデータを転送し、テスターがフルパワーで同時に動作するように負荷を共有し、一方が終了すると、もう一方がすぐに開始します。 私はすべてを同期する方法に長い間苦しんでいましたが、すべてが自律的に、迅速かつ便利になりました!
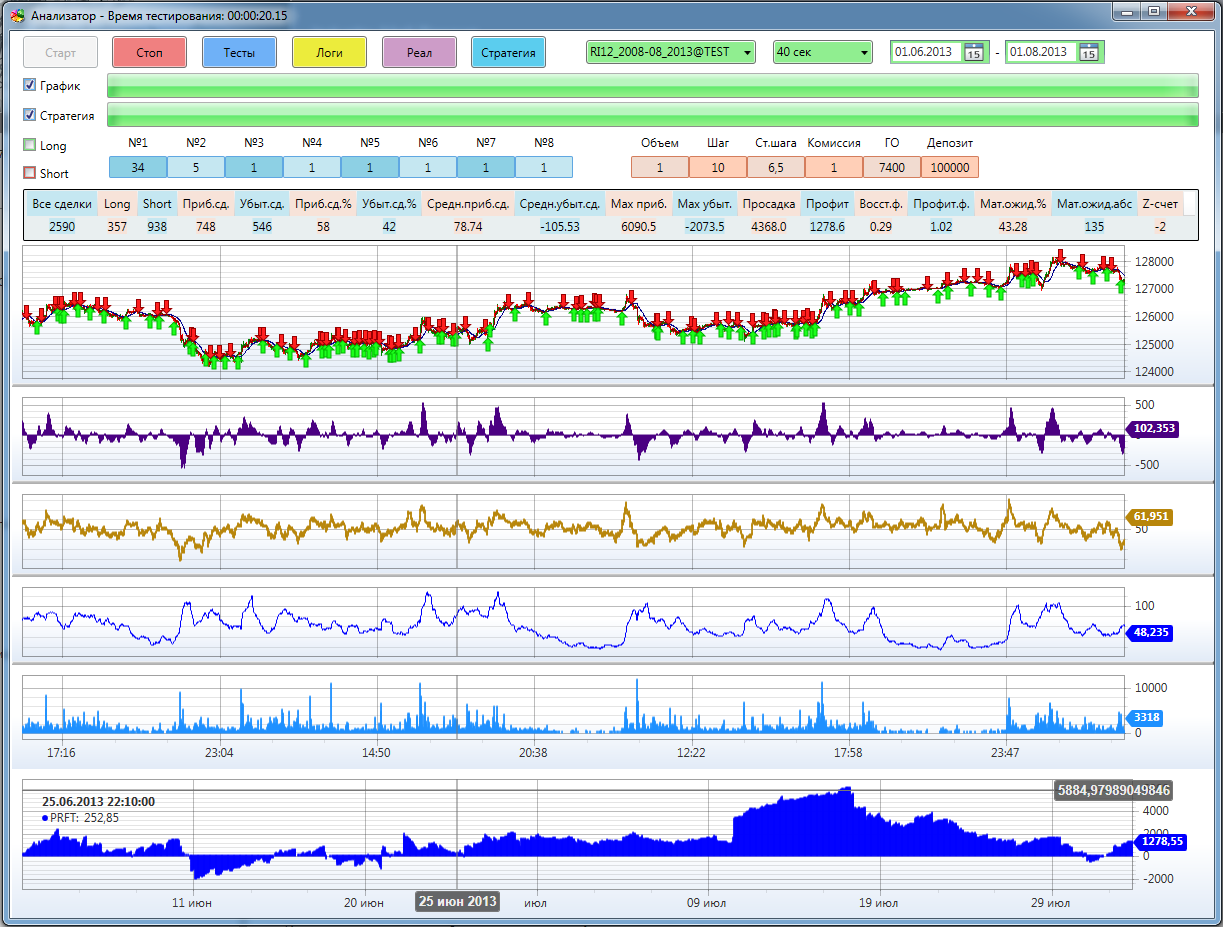
この場合、すべてのパラメーターと結果は、モンテカルロプログラムのメインウィンドウに表示されます。 したがって、そこで発生するすべてのことは目に見えて理解できます。 ロギングウィンドウとテスト結果のウィンドウがあります。 各反復の後、プログラムはシリアル化されたファイルを開き、それらの統計を計算し、並べ替えて画面に表示します。
モンテカルロオプティマイザーテスターインターフェイス:
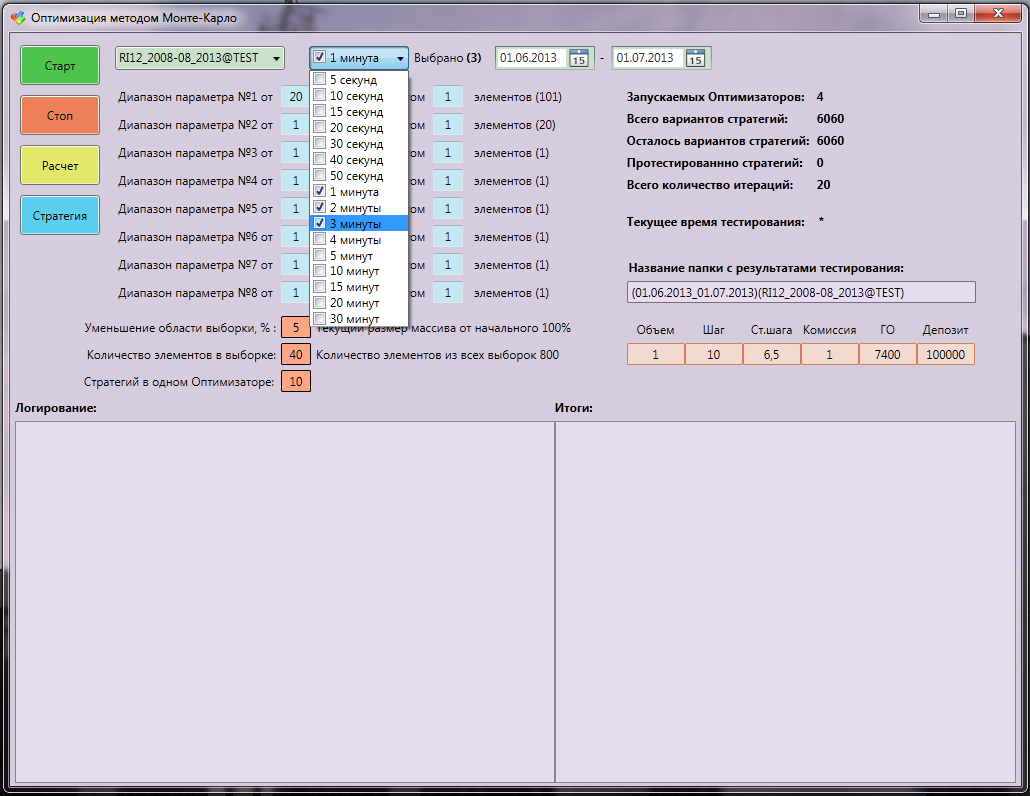
仕事中:
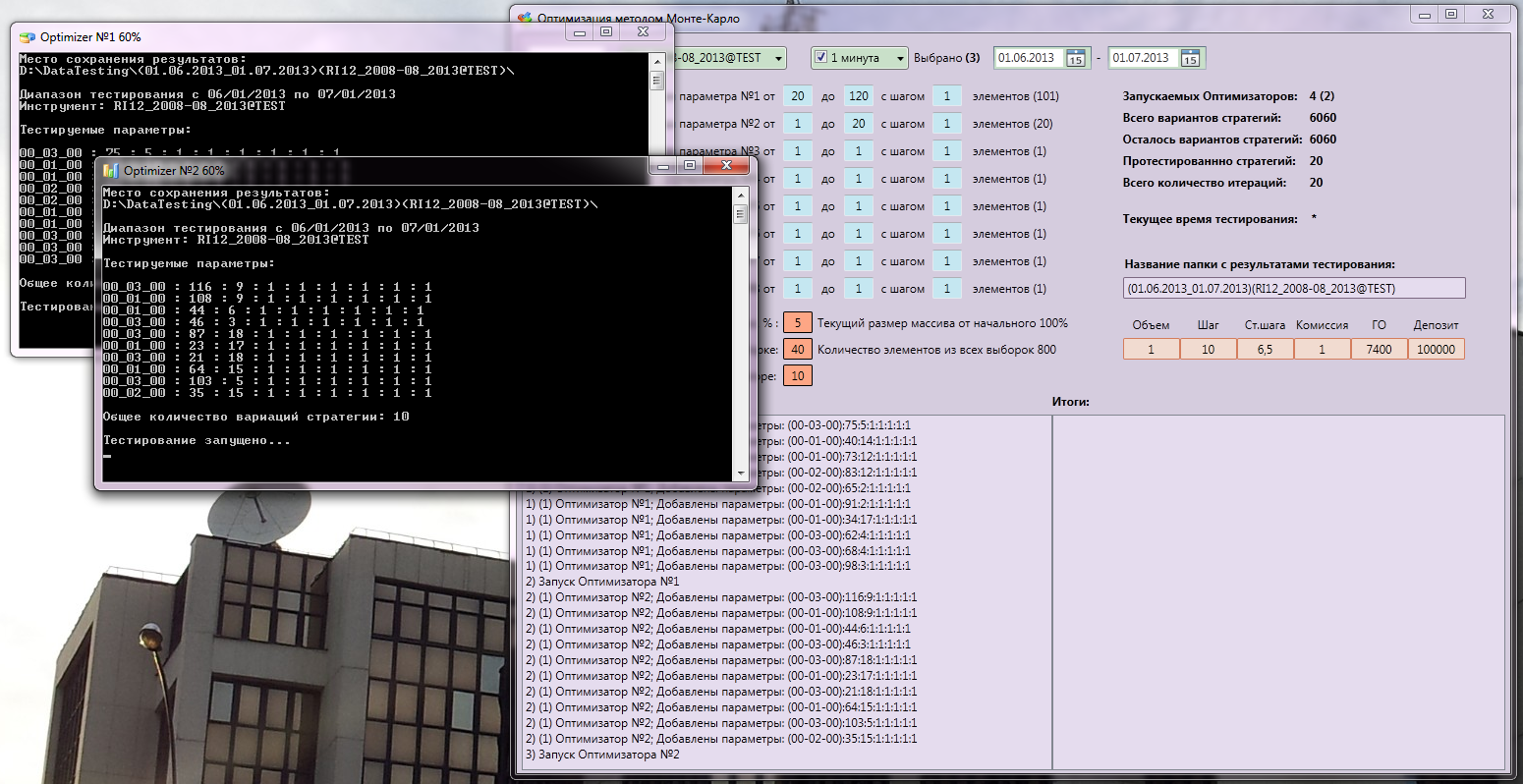
テストの終了。 最良の結果は、88%の予想でした。 さらに、6060のオプションのうち、778のみがテストされ、そのうち116が繰り返されました。
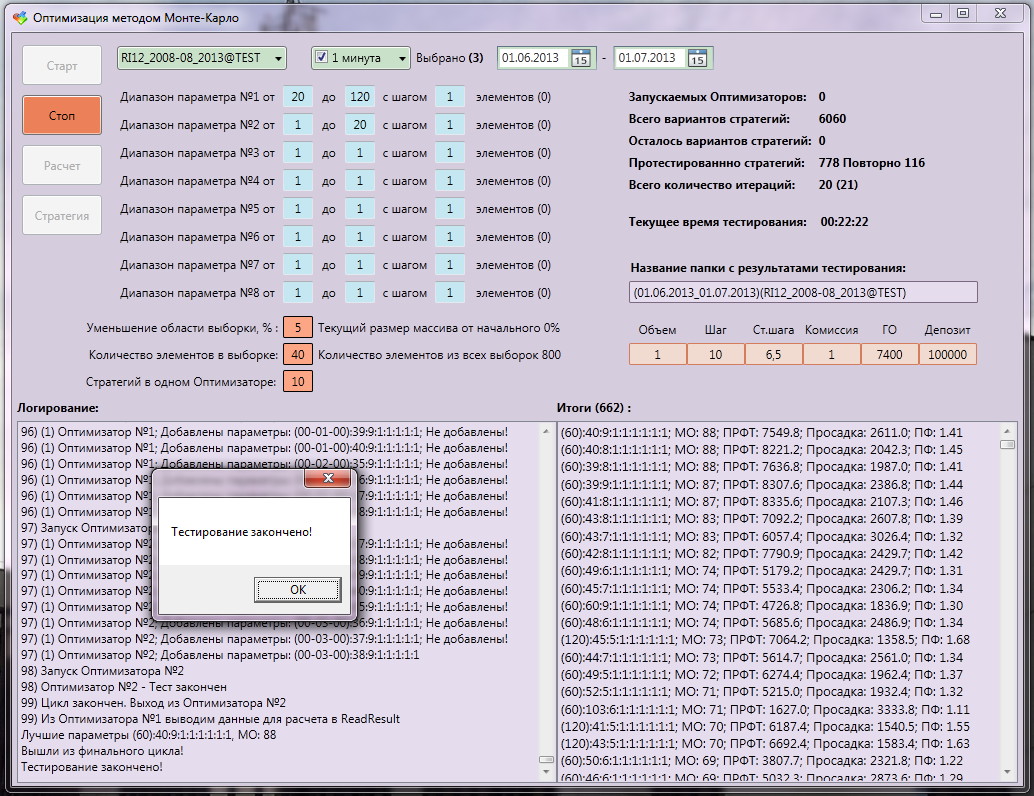
テストの前に戦略がチェックされ、それらが以前にテストされたかどうかが確認されます。極端な場合、密度が増加し、最後に最大値周辺の領域が完全に覆われるためです。 そして、同じことを再びテストすることはありません。 すべてのテスト結果は、アナライザー戦略を視覚化するプログラムによって問題なく処理されます。 GO(セキュリティ保証)をいつでも手動で修正し、開始デポジットをコミッションまたは変更できます。
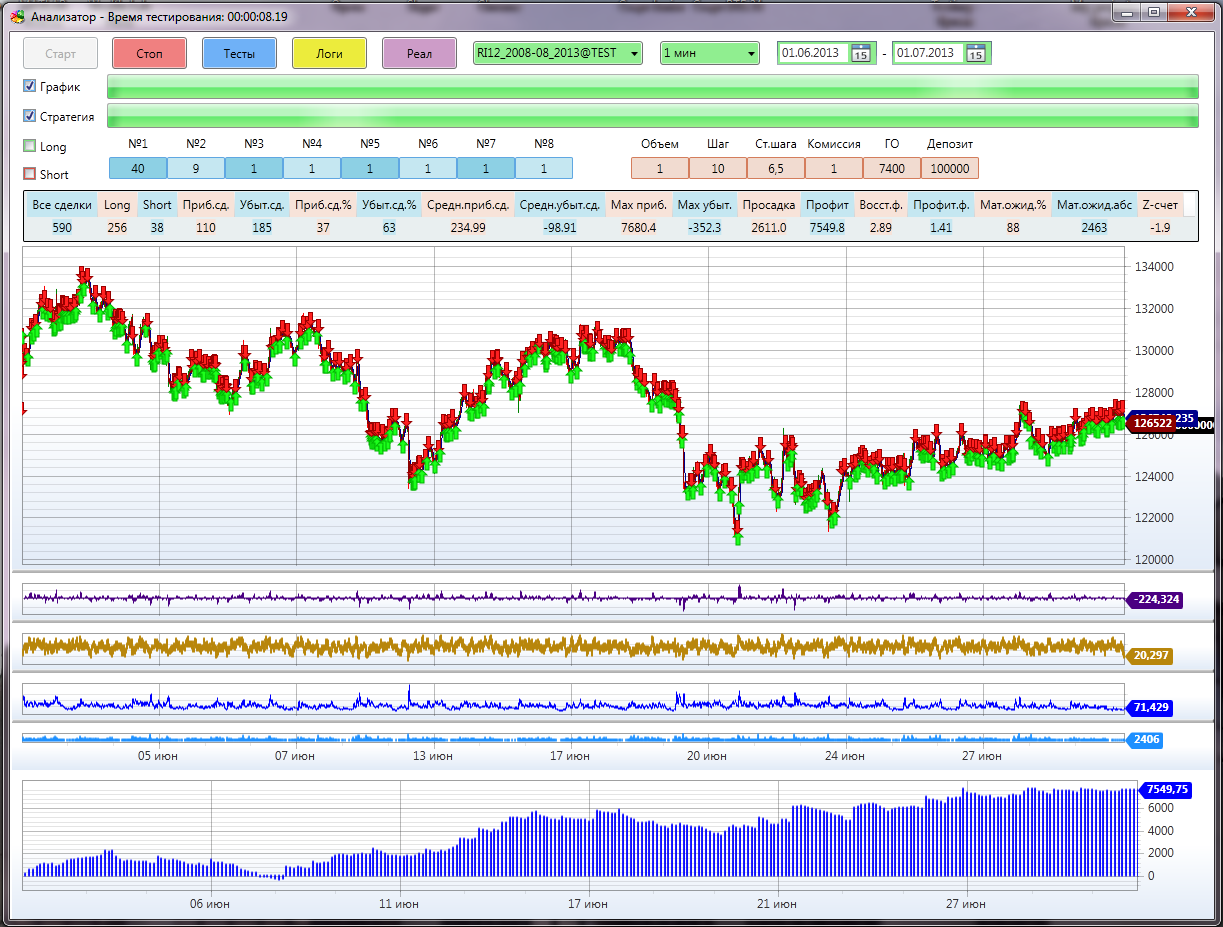
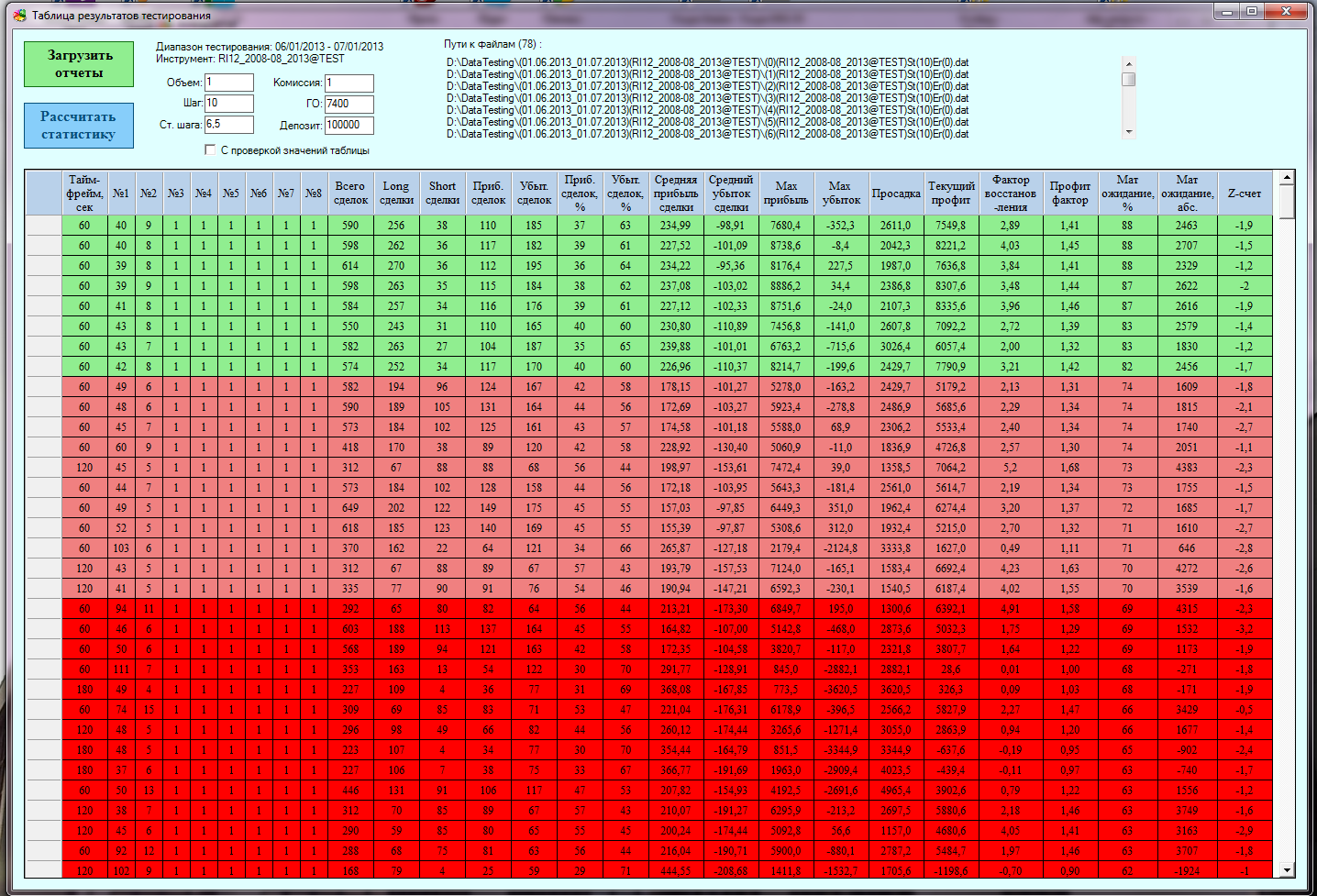
テスト結果のウィンドウには、テストと最適化のすべての結果に関する大きな統計テーブルが表示されます。 任意のパラメーターを列でソートできます。 任意の行をダブルクリックすると、すべてのパラメーターが視覚化ウィンドウに移動するため、セルに何かを打ち込む必要はありません(私は大喜びしていません)。
テスト結果ウィンドウ:
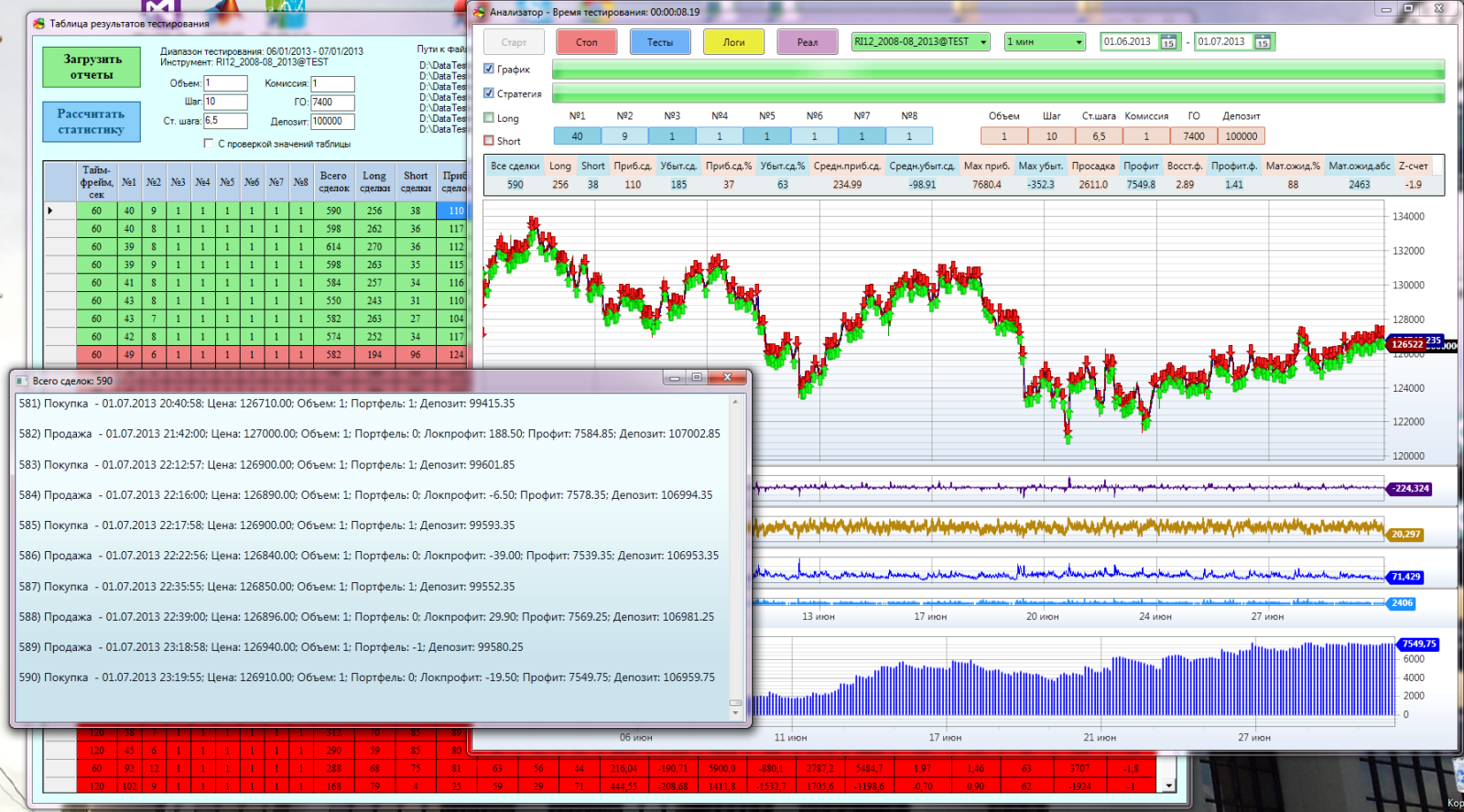
すべて一緒に:
しかし、最初のモンテカルロオプティマイザーテスターを実装し、その作業を調べた後、私は彼が自分の仕事を果たしているが、私が望んでいた品質ではないと結論付けました。 古典的な最適化手法では、新しい反復ごとに最良の値が求められ、その周辺でさらなる研究がすでに行われています。 私の場合、それに関する戦略オプションのマトリックスを切り取りました。
モンテカルロ法による確率的最大探索アルゴリズムの条件付きスキーム:
高度なアルゴリズム
最初の反復の後、最も最初の宇宙探査を実施したときに、次のサンプルの研究領域を何らかの形で縮小する必要があります。 しかし、これまでのところ、私たちはこの空間についてほとんど何も知らず、私には、未知の領域を切り取るのはむしろ無謀であるようです。 一般に、アルゴリズムはグローバルな最大値を検索するように設計されており、ローカルおよびグローバルな最大値すべてに関心があります。
戦略が利益を上げる可能性のあるすべてのパラメーターを知る必要があります。 おそらく、いくつかのパラメーターを使用した戦略は良い利益をもたらしますが、よりリスクが高く、他のパラメーターを使用すると少し利益が少なくなりますが、より安定的でリスクが低くなります。アルゴリズムに従うと、それを見失う可能性があります。 同時に、スペースを詳細に調査することはできません。完全な検索を行うのは非常にコストがかかります。
この場合の対処方法 私は、古典的なスキームから離れて、取引のように行動することにしました。「利益をコントロールすることはできません。リスクをコントロールすることしかできません。」 したがって、私はリスクを冒さないで、研究から良い戦略を誤って削除しないように対策を講じることに決めました。
次に、マトリックスをトリミングする方法は? 調査済みのエリアのみをカットします! つまり、調査対象の最悪の戦略の周辺の微小領域を削除します。 アルゴリズムの本質は、戦略の良い領域を探求せず、悪い領域を探求しないことです。 さらに、最適化の最後に最適な戦略を調査できます。
このようなアルゴリズムの動作は次のとおりです。
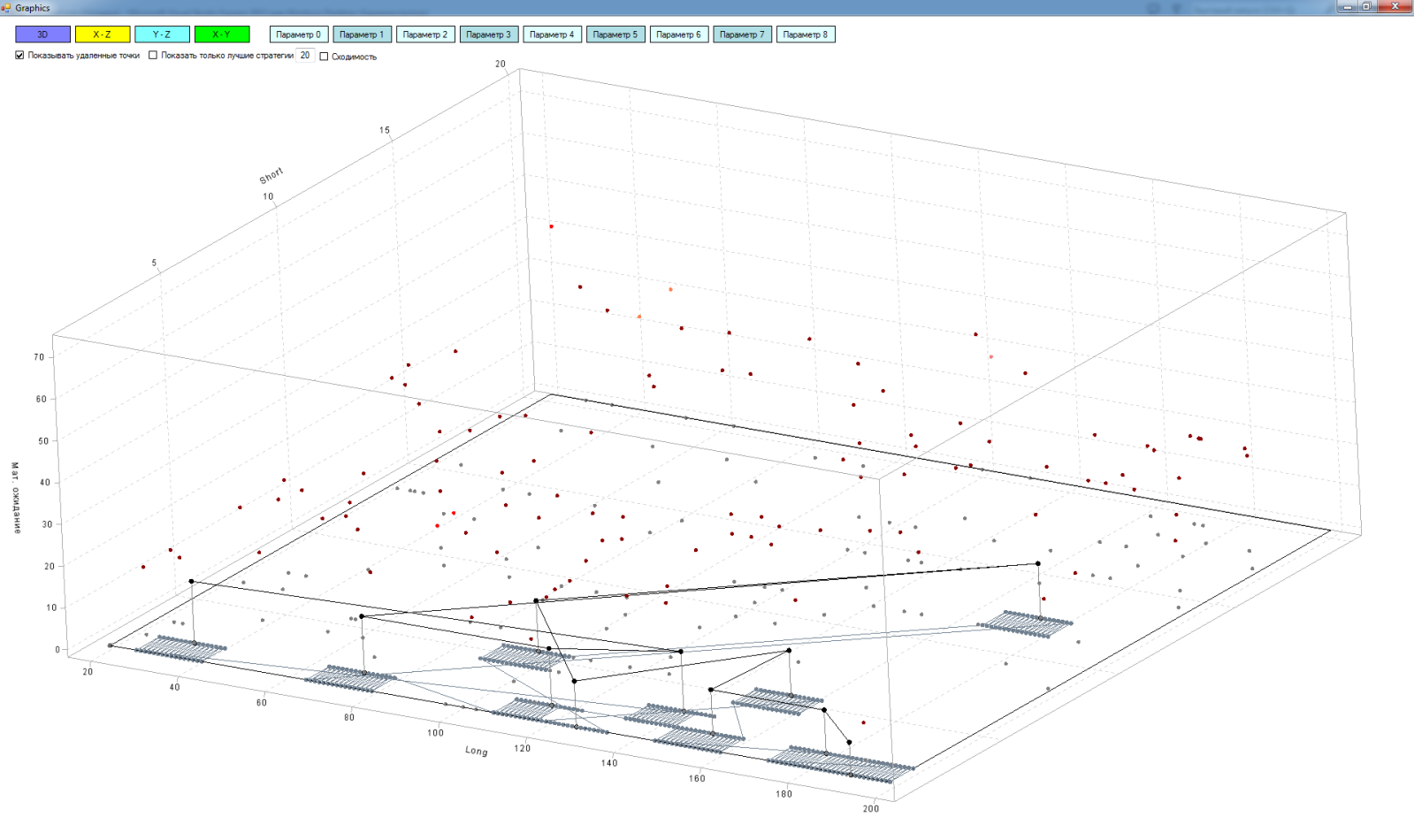
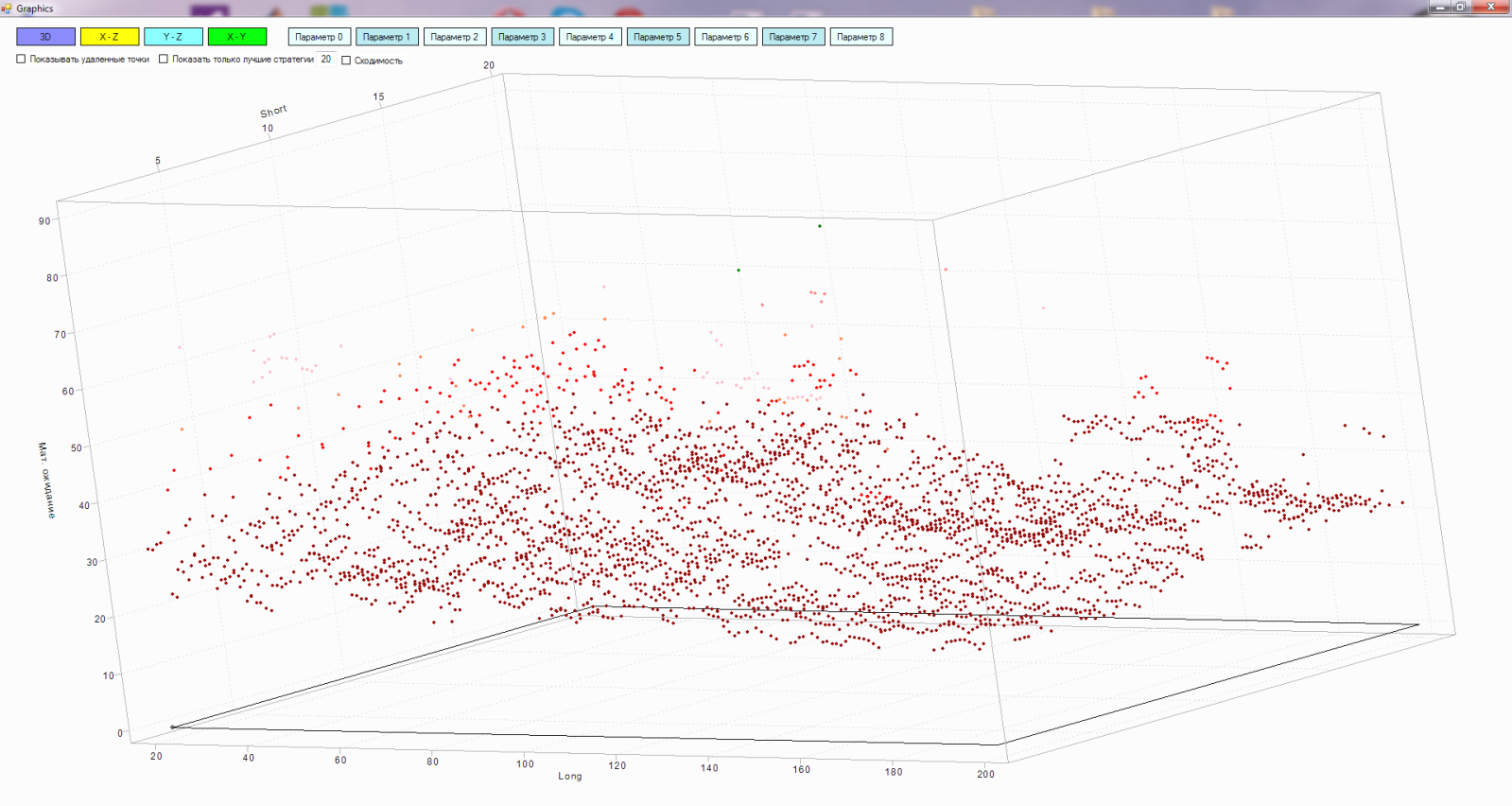
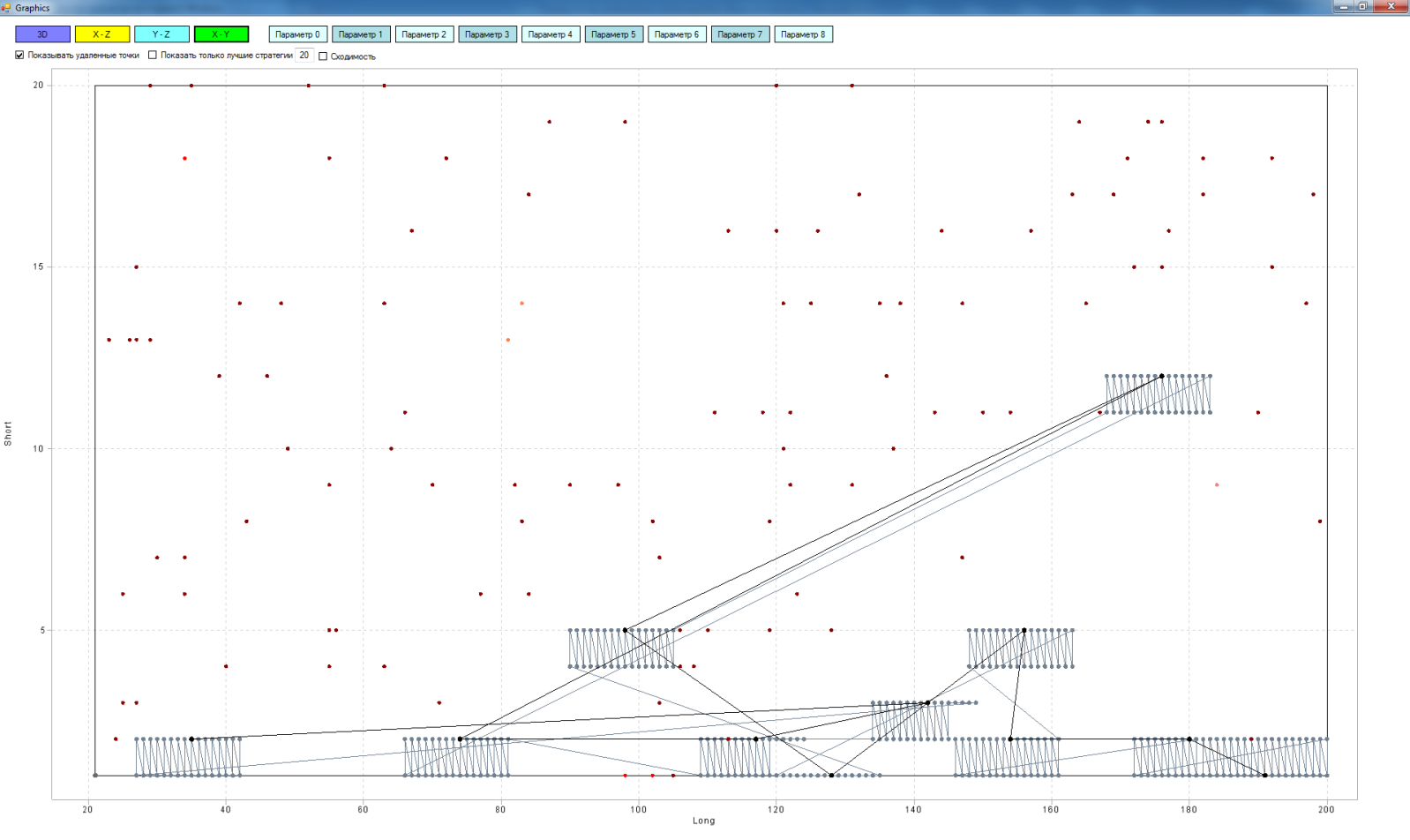
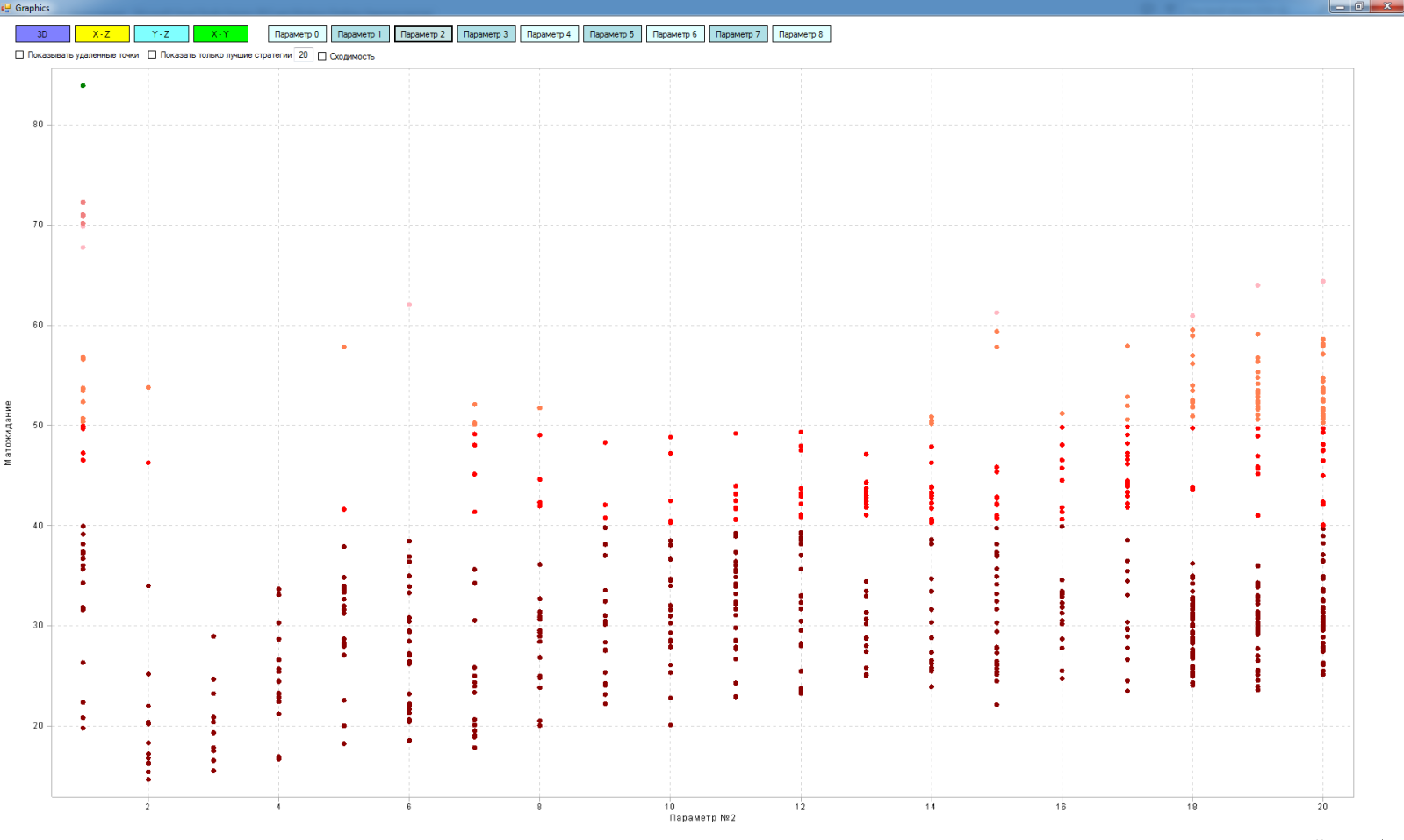
実際、マトリックスは多次元(私の場合、最大9次元)ですが、操作の原理を説明するために、3つのお気に入りの次元すべてを使用します。
- X軸-「長い」移動平均のパラメーター
- Y軸-「短い」移動平均のパラメーター
- Z軸は、「短い」移動平均と「長い」移動平均を交差させる戦略をテストした結果です。この場合、期待マットを取りました。
このスペースのポイントは、「ロング」と「ショート」の移動の値が異なる戦略のテスト済みバージョンです。 ポイントが軽いほど、期待値は高くなります。
原則として、これは2つの座標で表すことができます。
しかし、3つの座標で、私はそれがより好きです-より明確に。
したがって、テスト結果によると、空間内の黒い点は最悪の戦略です。 アルゴリズムのパスをポイント間で接続する線。 平面内の灰色の点は、調査領域から削除する戦略です。 それらの間の線は、マトリックスから戦略を削除するためのアルゴリズムのパスです。 黒い点と灰色の間の線は、最悪の戦略の平面への投影です。 平面上の単一の灰色のドットは、平面ですでにテストされた戦略の投影です。
ここでは、アルゴリズムが最悪の戦略から別の最悪の戦略にどのように移行するかを見ることができます。

アルゴリズムの利点:
最悪の戦略を研究スペースから意図的に削除します。 したがって、次のイテレーションでは、より収益性の高い戦略のある領域を調査し、不要な領域の調査に貴重なテスト時間を浪費しません。 最終的に、私たちの研究領域は、空間のすべての最大に収束します。
その結果、次のような結果が得られます。
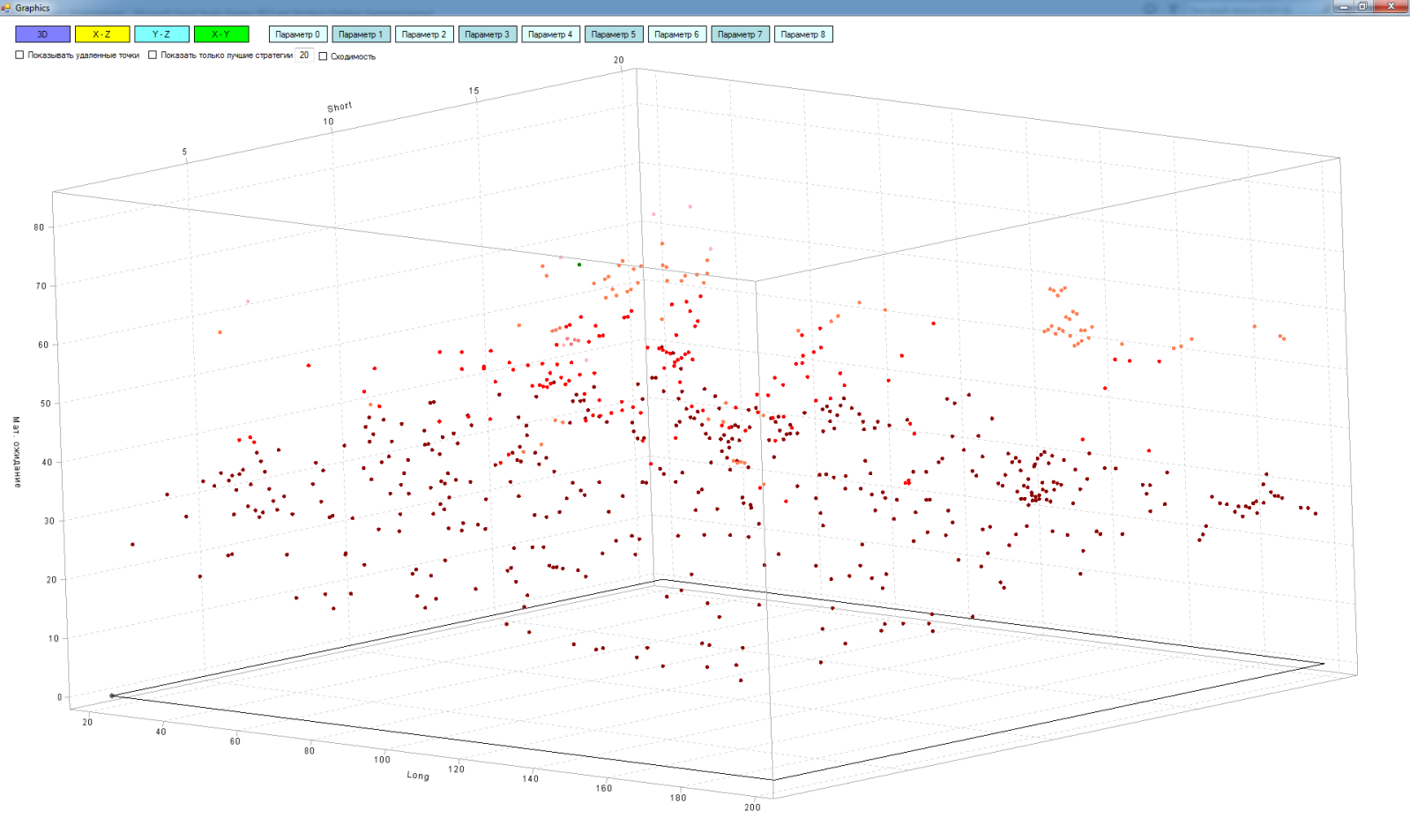
ねじ込みはまだ成功していませんので、表面がないので、ポイントに満足しています。
多次元マトリックスでは、測定の断面を見ることができます:
「期待は長い」

「短い-期待」
研究者テスターオプティマイザーの外観:

すべてのアプリケーションは、完全にC#で記述されています。 最適化を開始する前に、次のパラメーターを構成します。
- 戦略パラメーターの範囲、およびこれらのパラメーターのステップ、
- 調査する時間枠(一度に複数選択できます)、
- 歴史の範囲
- 道具
- 最適化結果を保存する方法、
- 手数料計算パラメータなど
- 初期行列サイズの割合としてのテスト停止基準、
- 各反復後にサンプル領域を何%削減するかを指定します。 反復の総数と最適化の精度はこれに依存します。
- 各反復でサンプル領域からいくつのランダム戦略を探索するか、
- テスターに送信する戦略の数(複数回の訪問が可能です)。 PCのパワー、RAMの量、履歴データの深さに依存します。
- ローカルエリアを削除する最悪の戦略の数、
- 収束について検討する最良の戦略の数、
- 私たちがさらに探求する最良の戦略の周りのローカルエリアのサイズ。
最適化する代わりに、「ランダムバスト」を実行できます。 ここでは、戦略はグリッド上ではなく、ランダムな順序でテストされます。 つまり、いつでも調査を停止し、結果を評価できます。 もちろん、テストする戦略が多ければ多いほど、スペースの概念が明確になります。
空間を探索し、最大値がいくつあるかを大まかに想像してみましょう。 そして、これは私たちに何を与えますか? これまでのところ、ほとんど何も...
それらがランダムか全身かを理解するために、これらの最大値を調査する必要があります。 これを行うために、テスターオプティマイザーは最適な戦略を選択する機会を提供し、さらに、それらの周辺の領域をより詳細に調査しました。 最適化中に見逃した戦略を探ります。 今、私たちは宇宙の極値についてほとんどすべてを知っています! 得られたデータは、クラスタリング、再最適化などについてさらに調査できます。 しかし、それは別の話です!
PSあなた自身についてはあまりありません。 私は約1年前に取引に出会い、最初は手動で取引しましたが、それが私のものではないことに気付きました。 明確なルールと自動化に従って取引する方が良いという結論に達しました。 最初のアルゴリズムは、Quikターミナルのスクリプト言語で作成されましたが、この言語(qpile)は信じられないほど悲惨なものでした。 それから彼はC#に精通し始め、最初の取引ロボットをC#に書いた。 現時点では、アルゴリズム取引のための多機能プラットフォームを作成しています。
皆さんに幸運を! 敬具、アレクセイ。