名前自体の歴史から始めましょう。
それで、それはどのように始まりましたか。 1994年以来、MITはCilk言語を開発しました。これにより、タスクに並行性を簡単に実装できました。 さらに、ソースコードからすべてのCilkキーワードを削除することにより、「syshch」コンパイラーによって完全に正確で簡単にコンパイルされるコードになったため、C言語の拡張機能でした。 当然のことながら、Cilk ++と呼ばれる商用バージョンのCilkが登場しました。 次に、すでにC ++をサポートし、gccおよびMicrosoftコンパイラーとも互換性がありました。また、商業組織Cilk Arts、Inc.はすでに開発に従事していました。 これは、インテルがCilk Arts、Cilk ++テクノロジーをCilk商標で購入した場所です。 私自身が2008年にIntelで働き始めたことは注目に値します。コンパイラーでのCilkの開発のすべての段階を覚えています。 そのため、まもなく2010年に、Intel Cilk Plusと呼ばれる最初の商用バージョンがリリースされました。これは、Intel C ++コンパイラの一部です。 なぜPlusですか? はい。実際、インテルCilk Plusの半分だけがCilk ++テクノロジーからのものであり、タスクの並列処理を導入できました。 後半は、データに並列処理を実装し、コードをベクトル化するのに役立つ部分です。 概略的には、次のようになります。
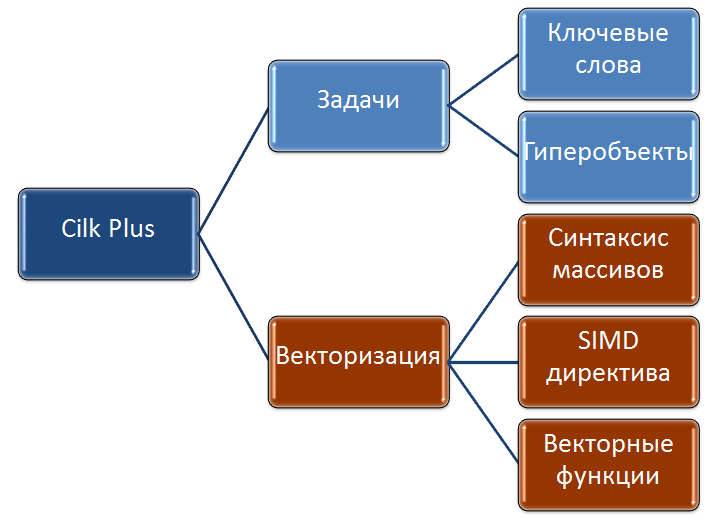
今、あなたはそのような長い名前の「秘密」を知っています、そして、プラスの秘密の意味は、ベクトル化に責任がある部分です。 マーケティング担当者が「1つの屋根」の下で2つの異なる技術を試し、組み合わせたことは明らかです。 ちなみに、新しいOpenMPに移行したのはベクター部分であり、それについては、以前の投稿ですでに部分的に話していました。
ここで、Cilk自体について詳しく説明します。 ところで、この質問は非常に修辞的であり、開発者にとってはどの部分がより重要で重要です。 最大のパフォーマンスを得るには、すべてのタイプの並行性を使用する必要があるため、すべてが非常に役立ちます。 個人的な経験から、私はベクトル化の部分をより頻繁に使用し、より大きな利益を得ています。 もちろん、これはCilkのタスクが悪いという事実によるものではなく、OpenMPを使用してタスクを並列化することがより頻繁に見られます。 Silkovskayaの実装は優れていますが。
アイデアはシンプルです。新しいキーワードの最小数は3個で、最大の戻り値はcilk_spawn、cilk_sync、cilk_forです。 内部には、負荷を分散するために作業をキャプチャする、軽量で効率的な最新のタスクスケジューラがあります。 しかし、まず最初に。
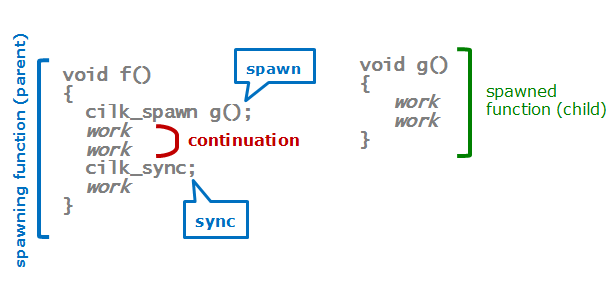
別の関数g()が呼び出され、作業が実行される(要約すると)関数のスケルトンを見ると、シリアルバージョンでは次のようになります。
void f() { g(); work work } void g() { work work }
ここで、「手首を軽く振る」ことで、コードを並列に変換します。
void f() { cilk_spawn g(); work work cilk_sync; work }
ここで何が起こっていますか? g()関数の可能な並列実行のためのタスク(タスク)と、行cilk_sync(Cilk'a-継続に関して)までf()関数に残っていた作業を作成します。 ちょっとした用語:
スレッドを作成せず、どのスレッドでどのコードを実行するかを言わないことが重要です。 すべての作業はタスクに基づいているため、負荷を効果的に分散し、同時実行性を保証できます。 どうやって? とても簡単です。
スレッドのプールがありますが、単純な例として、スレッドが2つしかない場合、各スレッドには実行するタスクのキューがあります。 不均衡がある場合、つまり、1つのスレッドが仕事で忙しく、他のスレッドが仕事をしていない場合、タスクは他のスレッドのキューからキャプチャされます。
さらに、この例では、領域の継続がキャプチャされます。 このようなもの:
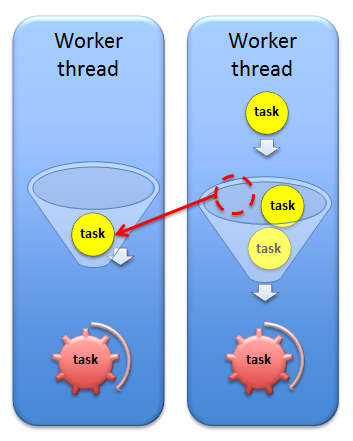
したがって、すべてのコアに作業がロードされることを保証します。 ところで、同じスケジューラーがIntel Threading Building Blocks(TBB)に実装されています。 cilk_syncは同期ポイントです。
cilk_for構造は、Captain Evidenceが言うように、forループに並行性を導入することを目的としています。 なぜ別の設計が必要なのですか? 私は直接答えはしませんが、示唆的な例を挙げます。 これら2つのサイクルの違いは何ですか?
for (int x = 0; x < n; ++x) { cilk_spawn f(x); } cilk_for (int x = 0; x < n; ++x) { f(x); }
最初のケースでは、各反復でタスクを作成します。他の誰かのタスクをキャプチャする操作は、パフォーマンスの点で非常にコストがかかります。 各反復で「小さな」作業がある場合、そのような「並列」プログラムの助けを借りて得られる以上の損失が生じます。
明らかに、スポーンは各反復で行う必要はなく、たとえば1回だけ行う必要があり、他のすべての反復は継続として認識される必要があります。 cilk_forの必要性についての質問に対する答えは、今は消えると思います。
実際、ほとんどすべて。 共有メモリアクセスの問題を解決するために残ります。 減速機の助けを借りて、これを自分で処理する必要があります。 共有データはCilkのテンプレートを使用して作成され、それらとの安全な作業を保証します。
簡単な例を続けましょう。
int sum=3; void f() { cilk_spawn g(); work sum += 2; work } void g() { work sum++; work }
一般的な変数の合計で「悪い」状況が発生することは明らかです。 それを解決するには、次のように宣言する必要があります。
cilk::reducer_opadd<int> sum(3);
また、cilk :: monoid_baseおよびcilk :: reducerクラスを継承して、独自のレデューサーを作成できます。 ところで、これはOpenMPの最新バージョンで可能になりました。
Intel Cilk Plusが何を持っているかを十分に理解できたことを願っています。 実際、Cilkのキーワードを使用したタスクの並列処理、ディレクティブと新しい構文を使用したデータの並列処理(これについてはまだ意図的に説明していません)-ほとんどすべてがあります。 ご覧のとおり、このテクノロジは強力であり、アプリケーションであらゆる種類の同時実行性を使用する大きな可能性を提供します。 それのために行き、「フォースがあなたと一緒にいるように」!