免責事項
最初に、材料が登場したのは、私が
null
分析とは何か、それがどれほど優れているか、なぜ企業の怠inessを今すぐ克服してプロジェクトでこの分析を使用する必要があるのかをすばやく説明したかったためです IDEを参照せずに主題に関する完全な体系化された情報を含む記事はなかったので、私は自分でそれを書かなければなりませんでした。 そして、完全な体系化の結果としてはうまくいきませんでしたが、私はまだ素材をより多くの聴衆と共有したいと思っていました。 最小限のテキストと多くの画像があります。
第二に、リソースにはすでにIntelliJ IDEAに捧げられた素晴らしい記事 tr1cksがあり、 IDEAは非常に良い、Eclipseは貧しい人のためのすでに強い印象を補強しています(これは言い換えになります)。 バランスを取るために、Eclipseに焦点を当てます。
FindBugsプロジェクトアノテーション( JSR 305アノテーションとも呼ばれます)を使用するのは、特定の開発環境へのバインディングがないためです(ファンは
org.eclipse.jdt.annotation.*
を使用できます
org.eclipse.jdt.annotation.*
および
org.jetbrains.annotations.*
) Maven Centralで利用できるという事実によります 。 Mavenを使用している場合は、次を
<dependencies/>
セクションに追加するだけです。
<dependency> <groupId>com.google.code.findbugs</groupId> <artifactId>jsr305</artifactId> <version>3.0.0</version> </dependency>
念のため、予約をします
@Nonnull public String getName() { // ... }
そして
public @Nonnull String getName() { // ... }
-これらは完全に同等の2つの構造ですが、場合によっては、取得したバイトコードの2つのバリアントが正確に1バイト異なる可能性があります(ところで、なぜだと思いますか?)
日食
以下はすべてEclipse 4.4(Luna)でテスト済みです。 同時に、もし私の記憶が私に役立っているなら、説明された機能はすでに3.8(そしておそらくそれ以前)に存在していました。
カスタマイズ
- M2Eclipseモジュールを使用すると、注釈がすぐに追加されます。

- 次に、グローバル設定またはプロジェクト設定に入り、 Java- > コンパイラ -> エラー/警告 -> Null分析を選択し、 注釈ベースのNULL分析を有効にするを有効にする必要があります 。

- その後、Eclipseは、 Nullポインターアクセスと潜在的なnullポインターアクセスの問題のレベルが「エラー」に引き上げられるかどうかを尋ねます 。 同意すると、既存のコードに対して多くのコンパイルエラーが発生することに留意する必要があります。したがって、これは新しいプロジェクトに対してのみ行うことをお勧めします。それ以外の場合は「警告」レベルのままにします。
- これで、null仕様にデフォルトのアノテーションを使用フラグをクリアし、ファクトリーアノテーションの代わりにJSR 305アノテーションを選択できます。

- [ フィールドの構文null解析を有効にする]フラグを選択する必要があります。この場合、誤検出の数(および検出される数)は減少します。
- パッケージフラグの'@NonNullByDefault'アノテーションの欠落も選択する価値があります (このフラグの存在はEclipseとIDEAを比較します)が、
@NonNullByDefault
または@ParametersAreNonnullByDefault
助けを借りて、新しく作成されたパッケージ(既に記述された大量のコード、内臓JDK、cornyは「非ゼロパラメーター」の要件を満たしていないため、コンパイルエラーが発生します。 念のため、パッケージ全体(「package-info.java」ファイル内)の注釈は、次のように「ハング」しています。
@ParametersAreNonnullByDefault package com.example; import javax.annotation.ParametersAreNonnullByDefault;
偽陽性の診断
診断が間違っていると幸せになる人はほとんどいません。 幸いなことに、「医師、あなたは酔って、他の誰かの血を分析しました!」と言う機会があります。
問題
この写真は、Eclipseが(もちろん、シングルスレッドのシナリオでは)
hashCode()
呼び出しの時点でフィールド
field
を
null
にできないことを判断できないことを示しています。
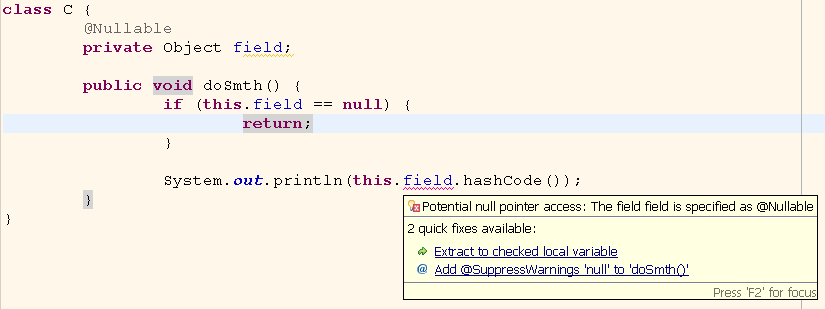
はい、もちろん、メソッド全体を
@SuppressWarnings("null")
でマークでき
@SuppressWarnings("null")
が、これはnull分析のすべての利点を無効にします。
回避策0
assert
追加:

回避策1
長いですが、可能です。 フィールド値をローカル変数にプルし、
@Nonnull
としてマークしてから作業します。

落とし穴
Java 1.8以降では、新しいタイプのメタデータ( タイプアノテーション ( JSR 308を参照))がサポートされているため、
@Target
を明示的に指定するにはアノテーションが必要です。 FindBugsアノテーションはこの要件を満たしていません。 したがって、最大4.4 (Luna)およびJava 1.8を含むEclipseを使用する場合、FindBugs注釈を使用した
null
分析は機能しません(
ホームリーディング
アイデア
IntelliJ IDEAは、時間の初めから
null
分析をサポートしているようです( Constant条件と例外と@ NotNull / @Nullable問題をチェックする )。
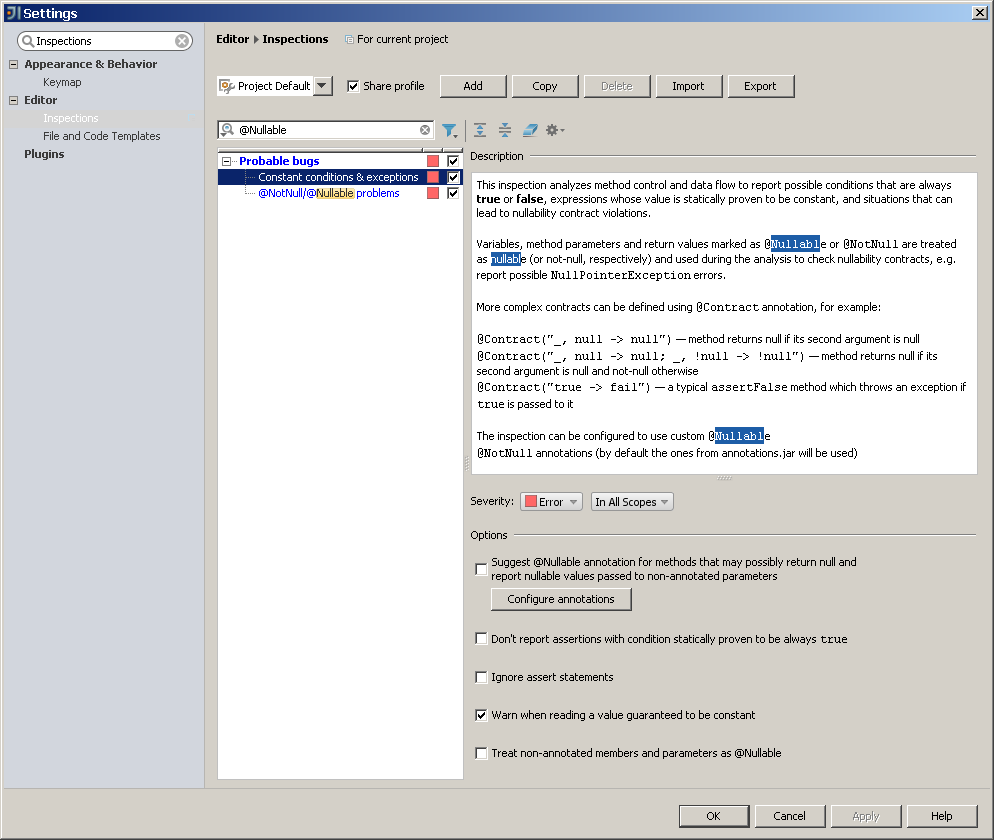
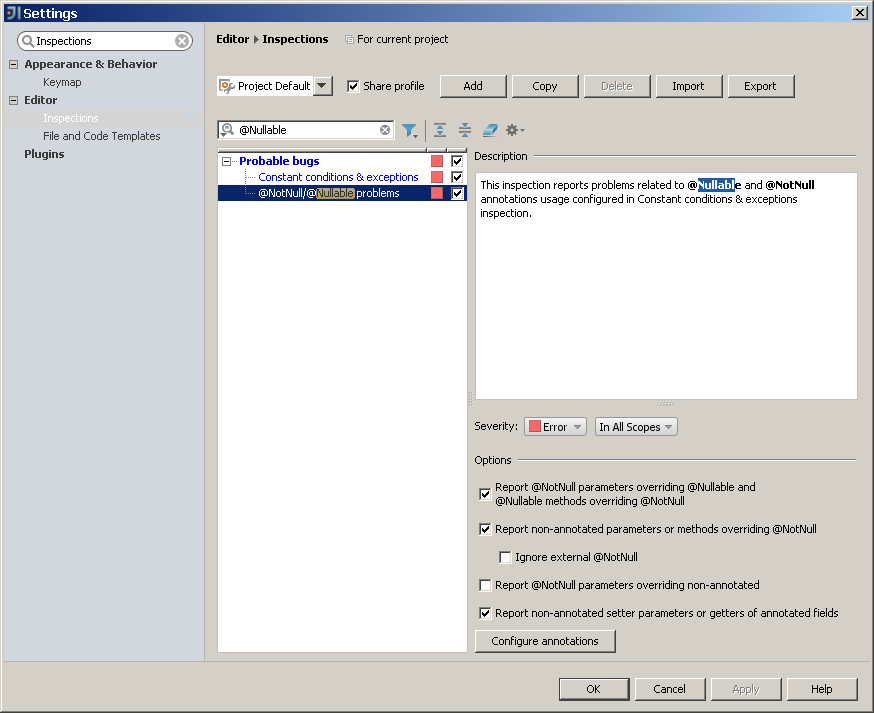
すばらしいのは、JSR 305を含む多くの適切な注釈が「すぐに使える」環境ですぐにわかることです。
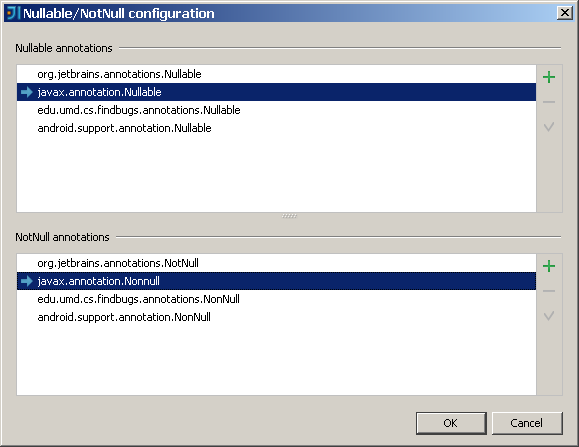
唯一の残念な点は、Eclipseとは異なり、パッケージ全体の注釈(
@NonNullByDefault
や
@ParametersAreNonnullByDefault
)がサポートされていないことです。
更新する
アセンブリ138.1372(
@ParametersAreNonnullByDefault
および
@ParametersAreNullableByDefault
が認識および分析されますが、設定には表示されません( Borzのおかげです )。 さらに、機能はIDEA 13.1.6(ビルド135.1306)に存在するようです。
Netbeans
NetBeansは7.3以降、
null
分析をサポートしてい
null
。次を参照してください。 英語の 記事 。
備考
IDEだけでなくFindBugsも使用する場合、
null
を返す可能性のあるメソッドは
@Nullable
としてマークするだけでなく、
@Nullable
としてマークする必要があります
@CheckForNull
は
@CheckForNull
場合にのみ「落ち着きます」。
素敵なボーナス nishtyaki副作用
これは、このトピックからの叙情的な余談ですが、分析の導入がProject Xにもたらした当面の利点について説明しています。より正確には、単体テストの落とし穴を特定するのに役立ちました。
むかしむかし、落ちないが、あまり巧妙に書かれていないテストがありました。 はい、あなたは間違っていませんでした。これはJUnit 3です。
public void test() throws Exception { final Calendar calendar = myVeryCleverNonStandardApiCall(); final int year = calendar.get(Calendar.YEAR); assertEquals(1997, year); assertEquals("1.1", System.getProperty("java.specification.version")); }
わずか数年が経過し、テストが失敗したことがわかりました。 つまり、まだコンパイルされますが、動作しなくなります。 鼻の蚊が変色しないように、テストは「修正」されました。 要するに、誰も何も気づきませんでした:
public void test() throws Exception { final Calendar calendar = myVeryCleverNonStandardApiCall(); final int year = calendar.get(Calendar.YEAR); // assertEquals(1997, year); // assertEquals("1.1", System.getProperty("java.specification.version")); }
数年後、コンパイルも停止し、適切な統計が必要でした。 テストは再び修復されました。 NPEを取り除くことは不可能であり、大量のコードをスローすることが注目を集めるため、古いテストは偽装され、目を回避するために2番目の遅延を伴う新しいテストが導入されました。
public void test() throws Exception { Thread.sleep(1000); } public void _test() throws Exception { final Calendar calendar = null; //myVeryCleverNonStandardApiCall(); final int year = calendar.get(Calendar.YEAR); // assertEquals(1997, year); // assertEquals("1.1", System.getProperty("java.specification.version")); }
結論は?
レガシーコードの場合でも、 Nullポインターアクセスと潜在的なNULLポインターアクセスのレベルを「エラー」に上げることが理にかなっている場合があります。 特にレガシーコードの場合。 20年前に文字通りゼロから製品を作成し、 10年前に一部のGoogleやAmazonに成功した「バイソン」の能力を想像することさえできません。
願い
読者の中にC#を使用している人がいる場合、コメントしてください-Nullableなどの素晴らしいものの存在に照らしてC#に関連する問題はありますか?そうであれば、どのように解決されますか?