
コンピューターサイエンスの研究に興味を持ったのはコンパイラーでした。 私はそれがすべて魔法だと思っていました。彼らは私の不完全に書かれたコードでさえそれを読んでコンパイルすることができます。 コンパイラーのコースを受講したとき、このプロセスが非常にシンプルでわかりやすいと感じ始めました。
内容
Python#1のゼロからのシンプルなインタープリター
Python#2のゼロからのシンプルなインタープリター
Python#3のゼロからのシンプルなインタープリター
Python#4のゼロからのシンプルなインタープリター
Python#2のゼロからのシンプルなインタープリター
Python#3のゼロからのシンプルなインタープリター
Python#4のゼロからのシンプルなインタープリター
このシリーズの記事では、通常の命令型言語IMP (IMperative Language)の単純なインタープリターを作成することにより、この単純さの一部を捉えようとします。 インタプリタはシンプルで広く知られている言語であるため、Pythonで記述されます。 また、pythonコードは擬似コードに似ており、知らない場合でも[python]、コードを理解できます。 構文解析は、ゼロから書かれた単純なコンビネーターのセットを使用して実行されます(次のパートで詳しく説明します)。 sys (I / Oの場合)、 re (レクサーの正規表現)、 unittest (クラフトの状態をテストするため)を除き、追加のライブラリは使用されません。
IMPエッセンス
まず、なぜインタープリターを作成するのかを説明しましょう。 IMPは、次の構成を持つ非現実的なシンプルな言語です。
割り当て(すべての変数はグローバルであり、整数のみを受け入れます):
x := 1
条件:
if x = 1 then y := 2 else y := 3 end
whileループ:
while x < 10 do x := x + 1 end
複合演算子(区切られた; ):
x := 1; y := 2
これは単なるおもちゃの言語です。 ただし、PythonやLuaなどのユーティリティレベルに拡張できます。 できるだけシンプルにしたかっただけです。
そして、これは階乗を計算するプログラムの例です:
n := 5; p := 1; while n > 0 do p := p * n; n := n - 1 end
IMPは入力データの読み方を知りません。 プログラムの開始時に、必要な変数をすべて作成し、それらに値を割り当てる必要があります。 また、言語は何も出力できません。インタープリターは結果を最後に出力します。
通訳者の構造
インタープリターのコアは、中間表現(IR)にすぎません。 メモリ内のIMPプログラムを表します。 IMPは3ルーブルと同じくらい単純なので、IRは言語の構文に直接対応します。 構文の単位ごとにクラスを作成します。 もちろん、より複雑な言語では、解析または実行がはるかに簡単なセマンティック表現を使用する必要があります。
解釈の3つの段階のみ:
- ソースコード文字をトークンに解析します。
- すべてのトークンを抽象構文ツリー(AST)に収集します。 ASTは私たちのIRです。
- ASTを実行し、最後に結果を出力します。
文字をトークンに分割するプロセスは字句解析と呼ばれ、字句解析プログラムがこれを行います。 トークンは、数字、識別子、キーワード、演算子など、プログラムの最も基本的な部分を含む短い消化可能な文字列です。 レクサーはインタプリタによって無視されるため、スペースとコメントをスキップします。
ASTトークンアセンブリプロセスは解析と呼ばれます。 パーサーは、プログラムの構造を実行可能な形式に抽出します。
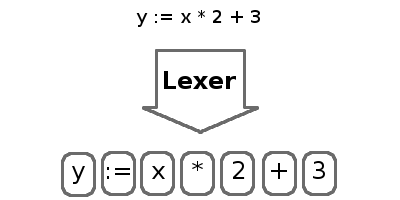
この記事では、レクサーのみに焦点を当てます。 まず、一般的なlexライブラリを作成し、次にIMPのレクサーを作成します。 以下のパートでは、パーサーとエグゼキューターに焦点を当てます。
レクサー
実際、字句演算は非常に単純で、正規表現に基づいています。 それらに慣れていない場合は、 公式ドキュメントを読むことができます 。
字句解析器への入力は、文字の単純なストリームになります。 簡単にするために、入力をメモリに読み込みます。 ただし、出力はトークンのリストになります。 各トークンには、値とラベル(トークンのタイプを識別するタグ)が含まれます。 パーサーはこれを使用してツリー(AST)を構築します。
それでは、正規表現のリストを取得してコードをタグに解析する通常のレクサーを作成しましょう。 式ごとに、入力が現在の位置と一致するかどうかを確認します。 一致が見つかると、対応するテキストが正規表現タグとともにトークンに抽出されます。 正規表現が機能しない場合、テキストは破棄されます。 これにより、コメントやスペースなどを取り除くことができます。 何も一致しない場合は、間違いを報告し、スクリプトがヒーローになります。 このプロセスは、コードストリーム全体を解析するまで繰り返されます。
lexerライブラリのコードは次のとおりです。
import sys import re def lex(characters, token_exprs): pos = 0 tokens = [] while pos < len(characters): match = None for token_expr in token_exprs: pattern, tag = token_expr regex = re.compile(pattern) match = regex.match(characters, pos) if match: text = match.group(0) if tag: token = (text, tag) tokens.append(token) break if not match: sys.stderr.write('Illegal character: %s\n' % characters[pos]) sys.exit(1) else: pos = match.end(0) return tokens
正規表現への転送順序は重要であることに注意してください。 lex関数はすべての式を反復処理し、最初に見つかった一致のみを受け入れます。 つまり、この関数を使用する場合は、まず特定の式(演算子とキーワードに対応)を渡し、次に通常の式(識別子と数字)を渡す必要があります。
レクサーIMP
上記のコードを考えると、言語用のレクサーの作成は非常に簡単になります。 最初に、トークンの一連のタグを定義しましょう。 言語の場合、必要なタグは3つだけです。 予約語または予約語にはRESERVED 、数字にはINT 、 識別子にはID。
import lexer RESERVED = 'RESERVED' INT = 'INT' ID = 'ID'
次に、レクサーで使用されるトークンの式を定義します。 最初の2つの式は、スペースとコメントに対応しています。 タグがないため、レクサーはタグをスキップします。
token_exprs = [ (r'[ \n\t]+', None), (r'#[^\n]*', None),
その後、すべての演算子と予約語が続きます。
(r'\:=', RESERVED), (r'\(', RESERVED), (r'\)', RESERVED), (r';', RESERVED), (r'\+', RESERVED), (r'-', RESERVED), (r'\*', RESERVED), (r'/', RESERVED), (r'<=', RESERVED), (r'<', RESERVED), (r'>=', RESERVED), (r'>', RESERVED), (r'=', RESERVED), (r'!=', RESERVED), (r'and', RESERVED), (r'or', RESERVED), (r'not', RESERVED), (r'if', RESERVED), (r'then', RESERVED), (r'else', RESERVED), (r'while', RESERVED), (r'do', RESERVED), (r'end', RESERVED),
最後に、数値と識別子の式が必要です。 識別子の正規表現は上記のすべての予約語に対応するため、これらの2行が最後に来ることが非常に重要です。
(r'[0-9]+', INT), (r'[A-Za-z][A-Za-z0-9_]*', ID), ]
正規表現が定義されたら、 lex関数のラッパーを作成できます。
def imp_lex(characters): return lexer.lex(characters, token_exprs)
これらの言葉を読んでいただければ、おそらく私たちの奇跡がどのように機能するかに興味を持つでしょう。 テスト用のコードは次のとおりです。
import sys from imp_lexer import * if __name__ == '__main__': filename = sys.argv[1] file = open(filename) characters = file.read() file.close() tokens = imp_lex(characters) for token in tokens: print token
$ python imp.py hello.imp
完全なソースをダウンロード: imp-interpreter.tar.gz
元の記事の著者はJay Conrodです。
UPD:テンプレートが定義されている順序に関連するバグを修正してくれたユーザーzeLarkに感謝します。