はじめに
こんにちは、読者の皆様。
最近、グローバルウェブの広がりをさまようと、今年初めにTCS銀行が開催したトーナメントに出会いました。 タスクをレビューした後、タスクに関するデータを分析するスキルをテストすることにしました。
スコアリングの問題(タスク番号3)で検証を開始することにしました。 それを解決するために、私はいつものように、Pythonとpandasおよびscikit-learn分析モジュールを使用しました。
データの説明と問題の説明
銀行は、ロシアの3大信用調査機関に申請者の信用履歴を要求します。 銀行の顧客の選択は、 SAMPLE_CUSTOMERS.CSVファイルで提供されます。 サンプルは、「トレーニング」と「テスト」の部分に分かれています。 「train」サンプルから、不良ターゲット変数の値がわかっています-「default」の存在(クライアントは、ローンを使用した最初の年の間に90日以上の遅延を想定しています)。 ファイルSAMPLE_ACCOUNTS.CSVは、関連する顧客に対するすべてのリクエストに対する信用調査機関の応答からのデータを提供します。
SAMPLE_CUSTOMERSデータ形式 -特定の個人のデフォルトの可能性に関する情報。
SAMPLE_ACCOUNTSデータセット形式の説明:
セットの説明
| お名前 | 説明 |
|---|---|
| TCS_CUSTOMER_ID | 顧客ID |
| BUREAU_CD | 請求書の受領元の局のコード |
| BKI_REQUEST_DATE | 局に要求が行われた日付 |
| 通貨 | 契約通貨(ISO通貨文字コード) |
| 関係 | 契約との関係のタイプ |
| 1-個人 | |
| 2-追加カード/許可ユーザー | |
| 4-ジョイント | |
| 5-保証人 | |
| 9-法人 | |
| OPEN_DATE | 契約開始日 |
| FINAL_PMT_DATE | 最終支払い日(予定) |
| 種類 | 契約タイプコード |
| 1-自動車ローン | |
| 4-リース | |
| 6-住宅ローン | |
| 7-クレジットカード | |
| 9-消費者ローン | |
| 10-ビジネス開発クレジット | |
| 11-運転資金の補充のためのローン | |
| 12-機器の購入のためのローン | |
| 13-不動産建設ローン | |
| 14-株式の購入に対するクレジット(たとえば、信用貸付) | |
| 99-その他 | |
| PMT_STRING_84M | 支払いの規律(適時性)。 行は、銀行が口座のデータを局に転送する瞬間の口座ステータスコードで構成され、最初の文字は日付PMT_STRING_STARTの時点のステータスで、日付の降順です。
|
| 0-新規、評価不可 | |
| X-情報なし | |
| 1-遅延なしの支払い | |
| A-1〜29日の遅延 | |
| 2-30日から59日の遅延 | |
| 3-60〜89日の遅延 | |
| 4-90から119日の遅延 | |
| 5-120日以上の遅延 | |
| 7-定期的な一括支払い | |
| 8-担保を使用したローンの返済 | |
| 9-不良債権/回収への振替/支払いの不履行 | |
| ステータス | 契約状況 |
| 00-アクティブ | |
| 12-セキュリティによる支払い | |
| 13-アカウントが閉鎖されました | |
| 14-サービスのために別の銀行に送金 | |
| 21-紛争 | |
| 52-期限切れ | |
| 61-返品の問題 | |
| 卓越した | 残りの未払い債務。 ロシア連邦中央銀行のレートでのルーブルの量 |
| NEXT_PMT
| 次の支払いのサイズ。 ロシア連邦中央銀行のレートでのルーブルの量 |
| INF_CONFIRM_DATE | アカウント情報の確認日 |
| FACT_CLOSE_DATE
| アカウント閉鎖日(実際)
|
| TTL_DELQ_5
| 最大5日間の遅延の数
|
| TTL_DELQ_5_29
| 5〜29日の遅延の数
|
| TTL_DELQ_30_59
| 30から59日の遅延の数
|
| TTL_DELQ_60_89
| 60から89日の遅延の数
|
| TTL_DELQ_30
| 最大30日間の遅延の数
|
| TTL_DELQ_90_PLUS
| 90日以上の遅延の数
|
| PMT_FREQ
| 支払頻度コード
|
| 1-毎週
| |
| 2-2週間に1回
| |
| 3-毎月
| |
| A-2か月に1回
| |
| 4-四半期ごと
| |
| B-4か月に1回
| |
| 5-6か月に1回
| |
| 6-毎年
| |
| 7-その他
| |
| CREDIT_LIMIT
| クレジット制限。 ロシア連邦中央銀行のレートでのルーブルの量
|
| DELQ_BALANCE
| 現在の延滞。 ロシア連邦中央銀行のレートでのルーブルの量
|
| MAX_DELQ_BALANCE
| 延滞の最大量。 ロシア連邦中央銀行のレートでのルーブルの量
|
| CURRENT_DELQ
| 現在の延滞日数
|
| PMT_STRING_START
| 行開始日PMT_STRING_84M
|
| INTEREST_RATE
| ローン金利
|
| CURR_BALANCE_AMT
| 元本、利息、罰金、罰金を含む支払総額。 ロシア連邦中央銀行のレートでのルーブルの量
|
タスクは、「デフォルト」の確率を決定する「トレーニング」サンプルでモデルを構築し、 「テスト」サンプルから顧客の確率を下げることです。 モデルを評価するために、 ROC曲線下面積特性が使用されます(タスク条件にも示されます)。
データの前処理
開始するには、ソースファイルをダウンロードして確認します。
from pandas import read_csv, DataFrame from sklearn.metrics import roc_curve from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier from sklearn.cross_validation import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.neighbors import KNeighborsClassifier from sklearn.decomposition import PCA import ml_metrics, string, re, pylab as pl SampleCustomers = read_csv("https://static.tcsbank.ru/documents/olymp/SAMPLE_CUSTOMERS.csv", ';') SampleAccounts = read_csv("https://static.tcsbank.ru/documents/olymp/SAMPLE_ACCOUNTS.csv",";",decimal =',') print SampleAccounts
SampleCustomers.head()
| tcs_customer_id | 悪い | sample_type | |
|---|---|---|---|
| 0 | 1 | ナン | テストする |
| 1 | 2 | 0 | 電車 |
| 2 | 3 | 1 | 電車 |
| 3 | 4 | 0 | 電車 |
| 4 | 5 | 0 | 電車 |
タスクの条件から、SampleAccountsセットには1人の借り手の複数のレコードが含まれていると想定できます。これを確認しましょう。
SampleAccounts.tcs_customer_id.drop_duplicates().count(), SampleAccounts.tcs_customer_id.count()
私たちの仮定は正しかった。 ユニークな借り手280,942件のレコードのうち50,000件。 これは、1人の借り手が複数のローンを所有しており、それぞれが異なる局の異なる情報を持っているためです。 したがって、1行が1つの借り手に対応するように、SampleAccountsで変換を実行する必要があります。
それでは、借り手ごとにすべてのユニークなローンのリストを取得しましょう。
SampleAccounts[['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']].drop_duplicates()
したがって、ローンのリストを受け取ったときに、リストの各要素の一般的な情報を表示できます。 つまり 上記のフィールドをまとめてインデックスにして、さらに操作を行うこともできますが、残念ながら、不愉快な瞬間が待っています。 それは、データセットの「final_pmt_date」フィールドに空の値があるという事実にあります。 それらを取り除きましょう。
フィールドにはローンの実際の締め切り日が設定されているため、もしそうであれば、フィールド 'final_pmt_date'に値が入力されていない場合は、この値を書き込むことができます。 残りについては、0を書き込むだけです。
SampleAccounts.final_pmt_date[SampleAccounts.final_pmt_date.isnull()] = SampleAccounts.fact_close_date[SampleAccounts.final_pmt_date.isnull()].astype(float) SampleAccounts.final_pmt_date.fillna(0, inplace=True)
空の値を取り除いたので、各ローンのいずれかの局に連絡するための最新の日付を取得しましょう。 これは、契約ステータス、タイプなどの属性を決定するのに役立ちます。
sumtbl = SampleAccounts.pivot_table(['inf_confirm_date'], ['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], aggfunc='max') sumtbl.head(15)
| inf_confirm_date | |||||
|---|---|---|---|---|---|
| tcs_customer_id | open_date | final_pmt_date | credit_limit | 通貨 | |
| 1 | 39261 | 39629 | 19421 | RUB | 39924 |
| 39505 | 39870 | 30000 | RUB | 39862 | |
| 39644 | 40042 | 11858 | RUB | 40043 | |
| 39876 | 41701 | 300,000 | RUB | 40766 | |
| 39942 | 40308 | 19691 | RUB | 40435 | |
| 40421 | 42247 | 169000 | RUB | 40756 | |
| 40428 | 51386 | 10,000 | RUB | 40758 | |
| 40676 | 41040 | 28967 | RUB | 40764 | |
| 2 | 40472 | 40618 | 7551 | RUB | 40661 |
| 40652 | 40958 | 21186 | RUB | 40661 | |
| 3 | 39647 | 40068 | 22694 | RUB | 40069 |
| 40604 | 0 | 20000 | RUB | 40624 | |
| 4 | 38552 | 40378 | 75,000 | RUB | 40479 |
| 39493 | 39797 | 5000 | RUB | 39823 | |
| 39759 | 40123 | 6023 | RUB | 40125 |
次に、受け取った日付をメインセットに追加します。
SampleAccounts = SampleAccounts.merge(sumtbl, 'left', left_on=['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], right_index=True, suffixes=('', '_max'))
したがって、パラメータが厳密に定義されている列をさらに分割し、これらのフィールドの各値に個別の列が含まれるようにします。 条件により、指定された値を持つ列は次のようになります。
- pmt_string_84m
- pmt_freq
- タイプ
- 状態
- 関係
- bureau_cd
それらを変換するコードを以下に示します:
# pmt_string_84m vals = list(xrange(10)) + ['A','X'] PMTstr = DataFrame([{'pmt_string_84m_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.pmt_string_84m]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['pmt_string_84m'], axis=1) # pmt_freq SampleAccounts.pmt_freq.fillna(7, inplace=True) SampleAccounts.pmt_freq[SampleAccounts.pmt_freq == 0] = 7 vals = list(range(1,8)) + ['A','B'] PMTstr = DataFrame([{'pmt_freq_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.pmt_freq]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['pmt_freq'], axis=1) # type vals = [1,4,6,7,9,10,11,12,13,14,99] PMTstr = DataFrame([{'type_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.type]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['type'], axis=1) # status vals = [0,12, 13, 14, 21, 52,61] PMTstr = DataFrame([{'status_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.status]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['status'], axis=1) # relationship vals = [1,2,4,5,9] PMTstr = DataFrame([{'relationship_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.relationship]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['relationship'], axis=1) # bureau_cd vals = [1,2,3] PMTstr = DataFrame([{'bureau_cd_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.bureau_cd]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['bureau_cd'], axis=1)
次のステップでは、最後の実際の支払いの日付を含むフィールド「fact_close_date」を変換して、2つの値のみが含まれるようにします。
- 0-最後の支払いはありませんでした
- 1-最後の支払いは
最初はフィールドが半分いっぱいだったので、この交換を行いました。
SampleAccounts.fact_close_date[SampleAccounts.fact_close_date.notnull()] = 1 SampleAccounts.fact_close_date.fillna(0, inplace=True)
次に、データセットからすべてのローンの最新データを取得する必要があります。 上記で取得した「inf_confirm_date_max」フィールドは、これに役立ちます。 すべての局の信用情報を更新する期限を追加しました。
PreFinalDS = SampleAccounts[SampleAccounts.inf_confirm_date == SampleAccounts.inf_confirm_date_max].drop_duplicates()
上記のアクションの後、サンプルは大幅に削減されましたが、今度は以前に取得したローンと借り手に関するすべての情報を要約する必要があります。 これを行うには、データセットをグループ化します。
PreFinalDS = PreFinalDS.groupby(['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']).max().reset_index()
データを分析する準備がほぼ整いました。 さらにいくつかのアクションを実行します。
- 不要な列を削除する
- すべての信用限度をルーブルで持ち込みます
- 局からの情報に従って、各借り手にいくつのローンを計算する
不要な列のテーブルをクリアすることから始めましょう。
PreFinalDS = PreFinalDS.drop(['bki_request_date', 'inf_confirm_date', 'pmt_string_start', 'interest_rate', 'open_date', 'final_pmt_date', 'inf_confirm_date_max'], axis=1)
次に、すべての与信限度をルーブルに移します。 簡単にするために、現在の為替レートを使用しました。 おそらく、口座開設時にコースを受講する方が正しいでしょう。 別のニュアンスは、分析のために「urrency」テキストフィールドを削除する必要があることです。したがって、通貨をルーブルに変換した後、このフィールドを上記のフィールドで操作します。
curs = DataFrame([33.13,44.99,36.49,1], index=['USD','EUR','GHF','RUB'], columns=['crs']) PreFinalDS = PreFinalDS.merge(curs, 'left', left_on='currency', right_index=True) PreFinalDS.credit_limit = PreFinalDS.credit_limit * PreFinalDS.crs # vals = ['RUB','USD','EUR','CHF'] PMTstr = DataFrame([{'currency_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in PreFinalDS.currency]) PreFinalDS = PreFinalDS.join(PMTstr).drop(['currency','crs'], axis=1)
したがって、最終的なグループ化の前に、ユニットで満たされたフィールドをセットに追加します。 つまり 最後のグループ化を行うと、その金額は借り手からのローンの数を示します。
PreFinalDS['count_credit'] = 1
データセットのすべてのデータが定量的になったので、データ0のギャップを埋めて、顧客ごとに最終的なグループ化を実行できます。
PreFinalDS.fillna(0, inplace=True) FinalDF = PreFinalDS.groupby('tcs_customer_id').sum() FinalDF
予備分析
さて、一次データ処理が完了し、分析を開始できます。 まず、データをトレーニングサンプルとテストサンプルに分割します。 SampleCustomersの「sample_type」列がこれに役立ちます。まさにそのような分離が行われました。
処理済みのDataFrameを壊すには、SampleCustomersと組み合わせて、フィルターで再生します。
SampleCustomers.set_index('tcs_customer_id', inplace=True) UnionDF = FinalDF.join(SampleCustomers) trainDF = UnionDF[UnionDF.sample_type == 'train'].drop(['sample_type'], axis=1) testDF = UnionDF[UnionDF.sample_type == 'test'].drop(['sample_type'], axis=1)
次に、符号が相互にどのように相関するかを見てみましょう。このために、符号の相関係数を使用して行列を作成します。 パンダでは、これは1つのコマンドで実行できます。
CorrKoef = trainDF.corr()
上記のアクションの後、CorrKoefには61x61サイズのマトリックスが含まれます。
その行と列は対応するフィールド名であり、それらの交差点では相関係数の値になります。 例:
| fact_close_date | |
|---|---|
| status_13 | 0.997362 |
相関係数がない場合が考えられます。 これは、これらのフィールドに1つの同一値のみが入力される可能性が高く、分析中に省略できることを意味します。 チェック:
FieldDrop = [i for i in CorrKoef if CorrKoef[i].isnull().drop_duplicates().values[0]]
出力では、削除可能なフィールドのリストが得られました。
- pmt_string_84m_6
- pmt_string_84m_8
- pmt_freq_5
- pmt_freq_A
- pmt_freq_B
- status_12
次のステップは、マトリックスを使用して、相互に相関するフィールド(相関係数が90%を超えるフィールド)を見つけることです。
CorField = [] for i in CorrKoef: for j in CorrKoef.index[CorrKoef[i] > 0.9]: if i <> j and j not in CorField and i not in CorField: CorField.append(j) print "%s-->%s: r^2=%f" % (i,j, CorrKoef[i][CorrKoef.index==j].values[0])
出力では、次のものが得られます。
fact_close_date-> status_13:r ^ 2 = 0.997362
ttl_delq_5_29-> ttl_delq_30:r ^ 2 = 0.954740
ttl_delq_5_29-> pmt_string_84m_A:r ^ 2 = 0.925870
ttl_delq_30_59-> pmt_string_84m_2:r ^ 2 = 0.903337
ttl_delq_90_plus-> pmt_string_84m_5:r ^ 2 = 0.978239
delq_balance-> max_delq_balance:r ^ 2 = 0.986967
pmt_freq_3-> relationship_1:r ^ 2 = 0.909820
pmt_freq_3-> currency_RUB:r ^ 2 = 0.910620
pmt_freq_3-> count_credit:r ^ 2 = 0.911109
したがって、前の手順で受け取った関係に基づいて、次のフィールドを削除リストに追加できます。
FieldDrop =FieldDrop + ['fact_close_date','ttl_delq_30', 'pmt_string_84m_5', 'pmt_string_84m_A', 'pmt_string_84m_A', 'max_delq_balance', 'relationship_1', 'currency_RUB', 'count_credit'] newtr = trainDF.drop(FieldDrop, axis=1)
モデルの構築と選択
さて、処理される主要なデータは何であり、これでモデルの構築に進むことができます。
クラス属性をトレーニングセットから分離します。
target = newtr.bad.values train = newtr.drop('bad', axis=1).values
ここで、重要なパラメーターのみを取得するために、サンプルの次元を縮小します。 これを行うには、 sklearnモジュールの主成分メソッドとPCA()の実装を使用します。 パラメーターには、保存するコンポーネントの数を渡します(20を選択したのは、モデルの結果が実際には初期データによる結果と変わらなかったためです)
coder = PCA(n_components=20) train = coder.fit_transform(train)
分類モデルを定義する時が来ました。 いくつかの異なるアルゴリズムを使用して、 ROC曲線下領域 ( auc )の特性を使用して作業の結果を比較してみましょう。 モデリングでは、次のアルゴリズムが考慮されます。
models = [] models.append(RandomForestClassifier(n_estimators=165, max_depth=4, criterion='entropy')) models.append(GradientBoostingClassifier(max_depth =4)) models.append(KNeighborsClassifier(n_neighbors=20)) models.append(GaussianNB())
したがって、モデルが選択されます。 トレーニングサンプルを、テストとトレーニングの2つのサブサンプルに分割しましょう。 このアクションは、モデルのauc特性を計算できるようにするために必要です。 分割は、 sklearnモジュールのtrain_test_split()関数を使用して実行できます。
TRNtrain, TRNtest, TARtrain, TARtest = train_test_split(train, target, test_size=0.3, random_state=0)
モデルを訓練し、結果を評価することは残っています。
AUC特性を計算するには2つの方法があります。
- roc_auc_scoreまたはauc関数を使用したsklearnモジュールの標準的な手段により
- サードパーティのml_metricsパッケージとauc ()関数を使用する
私は2番目の方法を使用します 最初の記事は前の記事で紹介されました。 ml_metricsパッケージは、sklearnへの非常に便利な追加です。 sklearnにはないいくつかのメトリックが含まれています。
したがって、ROC曲線を作成し、その面積を計算します。
plt.figure(figsize=(10, 10)) for model in models: model.fit(TRNtrain, TARtrain) pred_scr = model.predict_proba(TRNtest)[:, 1] fpr, tpr, thresholds = roc_curve(TARtest, pred_scr) roc_auc = ml_metrics.auc(TARtest, pred_scr) md = str(model) md = md[:md.find('(')] pl.plot(fpr, tpr, label='ROC fold %s (auc = %0.2f)' % (md, roc_auc)) pl.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6)) pl.xlim([0, 1]) pl.ylim([0, 1]) pl.xlabel('False Positive Rate') pl.ylabel('True Positive Rate') pl.title('Receiver operating characteristic example') pl.legend(loc="lower right") pl.show()
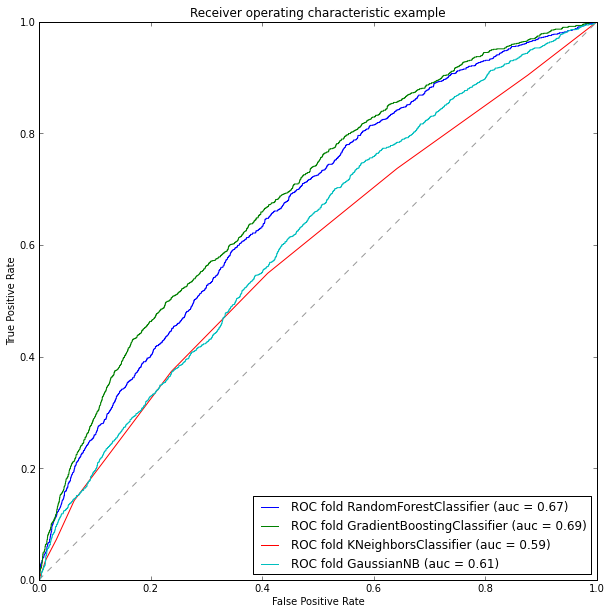
そのため、モデルの分析結果によると、勾配ブースティングが最も効果的であり、精度は約69%であると言えます。 したがって、テストサンプルをトレーニングするには、それを選択します。 テストサンプルの情報を入力して、目的の形式に前処理します。
# FieldDrop.append('bad') test = testDF.drop(FieldDrop, axis=1).values test = coder.fit_transform(test) # model = models[1] model.fit(train, target) # testDF.bad = model.predict(test)
おわりに
結論として、得られた69%のモデルの精度は十分ではありませんが、これ以上の精度を達成することはできませんでした。 モデルを完全な次元で構築する場合、つまり 相関列と次元削減を除外すると、69%の精度も得られました(これは、モデルトレーニング用のtrainDFキットを使用して簡単に確認できます)
この記事では、生データの一次処理から分類モデルの構築まで、データ分析のすべての主要な段階を示しました。 さらに、分析されたモデルにサポートベクトル法が含まれていなかったことに注意してください。これは、データを正規化した後、モデルの精度が51%に低下し、それで得られた最高の結果が約60%であり、有意であったためです時間のコスト。
また、残念ながら、テストサンプルは結果を検証できませんでした。 トーナメントの日付を満たしていませんでした。