- ドキュメントには、Amazonがメッセージの順序を維持しようとしていると書かれています。
- ロングポーリングを使用する場合、メッセージの受信速度はどれくらいですか?
- バッチ処理の速度はどれくらいですか?
問題の声明
erlang上のAWSで最もサポートされているライブラリはerlcloud [1]です。githubに示されているように、ライブラリを初期化してstartメソッドとconfigureメソッドを呼び出すだけです。 私のメッセージには、次の関数によって生成されたランダムな文字セットが含まれます。
random_string(0) -> []; random_string(Length) -> [random_char() | random_string(Length-1)]. random_char() -> random:uniform(95) + 31 .
速度測定では、タイマーを使用する既知の関数tcを使用しますが、いくつかの変更があります。
test_avg(M, F, A, R, N) when N > 0 -> {Ret, L} = test_loop(M, F, A, R, N, []), Length = length(L), Min = lists:min(L), Max = lists:max(L), Med = lists:nth(round((Length / 2)), lists:sort(L)), Avg = round(lists:foldl(fun(X, Sum) -> X + Sum end, 0, L) / Length), io:format("Range: ~b - ~b mics~n" "Median: ~b mics~n" "Average: ~b mics~n", [Min, Max, Med, Avg]), Ret. test_loop(_M, _F, _A, R, 0, List) -> {R, List}; test_loop(M, F, A, R, N, List) -> {T, Result} = timer:tc(M, F, [R|A]), test_loop(M, F, A, Result, N - 1, [T|List]).
変更はテスト対象の関数の呼び出しに関連します。このバージョンでは、引数Rを追加しました。これにより、前の開始で返された値を使用できます。これは、メッセージ番号を生成し、メッセージ受信時のミキシングに関する追加情報を収集するために必要です。 したがって、番号付きのメッセージを送信する機能は次のようになります。
send_random(N, Queue) -> erlcloud_sqs:send_message(Queue, [N + 1 | random_string(6000 + random:uniform(6000))]), N + 1 .
そして、統計収集を伴う彼女の呼び出し:
test_avg(?MODULE, send_random, [QueueName], 31, 20)
ここで31は最初のメッセージの番号です。この番号は偶然に選択されません。事実、アーランは数字と文字列のシーケンスをあまり区別せず、メッセージでは文字番号31になります。SQSに低い番号を送信できますが、この場合は連続した範囲が取得されますsmall(#x9 | #xA | #xD | [#x20から#xD7FF] | [#xE000から#xFFFD] | [#x10000から#x10FFFF]、詳細[2])。有効な範囲を離れると例外が発生します。 したがって、send_random関数はメッセージを生成し、Queueという名前のキューにメッセージを送信します。このメッセージの先頭は番号を決定する番号であり、この関数は次の番号の番号を返します。 test_avg関数はQueueNameを取ります。これはsend_random関数の2番目の引数になります。最初の引数は繰り返しの数と数です。
メッセージを受信して順序を確認する関数は次のようになります。
checkorder(N, []) -> N; checkorder(N, [H | T]) -> [{body, [M | _]}|_] = H, K = if M > N -> M; true -> io:format("Wrong ~b less than ~b~n", [M, N]), N end, checkorder(K, T). receive_checkorder(LastN, Queue) -> [{messages, List} | _] = erlcloud_sqs:receive_message(Queue), remove_list(Queue, List), checkorder(LastN, List).
メッセージを削除する:
remove_msg(_, []) -> wrong; remove_msg(Q, [{receipt_handle, Handle} | _]) -> erlcloud_sqs:delete_message(Q, Handle); remove_msg(Q, [_ | T]) -> remove_msg(Q, T). remove_list(_, []) -> ok; remove_list(Q, [H | T]) -> remove_msg(Q, H), remove_list(Q, T).
削除のために送信されたリストには、多くの追加情報(メッセージ本文など)が含まれています。削除関数は、要求を形成するために必要なreceive_handleを見つけます。
メッセージの混合
今後は、メッセージの数が少ない場合でもミキシングは非常に重要であり、追加の問題が発生したと言えます。ミキシングの程度を評価する必要があります。 残念ながら、良い基準は見つかりませんでした。正しい位置で最大および平均の不一致を導き出すことにしました。 このようなウィンドウのサイズを知っていると、受信時にメッセージの順序を復元できますが、もちろん処理速度は低下します。
この差を計算するには、メッセージ順序チェック機能のみを変更するだけで十分です。
checkorder(N, []) -> N; checkorder({N, Cnt, Sum, Max}, [H | T]) -> [{body, [M | _]}|_] = H, {N1, Cnt1, Sum1, Max1} = if M < N -> {N, Cnt + 1, Sum + N - M, if Max < N - M -> N - M; true -> Max end }; true -> {M, Cnt, Sum, Max} end, checkorder({N1, Cnt1, Sum1, Max1}, T).
シリーズ実行関数の呼び出しは次のようになります。
{_, Cnt, Sum, Max} = test_avg(?MODULE, receive_checkorder, [QueueName], {0, 0, 0, 0}, Size)
必要以上に遅れた要素の数、受信した要素の最大値からの距離と最大オフセットの合計を取得します。 ここで私にとって最も興味深いことは、最大バイアスです、他の特性は物議を醸すと呼ばれる可能性があり、それらはあまりうまく計算されない可能性があります(たとえば、1つの要素が先に読み取られた場合、それより前に行かなければならないすべての要素はこの場合再配置されたと見なされます) 結果へ:
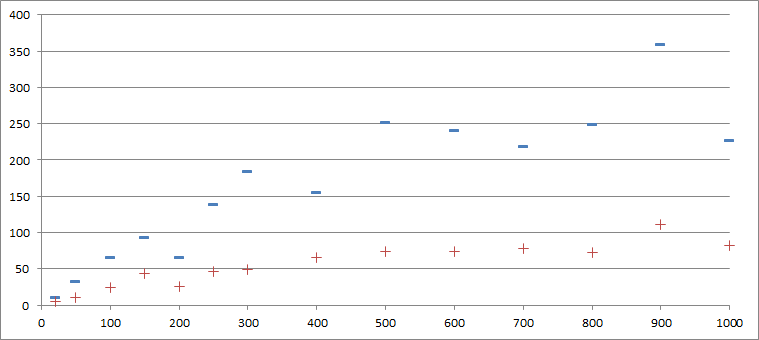
| サイズ(個) | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 最大オフセット(個) | 11 | 32 | 66 | 93 | 65 | 139 | 184 | 155 | 251 | 241 | 218 | 249 | 359 | 227 |
| 平均変位(pcs) | 5.3 | 10.5 | 23.9 | 43 | 25.6 | 45.9 | 48.4 | 65.6 | 74.2 | 74.2 | 78.3 | 72.3 | 110.8 | 82.8 |
最初の行はキュー内のメッセージの数、2番目は最大オフセット、3番目は平均オフセットです。
結果は私を驚かせました、メッセージは単に混同するだけでなく、これには単に境界がありません。つまり、メッセージの数が増えると、表示されるウィンドウのサイズを大きくする必要があります。 グラフ形式でも同じ:
長いポーリング
すでに書いたように、Amazon SQSはサブスクリプションをサポートしていません。これにはAmazon SNSを使用できますが、複数のハンドラーを含む高速キューが必要な場合、これは適切ではありません。Amazonが実装するロングポーリングを使用してメッセージを待つことができます最大20秒、およびSQSは呼び出されたメソッドの数によって課金されるため、キューのコストを大幅に削減する必要がありますが、問題はここにあります:少数のメッセージ(公式文書による)では、キューが返されない可能性があります 何もありません。 この動作は、イベントにすばやく応答する必要があるキューにとって重要です。一般的に言えば、これが頻繁に発生する場合、SQS応答時間による定期的なポーリングと同等になるため、ロングポーリングはあまり意味がありません。
検証のために、2つのプロセスを作成します。1つはランダムにメッセージを送信し、もう1つは常にロングポーリングになり、メッセージの送受信の瞬間は後で比較するために保存されます。 このモードを有効にするには、キューパラメータで受信メッセージ待機時間= 20秒を設定します。
send_sleep(L, Queue) -> timer:sleep(random:uniform(10000)), Call = erlang:now(), erlcloud_sqs:send_message(Queue, random_string(6000 + random:uniform(6000))), [Call | L].
この関数は、ランダムなミリ秒の間スリープ状態になり、その後、瞬間を記憶してメッセージを送信します
remember_moment(L, []) -> L; remember_moment(L, [_ | _]) -> [erlang:now() | L]. receive_polling(L, Queue) -> [{messages, List} | _] = erlcloud_sqs:receive_message(Queue), remove_list(Queue, List), remember_moment(L, List).
これらの2つの機能を使用すると、メッセージを受信し、これが発生した瞬間を記憶できます。 これらの関数をspawnで同時に実行すると、2つのリストが得られますが、その違いはメッセージに対する反応時間を示しています。 メッセージが混在する可能性があるという事実を考慮していません。一般に、これは単純に反応時間をさらに増加させます。
何が起こったのか見てみましょう:
| 睡眠間隔 | 10,000 | 7500 | 5000 | 2500 |
|---|---|---|---|---|
| 最小時間(秒) | 0.27 | 0.28 | 0.27 | 0.66 |
| 最大時間(秒) | 10.25 | 7.8 | 5.36 | 5.53 |
| 平均時間(秒) | 1.87 | 1.87 | 1.84 | 1.88 |
最初の行は、送信プロセスの最大遅延として設定された値です。 つまり、10秒、7.5秒...残りの行は、メッセージの最小、最大、および平均待ち時間です。
グラフ形式でも同じ:

平均時間はすべての場合で同じであることが判明し、そのような単一メッセージの送信の間に平均で2秒が経過したと言うことができます。 十分に長い。 このテストでは、サンプルは20メッセージと非常に小さいため、最小値と最大値は何らかの依存関係よりも運の問題です。
バッチ送信
最初に、メッセージ送信時のキューの「ウォームアップ」の効果がどれほど重要かを確認しましょう。
| レコード数 | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 最小時間(秒) | 0.1 | 0.1 | 0.1 | 0.09 | 0.09 | 0.09 | 0.09 | 0.1 | 0.09 | 0.1 | 0.1 | 0.09 | 0.09 | 0.09 |
| 最大時間(秒) | 0.19 | 0.37 | 0.41 | 0.41 | 0.37 | 0.38 | 0.37 | 0.43 | 0.39 | 0.66 | 0.74 | 0.48 | 0.53 | 0.77 |
| 平均時間(秒) | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 |
グラフの形式でも同じ:

つまり、ウォームアップは観測されていません。つまり、キューはこれらのデータ量でほぼ同じように動作し、何らかの理由で最大値は増加しますが、平均値と最小値はその場所に残ります。
削除を伴う読み取りについても同じ
| レコード数 | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 最小時間(秒) | 0.001 | 0.14 | 0 | 0.135 | 0 | 0.135 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 最大時間(秒) | 0.72 | 0.47 | 0.65 | 0.65 | 0.69 | 0.51 | 0.75 | 0.75 | 0.76 | 0.73 | 0.82 | 0.79 | 0.74 | 0.91 |
| 平均時間(秒) | 0.23 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.2 | 0.2 | 0.2 | 0.2 | 0.21 |

飽和もありません。平均は約200msです。 読み取りは即座に(1ミリ秒よりも速い)行われることもありましたが、これはメッセージが受信されなかったことを意味します。ドキュメントによると、SQSサーバーはこれを行うことができ、メッセージを再度要求するだけです。
ブロックとマルチスレッドのテストに直接行きましょう。
残念ながら、erlcloudライブラリにはメッセージをバッチ送信するための関数は含まれていませんが、そのような関数を既存のものに基づいて実装することは難しくありません;メッセージ送信関数では、リクエストを次のように変更する必要があります。
Doc = sqs_xml_request(Config, QueueName, "SendMessageBatch", encode_message_list(Messages, 1)),
そして、リクエストを形成する機能を追加します。
encode_message_list([], _) -> []; encode_message_list([H | T], N) -> MesssageId = string:concat("SendMessageBatchRequestEntry.", integer_to_list(N)), [{string:concat(MesssageId, ".Id"), integer_to_list(N)}, {string:concat(MesssageId, ".MessageBody"), H} | encode_message_list(T, N + 1)].
ライブラリは、たとえば2011年10月1日にAPIのバージョンも修正する必要があります。修正しない場合、Amazonはリクエストへの応答としてBadリクエストを返します。
テスト機能は、他のテストで使用される機能に似ています。
gen_messages(0) -> []; gen_messages(N) -> [random_string(5000 + random:uniform(1000)) | gen_messages(N - 1)]. send_batch(N, Queue) -> erlang:display(erlcloud_sqs:send_message_batch(Queue, gen_messages(10))), N + 1 .
ここでは、パッケージ全体が64kbに収まるようにメッセージの長さを変更する必要がありました。そうしないと、例外がスローされます。
記録用に次のデータが取得されました。
| スレッド数 | 0 | 1 | 2 | 4 | 5 | 10 | 20 | 50 | 100 |
|---|---|---|---|---|---|---|---|---|---|
| 最大遅延(秒) | 0.452 | 0.761 | 0.858 | 1.464 | 1.698 | 3.14 | 5.272 | 11.793 | 20.215 |
| 平均遅延(秒) | 0.118 | 0.48 | 0.436 | 0.652 | 0.784 | 1.524 | 3.178 | 9.1 | 19.889 |
| メッセージ時間(秒) | 0.118 | 0.048 | 0.022 | 0.017 | 0.016 | 0.016 | 0.017 | 0.019 | 0.02 |
ここで、0は1ストリームで1つずつ読み取り、次に1ストリームで10読み取り、10から2スレッド、10から4スレッドなどの読み取りを意味します。
読むために:
| スレッド数 | 0 | 1 | 2 | 4 | 5 | 10 | 20 | 50 | 100 |
|---|---|---|---|---|---|---|---|---|---|
| 最大遅延(秒) | 0.762 | 2.998 | 2.511 | 2.4 | 2.606 | 2.751 | 4.944 | 11.653 | 18.517 |
| 平均遅延(秒) | 0.205 | 1.256 | 1.528 | 1.566 | 1.532 | 1.87 | 3.377 | 7.823 | 17.786 |
| メッセージ時間(秒) | 0.205 | 0.126 | 0.077 | 0.04 | 0.031 | 0.02 | 0.019 | 0.017 | 0.019 |
読み取りおよび書き込みの帯域幅を示すグラフ(1秒あたりのメッセージ数):

青は書き込み中、赤は読み取り中です。
このデータから、10ストリームの領域での書き込みと読み取りで最大スループットが達成されると結論付けることができます-約50、ストリームの数がさらに増加しても、単位時間あたりに送信されるメッセージの数は増加しません。
結論
Amazon SQSは、メッセージの順序を大幅に変更し、応答時間とスループットがあまり良くないことがわかります。これには、信頼性と少額(メッセージ数が少ない場合)の料金でしか対処できません。 つまり、速度が重要でない場合は、メッセージが混同されていても問題ありません。また、キューサーバー管理者を管理または雇用する必要はありません。これはあなたの選択です。