
はじめに
教師なしでの機械学習法に関する私の以前の記事では、基本的なSOINNアルゴリズム、つまり自己組織化成長ニューラルネットワークを構築するためのアルゴリズムについて検討しました。 前述のように、SOINNネットワークの基本モデルには、ライフタイムモードでの学習(つまり、ネットワークの全寿命中の学習)に使用できない多くの欠点があります。 これらの欠点には、2層ネットワーク構造が含まれていたため、2層目を完全に再トレーニングするには、ネットワークの最初の層を少し変更する必要があります。 また、このアルゴリズムには多くの構成可能なパラメーターがあり、実際のデータを操作する際に使用が困難でした。
この記事では、拡張自己組織化インクリメンタルニューラルネットワークアルゴリズムについて説明します。これは、基本的なSOINNモデルの拡張であり、発声された問題を部分的に解決します。
SOINNクラスアルゴリズムの一般的な考え方
すべてのSOINNアルゴリズムの主なアイデアは、システムが提供する画像に基づいて確率的データモデルを構築することです。 学習プロセスでは、SOINNクラスのアルゴリズムがグラフを作成します。各頂点は確率密度の極大値の領域にあり、エッジは同じクラスに属する頂点を接続します。 このアプローチの意味は、クラスが空間内で高い確率密度の領域を形成すると仮定することであり、そのような領域とそれらの相対位置を最も正確に記述するグラフを構築しようとしています。 この考えは次のように最もよく説明できます。
1)着信入力データの場合、頂点が確率密度の極大値の領域に収まるようにグラフが構築されます。 したがって、各頂点で、対応する空間領域での入力データの分布を記述する関数を作成できるグラフを取得します。

2)グラフ全体は分布の混合物であり、これを分析することで、ソースデータ内のクラスの数、それらの空間分布、およびその他の特性を判断できます。

ESOINNアルゴリズム
それでは、ESOINNアルゴリズムに移りましょう。 前述したように、ESOINNアルゴリズムは、成長する自己組織化ニューラルネットワークの基本的な学習アルゴリズムの派生物です。 基本的なSOINNアルゴリズムのように、問題のアルゴリズムは、教師なしで、そして学習の最終目標なしで、オンライン(そして生涯)学習を目的としています。 ESOINNと前述のアルゴリズムの主な違いは、ネットワーク構造が単層であり、その結果、構成可能なパラメーターが少なくなり、アルゴリズム全体の操作中に学習の柔軟性が向上することです。 また、勝者ノードが常にエッジで接続されているコアネットワークとは異なり、高度なアルゴリズムでは、勝者ノードが属するクラスの相互配置を考慮して、接続を作成する条件が現れました。 このようなルールを追加することにより、アルゴリズムは近接クラスと部分的に重複するクラスを正常に分離できました。 したがって、ESOINNアルゴリズムは、基本的なSOINNアルゴリズムで特定された問題を解決しようとします。
次に、ESOINNネットワーク構築アルゴリズムを詳細に検討します。
フローチャート

アルゴリズムの説明
使用される表記
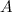 -グラフノードのセット。
-グラフノードのセット。
 -グラフのエッジのセット。
-グラフのエッジのセット。
 -のノード数 。
-のノード数 。
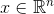 -アルゴリズムの入力に送信されるオブジェクトの特徴のベクトル。
-アルゴリズムの入力に送信されるオブジェクトの特徴のベクトル。
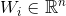 グラフのi番目の頂点の符号のベクトルです。
グラフのi番目の頂点の符号のベクトルです。
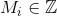 -グラフのi番目の頂点の累積信号数。
-グラフのi番目の頂点の累積信号数。
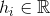 グラフのi番目の頂点の密度です。
グラフのi番目の頂点の密度です。
アルゴリズム
- ノードのセットを初期化する 許容値の範囲からランダムに取得された特徴ベクトルを持つ2つのノード。
関係セットの初期化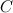 空のセット。
空のセット。
- 入力オブジェクトの入力特徴ベクトルを送信する 。
- 最も近いノードを見つける
 (勝者)および2番目に近いノード
(勝者)および2番目に近いノード  (2番目の勝者)、として:
(2番目の勝者)、として:
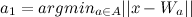
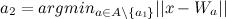
- 入力オブジェクトの特徴ベクトルと または 特定のしきい値よりも大きい
 または
または 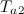 、それから新しいノードを生成します(新しいノードを追加します 手順2に進みます。
、それから新しいノードを生成します(新しいノードを追加します 手順2に進みます。
そして 式によって計算されます:
 (頂点に隣接がある場合)
(頂点に隣接がある場合)
 (頂点に近傍がない場合)
(頂点に近傍がない場合)
- すべてのエッジの年齢を増やします 1。
- アルゴリズム2を使用して、 そして :
- 必要な場合:リブ
 存在し、彼の年齢をゼロにし、そうでなければエッジを作成します 年齢を0に設定します。
存在し、彼の年齢をゼロにし、そうでなければエッジを作成します 年齢を0に設定します。
- これが不要な場合:エッジが存在する場合は削除します。
- 必要な場合:リブ
- 次の式に従って、勝者が蓄積する信号の数を増やします。
 。
。
- 式で勝者密度を更新します。
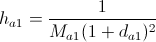 どこで
どこで 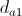 -勝者が属するクラスター内のノード間の平均距離。 次の式で計算されます。
-勝者が属するクラスター内のノード間の平均距離。 次の式で計算されます。 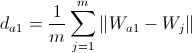 。
。
- 勝者とそのトポロジカルネイバーの特性ベクトルを重み係数で適応させる
 そして
そして 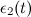 式に従って:
式に従って:
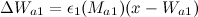
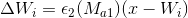
基本的なSOINNアルゴリズムと同じ適応スキームを適用します:


- 年齢が特定のしきい値を超えるrib骨を見つけて削除します
 。
。
- これまでに生成された入力信号の数がいくつかのパラメーターの倍数である場合
 その後:
その後:
- アルゴリズム1を使用して、すべてのノードのクラスラベルを更新します。
- 次のようにノイズのあるノードを削除します。
- すべてのノード
 から
から  :ノードに2つの隣接ノードがあり、
:ノードに2つの隣接ノードがあり、 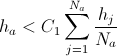 次に、このノードを削除します。
次に、このノードを削除します。
- すべてのノード から :ノードに1つの隣接ノードがあり、
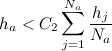 次に、このノードを削除します。
次に、このノードを削除します。
- すべてのノード から :ノードに隣接ノードがない場合は、削除します。
- すべてのノード
- アルゴリズム1を使用して、すべてのノードのクラスラベルを更新します。
- 学習プロセスが完了したら、さまざまなクラスのノードを分類し(グラフの関連コンポーネントを抽出するアルゴリズムを使用)、クラス数、各クラスのプロトタイプベクトルを報告し、学習プロセスを停止します。
- 学習プロセスがまだ完了していない場合は、ステップ2に進み、教師なしで学習を続けます。
アルゴリズム1:複合クラスのサブクラスへの分割
- 近傍に最大密度がある場合、ノードはクラスの頂点であると言います。 複合クラスでそのような頂点をすべて見つけ、さまざまなラベルを割り当てます。
- 残りの頂点を、対応する頂点と同じクラスに割り当てます。
- ノードが異なるクラスに属し、共通のエッジを持つ場合、ノードは重複するクラスの領域にあります。
実際には、クラスをサブクラスに分割するこの方法は、ノイズの存在下で大きなクラスをいくつかの小さなクラスとして誤って分類できるという事実につながります。 したがって、クラスを分離する前に、それらをスムーズにする必要があります。
平滑化されていない2つのクラスがあるとします。
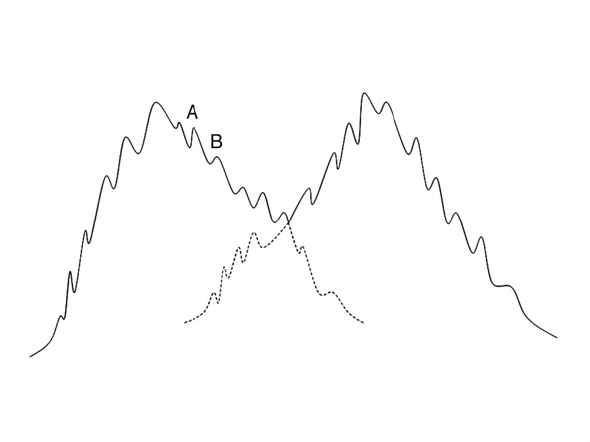
サブクラスを取る
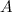 およびサブクラス
およびサブクラス 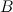 。 サブクラスの頂点の密度が 等しい
。 サブクラスの頂点の密度が 等しい  、およびサブクラス 等しい
、およびサブクラス 等しい 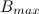 。 団結 そして 次の条件に該当する場合、1つのサブクラスになります。
。 団結 そして 次の条件に該当する場合、1つのサブクラスになります。
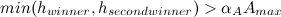
または

ここで、1番目と2番目の勝者は、サブクラスが重複する領域にあります
そして 。 パラメータ  次のように計算されます。
次のように計算されます。
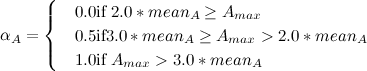 どこで
どこで  -サブクラスのノードの平均密度 。
-サブクラスのノードの平均密度 。
その後、さまざまなクラスの頂点を接続するすべてのエッジを削除します。 したがって、複合クラスをオーバーラップしないサブクラスに分割します。
アルゴリズム2:頂点間の関係の構築
次の場合、2つのノードを接続します。
- 少なくとも1つは新しいノードです(どのサブクラスに属しているかはまだ判別されていません)。
- それらは同じクラスに属します。
- これらは異なるクラスに属し、これらのクラスをマージするための条件が満たされます( アルゴリズム1の条件)。
それ以外の場合、これらのノードは接続せず、それらの間に接続がある場合は削除します。
ノード間にエッジを作成する必要性を確認する際にアルゴリズム1を使用することにより、ESOINNアルゴリズムは、クラスの過度の分離と異なるクラスの1つの組み合わせの「バランス」を見つけようとします。 このプロパティにより、近接したクラスのクラスタリングが成功します。
アルゴリズムの議論
上記のアルゴリズムを使用して、最初に入力信号に最も近い特徴ベクトルを持つ頂点のペアを見つけます。 次に、入力信号が既知のクラスの1つに属するか、それが新しいクラスの代表であるかを決定します。 この質問に対する答えに応じて、ネットワークに新しいクラスを作成するか、入力信号に対応する既知のクラスを調整します。 学習プロセスがかなり前から続いている場合、ネットワークはその構造を調整し、異なるサブクラスを分離し、類似するサブクラスを組み合わせます。 トレーニングが完了したら、すべてのノードを異なるクラスに分類します。
ご覧のとおり、作業の過程で、ネットワークは以前に学習したことをすべて忘れずに、新しい情報を学習できます。 この特性により、安定性と可塑性のジレンマをある程度解決でき、ESOINNネットワークを生涯トレーニングに適したものにします。
実験
提示されたアルゴリズムで実験を行うために、Boost Graph Libraryを使用してC ++で実装されました。 コードはGitHubに投稿されています 。
実験のためのプラットフォームとして、サイトkaggle.comで、MNISTに基づいて手書きの数字を分類するコンテストが開催されました。 トレーニングデータには、サイズ28x28ピクセルで256階調の手書きの数字が48,000個含まれ、784次元ベクトルの形式で表示されます。
非定常環境で分類結果を取得しました(つまり、テストサンプルの分類中、ネットワークは学習を続けました)。
ネットワークパラメータは次のように取得されました。
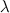 = 200
= 200
 = 50
= 50
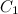 = 0.0001
= 0.0001
 = 1.0
= 1.0
作業の結果、ネットワークは次のような中心を持つ14のクラスターを特定しました。

執筆時点で、ESOINNは、テストサンプルの25%で0.96786の精度でランキングの191位を占めました。これは、入力データに関する先験的な情報を最初に持たないアルゴリズムにとってそれほど悪くはありません。

おわりに
この記事では、ESOINN成長ニューラルネットワークの修正学習アルゴリズムについて検討しました。 基本的なSOINNアルゴリズムとは異なり、ESOINNアルゴリズムには1つのレイヤーのみがあり、生涯トレーニングに使用できます。 また、ESOINNアルゴリズムを使用すると、アルゴリズムの基本バージョンではできなかった、部分的に重複したファジークラスを操作できます。 アルゴリズムパラメータの数が半分になりました。これにより、実際のデータを操作するときにネットワークを簡単に構成できます。 この実験では、検討したアルゴリズムのパフォーマンスが示されました。
文学
- 「オンライン教師なし学習のための強化された自己組織化インクリメンタルニューラルネットワーク」シェンフラオア、小倉友孝、長谷川修、2007年 。
- 東京工業大学IITボンベイの長谷川修氏による、SOINNに関する講演。
- 東京工業大学IITボンベイの長谷川修氏による、SOINNに関する講演(ビデオ)。
- 成長するニューラルネットワークを自己組織化するための研究所である長谷川研究室のサイト。