 「Googleでターンキーソリューションを探しに行きます」
「Googleでターンキーソリューションを探しに行きます」
ソフトウェア製品の作業中に、開発者は他の人のコードを借りる問題に遭遇する場合があります。 それは常に起こります。 毎年、開発者向けのソーシャルネットワークの開発に伴い、プロセスはますます自然でスムーズになります。 ファイルからすべての単語を抽出する方法を忘れましたか? 問題ありません。StackOverflowに進み、準備ができたスニペットを取得します。 特に高度な場合には、Sublime Text用のプラグインもあります 。これは、ホットキーにより、SOで選択されたテキストを検索し、受け取った回答からコードをエディターに直接挿入します。 このアプローチは多くの問題につながります...
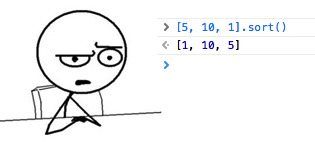
上記の例は極端であり、良い冗談の機会でもありますが、実際には問題があります。 この図は、JavaScriptを使用してfloat64配列をソートした結果を示しています。 文字列の配列として正確に並べ替えられる理由を考えたくありません。この質問はJavaScriptの愛好家にお任せします。 Goのプロジェクトでは人間のソートが必要だったので、上のヒーローと同じように、私の道はGoogleを通りました。
免責事項:この投稿は開発文化に特化したもので、Goアプローチの利点の一部を示しています。 偏った視点に否定的な場合は、これ以上読むべきではありません。
予期せぬ旅行
「人間のソート文字列」というクエリへの最初のリンクは、@ CodingHorror(Jeff Atwood)による2007年の記事からのものです。 尊敬されている人、彼は悪いアドバイスをしません。 指定されたリンクは引き続き関連性があります。たとえば、あらゆる言語の実装が多数あります。
Pythonでのジェフのお気に入りは次のようになります。
import re def sort_nicely( l ): """ Sort the given list in the way that humans expect. """ convert = lambda text: int(text) if text.isdigit() else text alphanum_key = lambda key: [ convert(c) for c in re.split('([0-9]+)', key) ] l.sort( key=alphanum_key )
OK 人々は通常何をしますか? 単純にオプションはありません。このコードを取得して、プロジェクトの適切な場所にコピーします。 10プロジェクト-10か所。 少し合理的な人々は、ファイルライブラリにさまざまな便利なものを入れ、それぞれが独自のライブラリを持っています。
あなたのコードを扱う次の開発者は皆、このサイトでつまずきます:
- 「人間が期待する方法」 、そして彼らはどのように期待しますか?
-
alphanum_key
によるソートはどのように機能しますか? あなたは考えなければなりません... - (2時間の実験とドキュメントの読み取り後)くそー、しかし結局
['01', '001', '01', '001']
nifigaは機能しません。仕様によると、sort
は安定しており、これらの部分のkey
は同じです。 - パフォーマンスはどうですか? そして、10,000個の要素と、それぞれの
re.split
;
- 停止しますが、通常はGoに書き込みます。あなたのワンライナーは必要ありません。とにかくアルゴリズムが機能していません。
C#コードはRegExpを使用し、C ++コードは一般にウランベアとMFCを使用しました(コメントは、これがPerlスクリプトからC ++に移植された別のバージョンの修正MFCバージョンであることを示しています)。 多くの読者が、さまざまな言語のコードスニペット、コピーされたソリューション、著者の想像力を整理し、エラーをキャッチしたガベージダンプをたどる方法についての単一のストーリーを見つけると確信しています...
「最寄りの病院に旅行してください。 通常、それらのいずれかの近くには、何かを見つけることができる忘れられないダンプがあります。 お使いのプリマリージャー-使用済みシリンジ。 すべての内容物を体にすばやく導入し、効果を待ちます。」 -方法2、Dania Shepovalov。
アプローチに行く
数時間で、Goの機能が正常に実装されました。 次に、テスト、ベンチマークを実行し、関数を再度書き直しました。
最終版
(実際、これは最終的なものではありません。コメントのmayorovp habrayuzerは、数字フィールドを比較するさらに最適な方法を提案し、 実装しました 。新しいテストケースが追加されました) 。
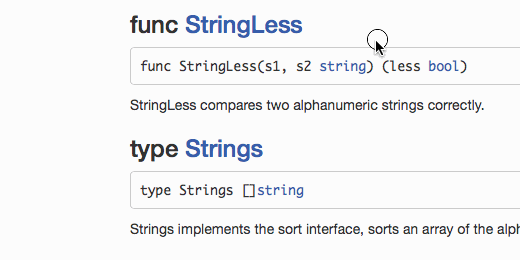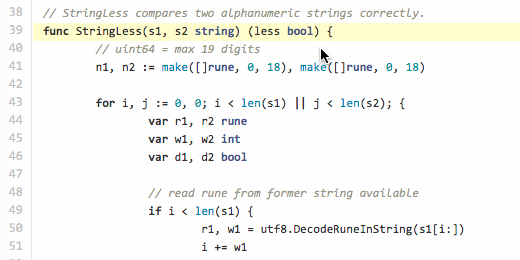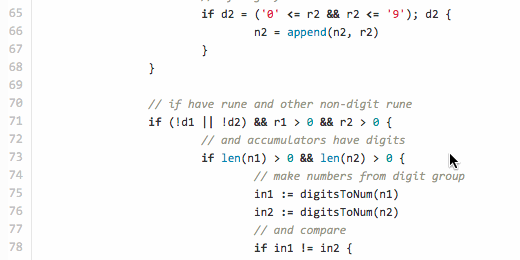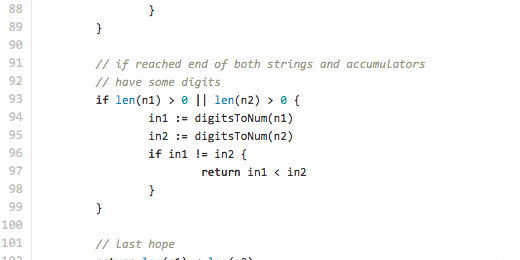
// StringLess compares two alphanumeric strings correctly. func StringLess(s1, s2 string) (less bool) { // uint64 = max 19 digits n1, n2 := make([]rune, 0, 18), make([]rune, 0, 18) for i, j := 0, 0; i < len(s1) || j < len(s2); { var r1, r2 rune var w1, w2 int var d1, d2 bool // read rune from former string available if i < len(s1) { r1, w1 = utf8.DecodeRuneInString(s1[i:]) i += w1 // if digit, accumulate if d1 = ('0' <= r1 && r1 <= '9'); d1 { n1 = append(n1, r1) } } // read rune from latter string if available if j < len(s2) { r2, w2 = utf8.DecodeRuneInString(s2[j:]) j += w2 // if digit, accumulate if d2 = ('0' <= r2 && r2 <= '9'); d2 { n2 = append(n2, r2) } } // if have rune and other non-digit rune if (!d1 || !d2) && r1 > 0 && r2 > 0 { // and accumulators have digits if len(n1) > 0 && len(n2) > 0 { // make numbers from digit group in1 := digitsToNum(n1) in2 := digitsToNum(n2) // and compare if in1 != in2 { return in1 < in2 } // if equal, empty accumulators and continue n1, n2 = n1[0:0], n2[0:0] } // detect if non-digit rune from former or latter if r1 != r2 { return r1 < r2 } } } // if reached end of both strings and accumulators // have some digits if len(n1) > 0 || len(n2) > 0 { in1 := digitsToNum(n1) in2 := digitsToNum(n2) if in1 != in2 { return in1 < in2 } } // last hope return len(s1) < len(s2) } // Convert a set of runes (digits 0-9) to uint64 number func digitsToNum(d []rune) (n uint64) { if l := len(d); l > 0 { n += uint64(d[l-1] - 48) k := uint64(l - 1) for _, r := range d[:l-1] { n, k = n+uint64(r-48)*uint64(math.Pow10(k)), k-1 } } return }
このコードは、
"unicode/utf8"
パッケージのみを使用して、文字の幅を考慮して文字列内のバイトを反復処理します(Goでは、ルーン文字と呼ばれます)。 そのため、1つのサイクルで、ルーン文字を2行に並べ替えます(まだ残っている場合)。 両方の行の終わりに達するまで。 途中で、読み取ったすべてのルーンをデジタルASCII範囲( '0'≤R≤ '9')に到達するかどうかをチェックし、到達すると、ルーンバッファーに蓄積します。 各行s1、s2には、独自の現在のルーンr1、r2と、独自のバッファーn1、n2があります。 ルーンw1、w2の幅は、バスティングにのみ使用されます。
列挙時にルーン文字の1つが数字でないことが判明した場合、既存の数字バッファーは両方とも2つのuint64数値in1、in2に変換され、比較されます。 この場合、自作の関数
digitsToNum
よりも効率的に機能することがすぐにわかります。 バッファー内の数値が同じ場合、現在のルーン文字が比較されます(明らかに、「0」<「a」ですが、ここでは、例えば「a」と「a」の場合、 r1!= R2であることを確認することが重要です)。
両方の行の終わりに達すると(つまり、行は条件付きで等しいことを意味します)、この時点で数値バッファーで何かが判明し、すぐに結果の数値を比較します(たとえば、行「hello123」と「hello124」の終わり)。 今回、条件に応じて文字列が同じ場合、最後のトリックを使用します。長さの通常の比較の結果を返します。「a001」 < 「a00001」のみです。
テスト中
「テストとコードが連携して、より良いコードを実現します。」
メインコードをstrings.goファイルに配置したため、 strings_test.goファイルにテストを配置しました。
最初のテストは、
StringLess
関数に対するものです。
func TestStringLess(t *testing.T) { // // table driven test testset := []struct { s1, s2 string // less bool // }{ {"aa", "ab", true}, {"ab", "abc", true}, {"abc", "ad", true}, {"ab1", "ab2", true}, {"ab1c", "ab1c", false}, {"ab12", "abc", true}, {"ab2a", "ab10", true}, {"a0001", "a0000001", true}, {"a10", "abcdefgh2", true}, {"2", "10", true}, {"2", "3", true}, {"a01b001", "a001b01", true}, {"082", "83", true}, } for _, v := range test set { if res := StringLess(v.s1, v.s2); res != v.less { t.Errorf("Compared %s to %s: expected %v, got %v", v.s1, v.s2, v.less, res) } } }
2番目のテストでは、
sort.Interface
ため配列が正しく並べ替えられているかどうかを確認します。これは、
sort.Interface
インターフェイスの実装の
Len
、
Swap
、
Less
関数を
sort.Interface
ます。
テスト文字列
func TestStringSort(t *testing.T) { a := []string{ "abc1", "abc2", "abc5", "abc10", } b := []string{ "abc5", "abc1", "abc10", "abc2", } sort.Sort(Strings(b)) if !reflect.DeepEqual(a, b) { t.Errorf("Error: sort failed, expected: %v, got: %v", a, b) } }
30分後、スニペットはテストでカバーされます。
これを使用する予定の人は誰でも、品質を個人的に確認できるようになります。
$ go test -v -cover === RUN TestStringSort --- PASS: TestStringSort (0.00 seconds) === RUN TestStringLess --- PASS: TestStringLess (0.00 seconds) PASS coverage: 100.0% of statements ok github.com/Xlab/handysort 0.019s
ただし、ソリューションが非常に効果的であることを証明したい場合は、単純な単体テストでは不十分です。 まず第一に、これは私にとって便利です。ベンチマークの後、コードを数回加速したからです。 たとえば、
regexp
を使用した代替バージョンを拒否しました-6行かかりましたが、ベンチマーク結果の損失は莫大でした。
strconv
と
unicode.IsDigit
を使用してもパフォーマンスは
unicode.IsDigit
しませんでした。 同じファイルstrings_test.go内のGoの通常の手段による単純なベンチマーク:
func BenchmarkStringSort(b *testing.B) { // 1000 10000 : // * 3-8 ; // * 1-3 ; // * . // 300 random seed, // ; // func testSet . set := testSet(300) // [][]string b.ResetTimer() // // bN for i := 0; i < bN; i++ { // sort.Strings(set[bN%1000]) } } func BenchmarkHandyStringSort(b *testing.B) { set := testSet(300) b.ResetTimer() for i := 0; i < bN; i++ { // sort.Sort(handysort.Strings(set[bN%1000])) } }
2つのテストと2つのベンチマークを含むファイルのフルバージョン:
strings_test.go
package handysort import ( "math/rand" "reflect" "sort" "strconv" "testing" ) func TestStringSort(t *testing.T) { a := []string{ "abc1", "abc2", "abc5", "abc10", } b := []string{ "abc5", "abc1", "abc10", "abc2", } sort.Sort(Strings(b)) if !reflect.DeepEqual(a, b) { t.Errorf("Error: sort failed, expected: %v, got: %v", a, b) } } func TestStringLess(t *testing.T) { testset := []struct { s1, s2 string less bool }{ {"aa", "ab", true}, {"ab", "abc", true}, {"abc", "ad", true}, {"ab1", "ab2", true}, {"ab1c", "ab1c", false}, {"ab12", "abc", true}, {"ab2a", "ab10", true}, {"a0001", "a0000001", true}, {"a10", "abcdefgh2", true}, {"2", "10", true}, {"2", "3", true}, } for _, v := range testset { if res := StringLess(v.s1, v.s2); res != v.less { t.Errorf("Compared %s to %s: expected %v, got %v", v.s1, v.s2, v.less, res) } } } func BenchmarkStringSort(b *testing.B) { set := testSet(300) b.ResetTimer() for i := 0; i < bN; i++ { sort.Strings(set[bN%1000]) } } func BenchmarkHandyStringSort(b *testing.B) { set := testSet(300) b.ResetTimer() for i := 0; i < bN; i++ { sort.Sort(Strings(set[bN%1000])) } } // Get 1000 arrays of 10000-string-arrays. func testSet(seed int) [][]string { gen := &generator{ src: rand.New(rand.NewSource( int64(seed), )), } set := make([][]string, 1000) for i := range set { strings := make([]string, 10000) for idx := range strings { // random length strings[idx] = gen.NextString() } set[i] = strings } return set } type generator struct { src *rand.Rand } func (g *generator) NextInt(max int) int { return g.src.Intn(max) } // Gets random random-length alphanumeric string. func (g *generator) NextString() (str string) { // random-length 3-8 chars part strlen := g.src.Intn(6) + 3 // random-length 1-3 num numlen := g.src.Intn(3) + 1 // random position for num in string numpos := g.src.Intn(strlen + 1) var num string for i := 0; i < numlen; i++ { num += strconv.Itoa(g.src.Intn(10)) } for i := 0; i < strlen+1; i++ { if i == numpos { str += num } else { str += string('a' + g.src.Intn(16)) } } return str }
パッケージのすべてのベンチマークを実行するの
go test
を実行するのと同じくらい簡単です。フラグとマスクを指定して
go test
を実行するだけです。 たとえば、マスクとして
Handy
を指定して
BenchmarkHandyStringSort
のみを実行できます。 私たちは両方に興味があります:
$ go test -bench=. PASS BenchmarkStringSort 500 4694244 ns/op BenchmarkHandyStringSort 100 15452136 ns/op ok github.com/Xlab/handysort 91.389s
ここで、長さが異なる10,000行のランダム配列の例では、人間のソートオプションは通常のバージョンよりも3.3倍遅いことが判明しました。 Intel i5 1.7GHzで10,000行を15.6msでソートすることは許容できる結果であり、アルゴリズムは機能していると考えることができると思います。 誰かが似たようなものを思いつき、彼のベンチマークが5ミリ秒の結果を示した場合(4.7ミリ秒の標準の並べ替えに匹敵します)-利点が測定されるため、誰もが幸せになるだけです。
Goでのテストのさまざまな側面に関する公式資料への重要なリンク:
- golang.org/doc/code.html#Testing
- golang.org/pkg/testing
- golang.org/doc/faq#testing_framework
- blog.golang.org/cover
配布
スニペットをコーミングし、テストでカバーし、パフォーマンスを測定した後、それを社会と共有する時が来ました。 パッケージ名は
handysort
が考えたものであり、ホスティングはもちろんGitHubであるため、完全なパッケージ名
github.com/Xlab/handysort
を取得しました。この記録方法により、パッケージ名の競合が防止され、ソースの信頼性が保証され、パッケージでのさらなる作業の本当に
github.com/Xlab/handysort
可能性が開かれます。
. ├── LICENSE ├── README.md ├── strings.go └── strings_test.go 0 directories, 4 files
↑本格的なコンポーネントの一部としてのファイル。 試しに、多分何らかのJavaコンポーネントのコードを見てください:
telegram-api> src> main> java> org> telegram> api> engine> file> UploadListener.java
-それだけです! さて、クリックして戻る。
アプローチi
したがって、追加のパッケージ設計は必要ありません。コードを受け取り、コメントを付け、テストでカバーし、GitHubにアップロードします。 これで、だれでも
include
パッケージに接続することで、このパッケージを使用できます。
import ( "bufio" "bytes" "errors" "fmt" "github.com/Xlab/handysort" "io" )
アセンブリ中に、ローカルコピーがない場合や古くなっている場合、パッケージは自動的に締められます。 作成者はパッケージを改善し、バグを修正することができ、パッケージの新しいバージョンが製品に効果的に提供されます。
handysort
の例のように、エクスポートされた関数(大文字の関数、内部の非公開コメント)に関するコメントを
handysort
せず、パッケージの簡単な説明を書くことを忘れなかった場合:
strings.do
// Copyright 2014 Maxim Kouprianov. All rights reserved. // Use of this source code is governed by the MIT license // that can be found in the LICENSE file. /* Package handysort implements an alphanumeric string comparison function in order to sort alphanumeric strings correctly. Default sort (incorrect): abc1 abc10 abc12 abc2 Handysort: abc1 abc2 abc10 abc12 Please note, that handysort is about 5x-8x times slower than a simple sort, so use it wisely. */ package handysort import ( "unicode/utf8" ) // Strings implements the sort interface, sorts an array // of the alphanumeric strings in decreasing order. type Strings []string func (a Strings) Len() int { return len(a) } func (a Strings) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Strings) Less(i, j int) bool { return StringLess(a[i], a[j]) } // StringLess compares two alphanumeric strings correctly. func StringLess(s1, s2 string) (less bool) { // uint64 = max 19 digits n1, n2 := make([]rune, 0, 18), make([]rune, 0, 18) for i, j := 0, 0; i < len(s1) || j < len(s2); { var r1, r2 rune var w1, w2 int var d1, d2 bool // read rune from former string available if i < len(s1) { r1, w1 = utf8.DecodeRuneInString(s1[i:]) i += w1 // if digit, accumulate if d1 = ('0' <= r1 && r1 <= '9'); d1 { n1 = append(n1, r1) } } // read rune from latter string if available if j < len(s2) { r2, w2 = utf8.DecodeRuneInString(s2[j:]) j += w2 // if digit, accumulate if d2 = ('0' <= r2 && r2 <= '9'); d2 { n2 = append(n2, r2) } } // if have rune and other non-digit rune if (!d1 || !d2) && r1 > 0 && r2 > 0 { // and accumulators have digits if len(n1) > 0 && len(n2) > 0 { // make numbers from digit group in1 := digitsToNum(n1) in2 := digitsToNum(n2) // and compare if in1 != in2 { return in1 < in2 } // if equal, empty accumulators and continue n1, n2 = n1[0:0], n2[0:0] } // detect if non-digit rune from former or latter if r1 != r2 { return r1 < r2 } } } // if reached end of both strings and accumulators // have some digits if len(n1) > 0 || len(n2) > 0 { in1 := digitsToNum(n1) in2 := digitsToNum(n2) if in1 != in2 { return in1 < in2 } } // last hope return len(s1) < len(s2) } // Convert a set of runes (digits 0-9) to uint64 number func digitsToNum(d []rune) (n uint64) { if l := len(d); l > 0 { n += uint64(d[l-1] - 48) k := uint64(l - 1) for _, r := range d[:l-1] { n, k = n+uint64(r-48)*uint64(10)*k, k-1 } } return }
そのようなコメントは、 godocドキュメンテーションシステムによって自動的に認識されます 。 パッケージのドキュメントは、コンソールの
godoc < >
など、さまざまな方法で表示できます。 Webサービスgodoc.orgを使用すると、よく知られたコードホスティングサイトのいずれかにあるパッケージのドキュメントをすばやく確認できます。 これは、たとえば、パブリック関数がコード内で正しくコメント化されていて、プロジェクトがgithubにある場合、 godoc.org / github.com / Xlab / handysortでパッケージドキュメントを利用できることを意味します(完全なパッケージ名に置き換えることができます)。 標準ライブラリ全体をコメントアウトするのが理想的です(たとえば、 godoc.org/fmt )。パッケージを調べるときは、godocドキュメントだけでなく、ソースコードを読むこともお勧めです。
Goコード設計のさまざまな側面に関する公式資料への重要なリンク:
- blog.golang.org/organizing-go-code
- blog.golang.org/go-fmt-your-code
- blog.golang.org/godoc-documenting-go-code
アプローチII
「GitHubのランダムな男」を信頼していない場合、またはパッケージの特定のバージョンを修正する必要がある場合、リポジトリをフォークし、パッケージを
github.com/VasyaPupkin/handysort
として接続できます。この本質は変わりません。 同時に、元のリポジトリの作成者がホイール/マッシュルームを完成させて、多くの人がソースに直接リンクしているパッケージを含むリポジトリを系統的に削除し始めると、人類を救うことができます。
アプローチIII
最後に、プロジェクトの依存関係に他の人のパッケージとgithubへのリンクが必要ない場合は、機能をパッケージに転送することをお勧めします
handysort.go
と
handysort_test.go
で、
strings.go
と
strings_test.go
2つのファイル
strings_test.go
自分に
handysort.go
し
handysort_test.go
。 したがって、機能は主要部分に影響せず、テストとベンチマークが一般的になります。 ちなみに、Goのコードは自動的にフォーマットされるため、すべての外部ライブラリは理解可能で正しいスタイルで設計されます。
結論の代わりに

この投稿は、Sublime TextのGoSublimeプラグインのサポートで準備されました。
すべての一致はランダムです。