 この投稿は、Habrの記事とコメントの中で最も一般的な単語についてのhaxtraiser Muxtoの この研究の続きです。 ただし、多くの人が気づいたように、 Muxtoが取得した上位10個、さらには上位50個にも、IT用語が十分にありません。「in」(107,735)、「and」(106、420)、「on」 (103 084)、「s」(93 453)、「not」(91 591)、「what」(88 488)など。
この投稿は、Habrの記事とコメントの中で最も一般的な単語についてのhaxtraiser Muxtoの この研究の続きです。 ただし、多くの人が気づいたように、 Muxtoが取得した上位10個、さらには上位50個にも、IT用語が十分にありません。「in」(107,735)、「and」(106、420)、「on」 (103 084)、「s」(93 453)、「not」(91 591)、「what」(88 488)など。
次の明白なステップは、ロシア語の平均から最も大きく逸脱した用語を特定することでした。 研究の最初の部分の著者から「ゴーゴーアヘッド」を受け取り、トレプトユーザーと数学的質問を議論した後、私は次の活動に進みました。
ロシア語国立コーパス(NCRF)のサイトから、「中規模」ロシア語の単語形式の頻度ベースが、192 689 044単位(単語)の総量のテキストの分析に基づいてダウンロードされました。 データベースには、大文字と小文字が区別される1 054 211個の単語形式が含まれています。 Muxtoが提示するHabra語彙の分析は大文字と小文字を区別せず、原則としてこれは最終目標とより一貫しているため、最初のタスクはすべての単語形式を小文字にすることでした。 NKRYベースには、大文字と小文字を区別しない一意の単語形式が888 397個しかありません(結合された形式の頻度値は、当然ながら合計されています)。
2番目の質問は、重要な単語の実際の識別でした。 判明したように、この問題は統計学とコンピューター技術を積極的に使用する現代言語学で長い間解決されてきました。 1つのケースにおける単語の出現頻度の「不均一性」の程度の統計量の1つは、特に言語学者が好んだケースの一般的なセットに関連して、尤度比テストの特別なケースであるGテストです。 単一の単語の統計は次のように計算されます
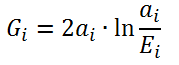
ここでa iは、調査中のケースでi番目の単語形式の実際に観測された頻度です。
そして、 E iは、ケースが組み合わされている場合、すなわち、検討中のケースにおける同じ単語形式の予想頻度です。
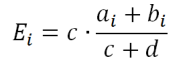
ここで、a iおよびb iは、建物(HabrおよびNKRYA)でのi番目の単語形式の出現頻度です。
cおよびdは、これらの建物の総容積です(それぞれ33 732 229および192 689 044単位)。
したがって、すべての計算が行われ、単語は統計G iの上位30の順にソートされます。
405587,703 197850,057 139330,707 135705,259 124132,397 121233,522 116809,907 113262,075 109463,742 94468,080 92093,985 79257,370 com 77786,398 74006,346 71844,136 ru 66674,626 64946,067 63195,334 60807,287 60433,187 google 55160,380 55147,137 53984,795 52609,986 windows 50998,105 50177,316 48421,264 http 48372,913 48328,683 48158,301
疑わしい? はい、自白します。最初の単語形式を選択して、最初の実行後、トップ150の同じ単語のいくつかの形式の頻度を結合しました。 「user / user / users」または「version / versions / version」などの非常に高い指標を持つ単語を上部に表示するのは残念でしたが、ロシア語には終了ケースと数字が豊富であるという理由だけでリーダーには表示されません。
上位30位と上位150位のHabrahabrは、間違いなく反省に値します。 個人的には、結果に満足しました-私の意見では、このユニークなITリソースの本質は非常に正確に強調されました。 まあ、リーダー- 「ユーザー」 -私たちが何時間も、何日も、何年も私たちの生活の中で過ごす一般的な目標です。
Wordle.netは、ロードされた上位30(G統計に比例する頻度で)およびこのタグクラウドのHabrのカラーパレットに反応しました。

そして、私にとって残っているのは、言語学的なウォームアップとして、あなたがトップ30からの言葉で最も長い文でコメントを出すことです。
楽観的で退屈な金曜日をお祈りします!