講義は 、高校生-Small ShADの生徒向けに設計されていますが、大人はそれを使用していくつかのギャップを埋めることができます。
http://video.yandex.ru/users/e1coyot/view/4/
テキストからオブジェクトとファクトを抽出することは、NLP(自然言語処理)の一部です。 最終的な目標は、通常の人間のテキストを完全に理解するように機械に教えることです。 そして、この目標に向かって動き始めたばかりです。
現在、NLPはいくつかの目的に適用されています。
- テキスト検索
- 事実の抽出
- 対話システムと質問応答
- 音声合成と認識
- センチメントレビューの評価
- テキストのクラスタリングと分類。
非構造化テキストから構造化情報を抽出することをテキストマイニングと呼びます。 このプロセスの主要部分は、オブジェクトの定義、テストにおけるそれらの関係とプロパティに専念します。 テキストマイニングは、いくつかの主要なタスクに分割できます。
- 名前付きエンティティ認識(NER)-名前付きエンティティ/オブジェクトの抽出;
- 相互参照の解決-相互参照の解決。
- 情報抽出(IE)-ファクト抽出。
それでは、まず最初に、テキスト内の名前付きエンティティにマークを付けましょう。 この例では、会社名は赤で強調表示され、人は緑で強調表示されています。 この選択は、アルゴリズムの目的の動作に対応します。 その後、相互参照の解決に進むことができます。

電話会議は、テキスト内のいくつかの異なる参照を1つの実際のオブジェクトにリンクする試みです。

相互参照の1つの例は、照応-特別なポインターを使用したオブジェクトへの参照です。 私たちの場合、これらは代名詞です。
相互参照の2番目の例は同義語です。 さまざまな方法で表現できます。
- 文字変換:Yandex-Yandex。
- 略語:VTB-Vneshtorgbank-対外貿易銀行。
- 同義語:病院-病院。
- 単語形成:モスクワ-モスクワ。
- グラフィック:自動車ローン-自動車ローン。
テキストを分析するときは、実際のオブジェクトに関連付けられていない不要な事実やエンティティを抽出しないように、相互参照を考慮する必要があります。
ファクトは、列にオブジェクトとそれらの間の関係が含まれる表の行として表すことができます。 事実発見プロセスの結果は次のようになります。

通常、IEを使用して次の種類のオブジェクトを抽出します:日付、住所、電話番号、氏名、商品名、会社など。 有用な事実は、ほとんどの場合、イベント、意見、レビュー、連絡先の詳細、発表です。
一次テキスト処理
そのため、入り口には自然言語のテキストがあります。 すべての言語レベルで一度に分析する必要があります。
- グラフェマティック。
- 字句
- 形態学的
- 構文
- 意味論
テキストは、段落、文、単語に分かれています。 その後、単語normalize-最初のフォームが強調表示されます。 次に、完全または部分的な解析が実行され、文中の単語間の依存関係と関係が決定されます。
一見すると、テキストを文章に分割することは難しくないようです。 文の終わりを示す句読点に焦点を合わせる必要があります。 しかし、この方法は常に機能するとは限りません。 実際、たとえば、ドットは、小数またはURLで使用される略語を示すこともできます。 句読点は、会社名またはサービス名で使用できます。 たとえば、Yahoo! またはYandex.Market。
初期フォームの選択もそれほど簡単ではありません。 もちろん、ほとんどの場合、形態学的辞書を使用して取得できます。 しかし、これは常に適用できるものではありません。 たとえば、単語「glass」の辞書形式を決定する方法は? 名詞または動詞のいずれかです。 そして、形態学的辞書に目を向ける前に、同音異義語を削除する必要があります。 これは、すべての単語が品詞でマークアウトされ、同音異義語が削除される言語のコーパスの助けを借りて解決されます。 したがって、コーパス内の単語の使用に関するコンテキストと統計に基づいて、この単語またはその単語が音声のどの部分を指しているかを判断することができます。
次のステップは、完全解析または部分解析です。 文内の単語間の依存関係と関係のグラフが作成されます。 パーサーを使用して構築できる構文ツリーの例を次に示します。
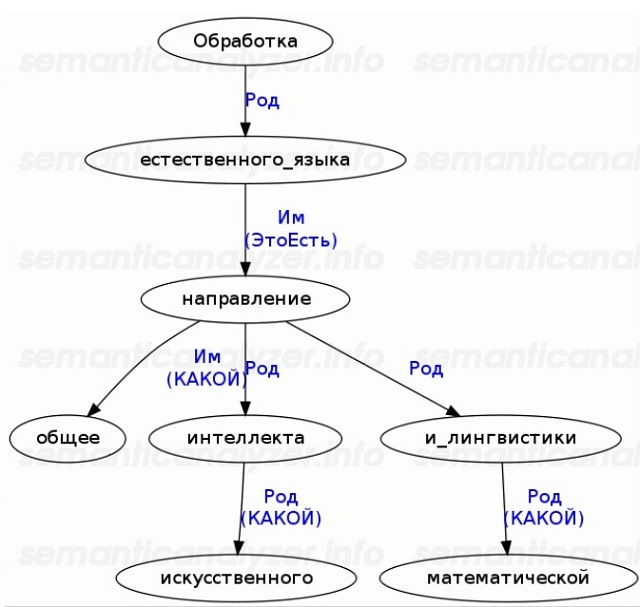
どんな条件下でもエラーなしで完全な構文グラフを構築できるアルゴリズムは存在しません。 ただし、ほとんどのテキストマイニングアプリケーションでは、部分的な分析で十分です。
上記で説明した形態学的同音異義語に加えて、構文上の「対象」同音異義語もあります。 構文的な同音異義語の例として、「彼は自分の目で見た」という例を挙げます。 両方の読書オプションは構文的に正しいでしょう:誰かが自分の目で誰かの家族を見た、または誰かが7つ目の誰かを見ました。 このような問題を解決するには、すでにセマンティック分析を行う必要があります。
「客観的」同音異義語は、2つの異なる実際のオブジェクトが同じ名前を持つことができることを意味します。 たとえば、ロシアには、ミハイル・ザドルノフという有名な2人の有名人がいます。コメディアンと元財務大臣です。 これらの人々を区別するようにシステムに教えない場合、それらについての事実を抽出しようとすると、さまざまなインシデントが発生する可能性があります。
事実の抽出
これらのすべての手順が完了したら、ファクトの抽出に直接進むことができます。 特別なアルゴリズムを使用して、必要なすべてのオブジェクトとファクトをマークアウトして分類する非構造化パッセージからテキストを取得します。 これは次のように視覚化できます。

従来、事実を抽出する際に使用される主なアプローチは3つあります。
- オントロジー;
- ルールに基づく(ルールベース);
- 機械学習(ML)に基づいています。
私たちの場合、オントロジーは「概念辞書」であり、概念やオブジェクト、それらの間の関係、およびそれらの特性を記述する構造です。
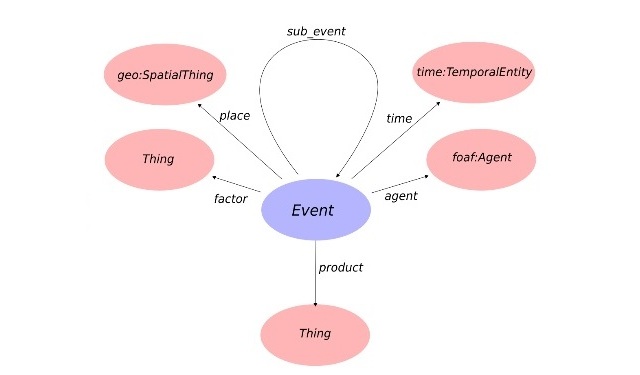
オントロジーは、普遍的(可能な限り幅広いオブジェクトのセットを記述しようとする)、産業(主題分野に関する情報を含む)、および高度に専門化された(特定の問題を解決するために設計された)ものです。 オブジェクト(知識ベース)のオントロジーも適用できます。 ナレッジベースの最も顕著な例は、Wikipediaです。
したがって、特定のオントロジーがあります。 コンテキストと既存のオブジェクトのリストに基づいて、テキスト内のオブジェクトと事実に関連して仮説を構築し、これらの仮説を検証または拒否できます。 左側には、オブジェクトを色でマークしたテキストがあります。これについて、いくつかの情報を抽出します。 オントロジーとして、ウィキペディアが適用されます。 そこのテキストからすべてのキーワードのリクエストを送信することにより、右側にある記事のリストを取得します。 その中の赤は、一度にいくつかのオブジェクトに関連するマークされた記事です。

ここでの目標は、誤った仮説を切り捨てることです。 これを行うには多くの方法があります。 最も一般的に使用されるのは、機械学習、さまざまな文脈的および構文的要因です。
オントロジーを使用して情報を抽出すると、NERのかなり高い精度を得ることができ、ランダムな応答がなくなります。 同音異義語の削除も高精度で行われます。 このアプローチの欠点は、完全性が低いことです。これは、オントロジーにすでに存在するもののみを抽出できるためです。 オントロジーでは、オブジェクトを手動で追加するか、自動追加の手順を作成する必要があります。
別のアプローチ-機械学習-は多くの入力を必要とします。 テキストのトレーニングサンプルをできるだけ言語情報でカバーする必要があります。すべての形態、構文、セマンティクス、オントロジー接続をマークします。 このアプローチの利点は、ラベル付きケースの作成に加えて、手作業を必要としないことです。 ルールやオントロジーを作成する必要はありません。 必要に応じて、このようなシステムは簡単に再構成および再トレーニングできます。 ルールはより抽象的です。 ただし、欠点もあります。 ロシア語のテキストの自動マークアップ用のツールはまだあまり開発されておらず、既存のテキストに簡単にアクセスできるとは限りません。 エンクロージャーは十分にボリュームがあり、正しく、均一かつ完全にマークされている必要があります。 そして、これはかなり面倒なプロセスです。 さらに、何か問題が発生した場合、エラーが発生した場所を正確に追跡し、それを個別に修正することは困難です。
3番目のアプローチは、ルールベースのアプローチです。 手動でパターンを書く。 アナリストは、抽出する必要がある情報の種類の説明を作成します。 このアプローチは、分析の結果にエラーが見つかった場合、その原因を見つけてルールに必要な変更を加えるのが非常に簡単であるという点で便利です。 比較的標準化されたオブジェクトのルールを作成する最も簡単な方法:名前、日付、会社名など。
最適なアプローチの選択は、特定のタスクによって決定されます。 現在、オントロジーと機械学習が最も頻繁に使用されていますが、将来はハイブリッドシステムにあります。
Yandexでは、NERを使用して、メール内のファクト、地理オブジェクトの名前、クエリからの名前、空席のファクトの抽出、およびニュースのクラスタリングと分類に使用されます。