OpenMPは、スレッド、共有メモリを備えたシステムでの並列プログラミングの最も一般的なモデルです。 彼らは、プログラミングシステムスレッドと比較して、高レベルの並列構造と、さまざまなコンパイラメーカーによるサポートに感謝しています。 しかし、この投稿はOpenMP標準そのものに関するものではなく、ネットワーク上に多くの資料があります。
パフォーマンスを目的としたOpenMPでの計算の並列化。実際にはこれについての記事です。 具体的には、Intel VTune Amplifier XEを使用したパフォーマンスの測定について。 つまり、次に関する情報を取得する方法:
- OpenMPアプリケーション全体のプロファイルを取得する
- 選択された並列OpenMP領域のプロファイル(CPU時間、ホット関数など)
- 別の並列OpenMP領域内での作業のバランス
- パラレル/シリアルバランス
- 並列タスクの粒度レベル
- スレッド間の同期、遅延、および制御転送
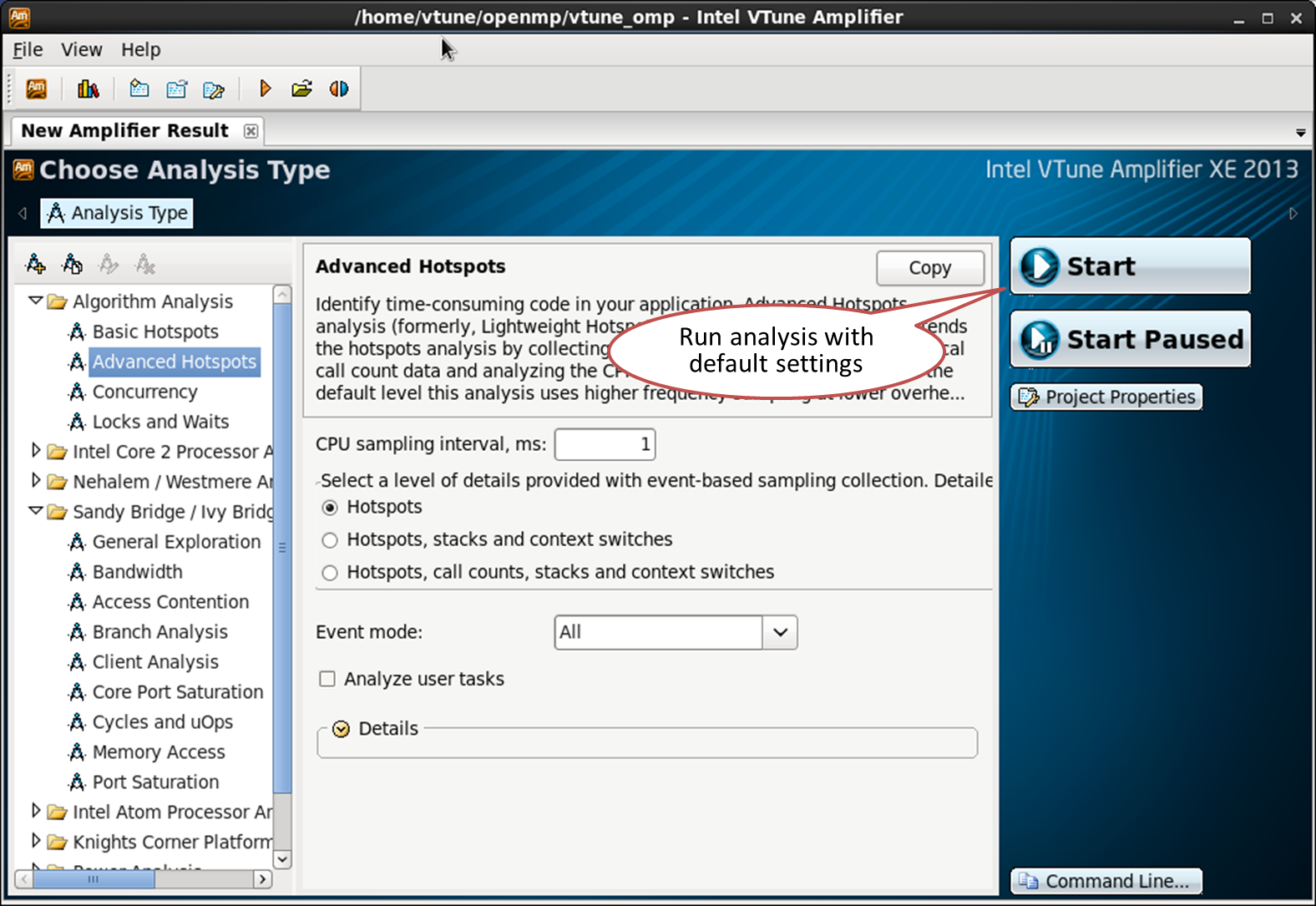
OpenMPアプリケーションプロファイリングの起動
OpenMPプログラムのプロファイルを作成するには、VTune Amplifier XE 2013 Update 4以降が必要です。 Composer XE 2013 Update 2以降をビルドする方がアプリケーションが優れています。 Intelまたは他のメーカー(GCCおよびMicrosoft OpenMP)からの古いOpenMP実装の分析も可能ですが、あまり有用ではない情報が収集されます。 VTune Amplifier XEは、並列領域を認識できません。
この記事で説明するすべての手順は、WindowsおよびLinuxで有効です。 上記の例はLinuxでテストされています。
コンパイラがIntel Composer XE 2013 SP1よりも古い場合、環境変数KMP_FORKJOIN_FRAMESを1に設定する必要があります。これは、プロジェクトプロパティの[ユーザー定義の環境変数]ダイアログで、または手動でVTune Amplifierで実行できます。
export KMP_FORKJOIN_FRAMES=1
並列領域を持つソースファイルに関する完全な情報を取得するには、-parallel-source-info = 2オプションを使用してコンパイルします。 私の例では、次のようなコンパイル行を使用しました。
icc -openmp -O3 -g -parallel-source-info=2 omptest.cpp work.cpp -o omptest
それ以外は、通常のアプリケーションの分析と違いはありません。VTuneAmplifierを起動し、プロジェクトを作成し、アプリケーションを指定して、プロファイリングを開始します。
OpenMP並列領域の紹介
OpenMP並列領域は、VTune Amplifier XEではフレームドメインとして表されます。 フレームは、アプリケーションの重複しない実行時間のシーケンスです。 つまり プログラムの実行時間全体をステージに分割することができます。たとえば、ステージ1(初期化)、ステージ2(作業)、ステージ3(完了)です。 これらの段階は、3つのフレームで表すことができます。 フレームはグラフィカルアプリケーションでよく参照されます-考え方は同じですが、VTuneアンプではフレームの概念が広くなっています。 フレームはグローバルであり、特定のスレッドに関連付けられていません。
各並列OpenMP領域は、個別のフレームドメインとして表示されます。 ソースファイルと行番号で識別されます。 ドメインフレームは、ソースコード内の領域を示します。 この地域のすべての課題はフレームです。 フレーム-スレッド(フォーク)の分離(または開始)ポイントからそれらの再結合(結合)ポイントまでの期間。 フレームの数は、スレッドの数やタスクのサイズとは関係ありません。
以下の擬似コードには、OpenMPの2つの並列構造、2つの領域が含まれています。 これらはそれぞれ、VTune Amplifier XEプロファイルでドメインフレームとして認識されるため、2つのドメインフレームがあります。
int main() { #pragma omp parallel for // frame domain #1, frame count: 1 for (int i=0; i < NUM_ITERATIONS; i++) { do_work(); } for (int j=0; j<4; j++) { #pragma omp parallel for // frame domain #2, frame count: 4 for (int i=0; i < NUM_ITERATIONS; i++) { do_work(); } } }
最初のドメインフレームは1回だけ呼び出されます。 したがって、並列ループの本体が16スレッドですぐに実行される場合でも、フレームドメイン#1には1フレームしかありません。 2番目の並列領域(フレームドメイン#2)は、ループから順番に4回起動されます。 反復ごとに、対応するスレッドの開始と終了を伴う並列構造が呼び出されます。 したがって、フレームドメイン#2のVTune Amplifier XEプロファイルには4つのフレームがあります。
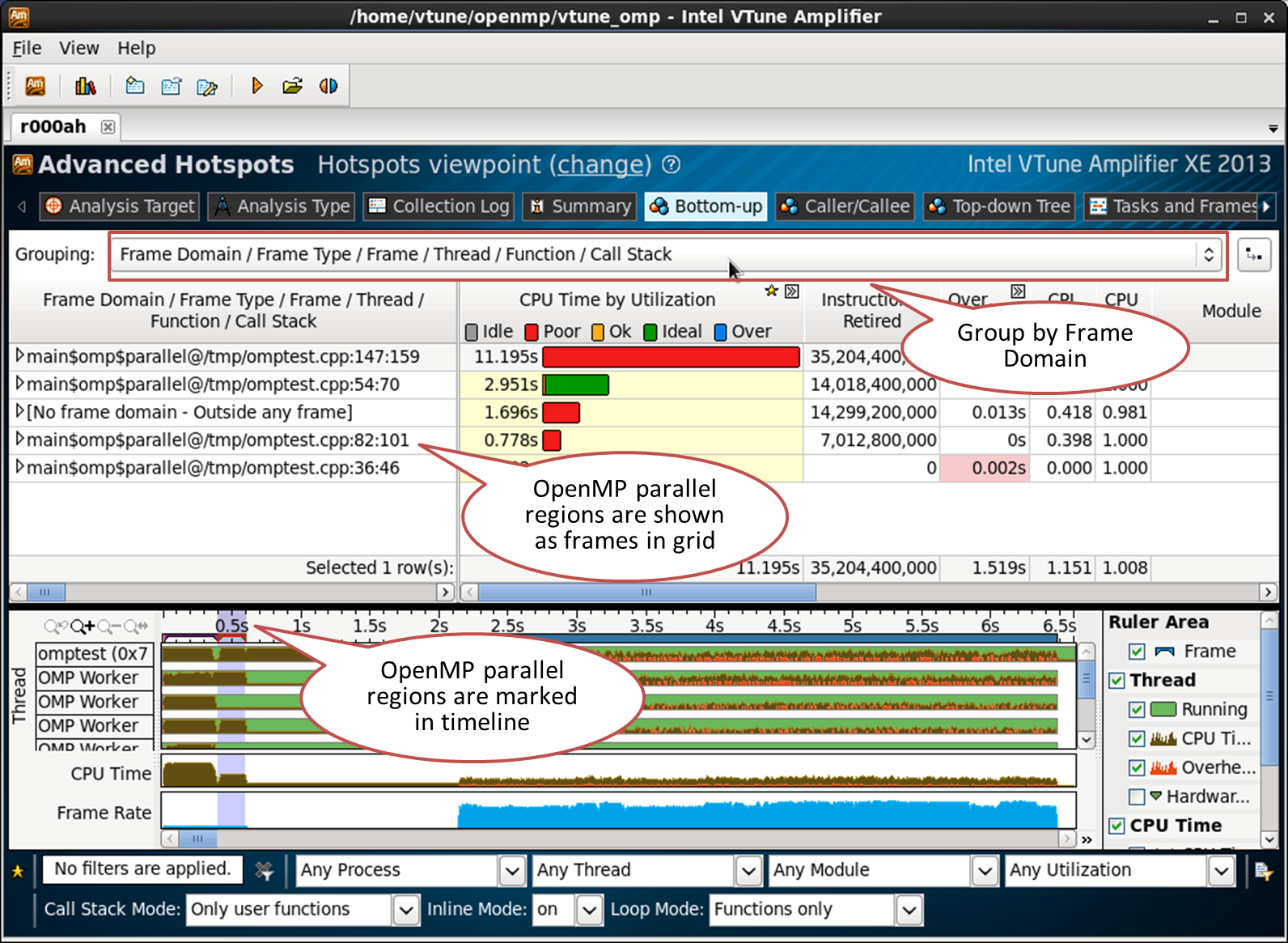
プログラムがIntel OpenMPランタイムを使用する場合、並列領域が認識されます。 VTune Amplifier XEの結果としてそれらを表示するには、[ボトムアップ]タブに切り替えて、[フレームドメイン/フレームタイプ...]によるグループ化を選択します。
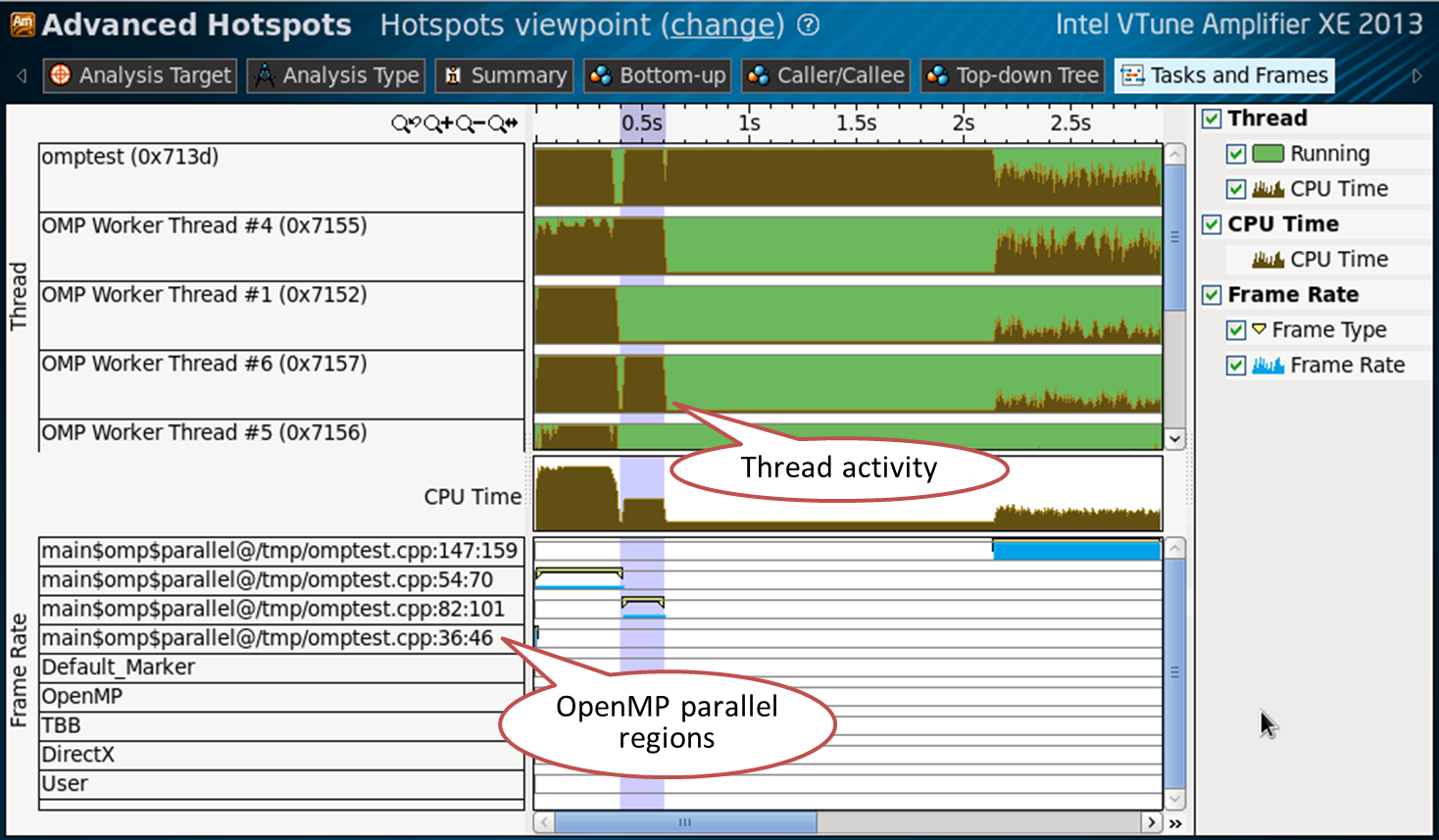
並列OpenMP領域とそれに対応するスレッドアクティビティは、[タスクとフレーム]タブでも確認できます。
シーケンシャル領域
常に、CPUは並列領域の外側で消費され、「[No frame domain-any any outside]」と呼ばれるフレームドメインにアセンブルされます。 これにより、コードのシーケンシャル部分を評価できます。

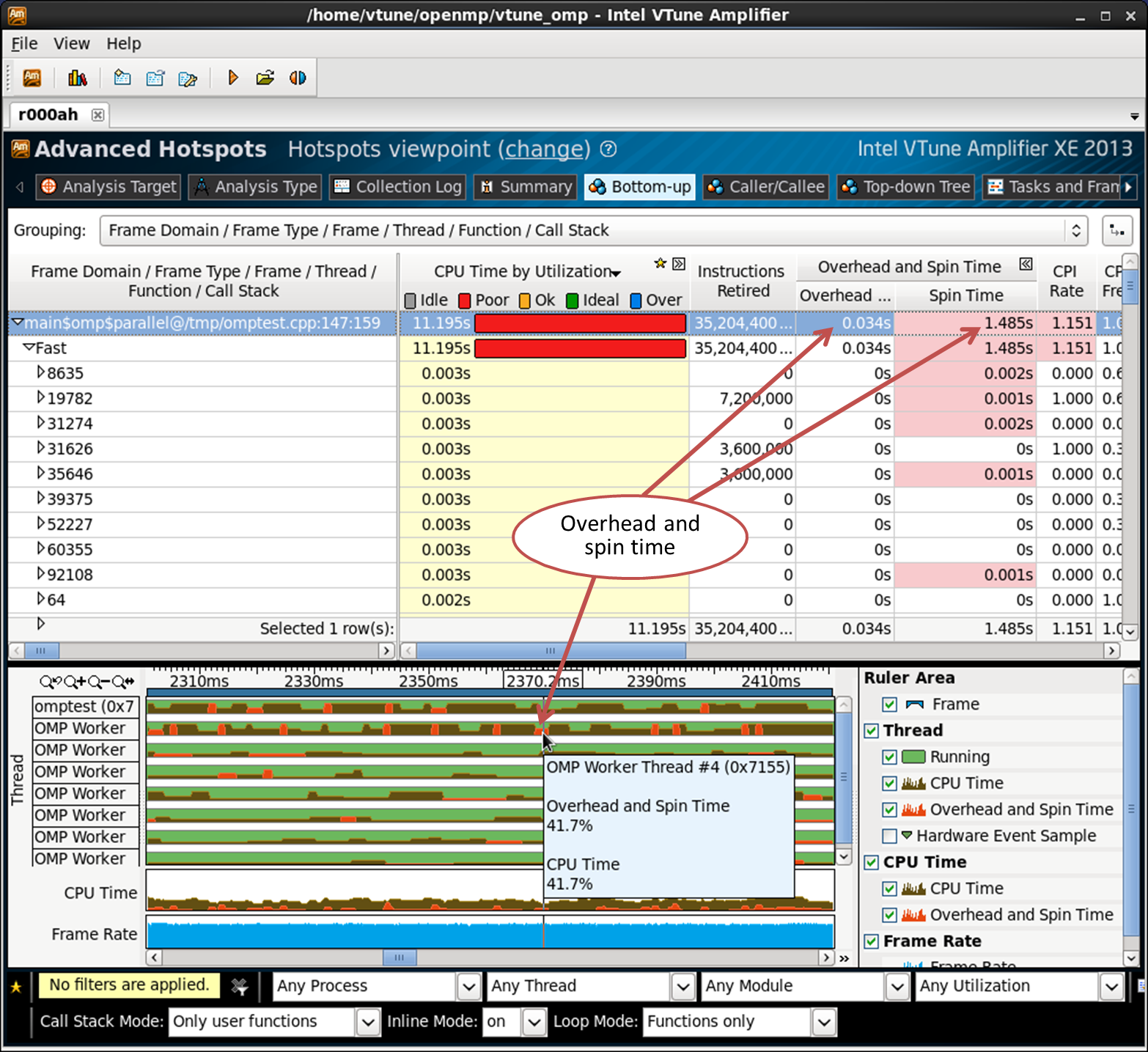
オーバーヘッドとアクティブな待機(オーバーヘッドとスピン時間)
OpenMPのオーバーヘッド時間は、スレッド管理、作業配分、スケジューリング、同期などに関連する内部ランタイムプロシージャの実行に費やされた時間です。 この時間は、有用な計算ではなく、ライブラリの内部関数に費やされました。 Active Spin Time — CPUが実行されている時間。 これは、たとえば、同期オブジェクトがポーリングコールを行うと、アイドル状態になるのではなく、待機中にスピンします。 OpenMPストリームは、たとえば同期バリアでこのようにスピンすることもできます。
オーバーヘッドとアクティブな待機は、CPU時間を消費する既知の関数名と呼び出しシーケンスによってキャッチされます。 一部の内部OpenMP関数はスレッド、タスクなどを制御するため、それらに費やされる時間はオーバーヘッドに関連しています。 アクティブな待機時間は、「ねじれ」を実装する機能によっても決定されます。
オーバーヘッドとアクティブな待機は、Intel OpenMP、GCCおよびMicrosoft OpenMPランタイム、Intel Threading Building Blocks、Intel Cilk Plusに対して定義されています。
シナリオ1:完全にバランスの取れた並列領域
私の簡単な例では、54行目のomptest.cppの並列領域が適しています。 「フレームドメイン/フレームタイプ/フレーム/スレッド/関数/コールスタック」でグループ化されたボトムアップタブを確認します。
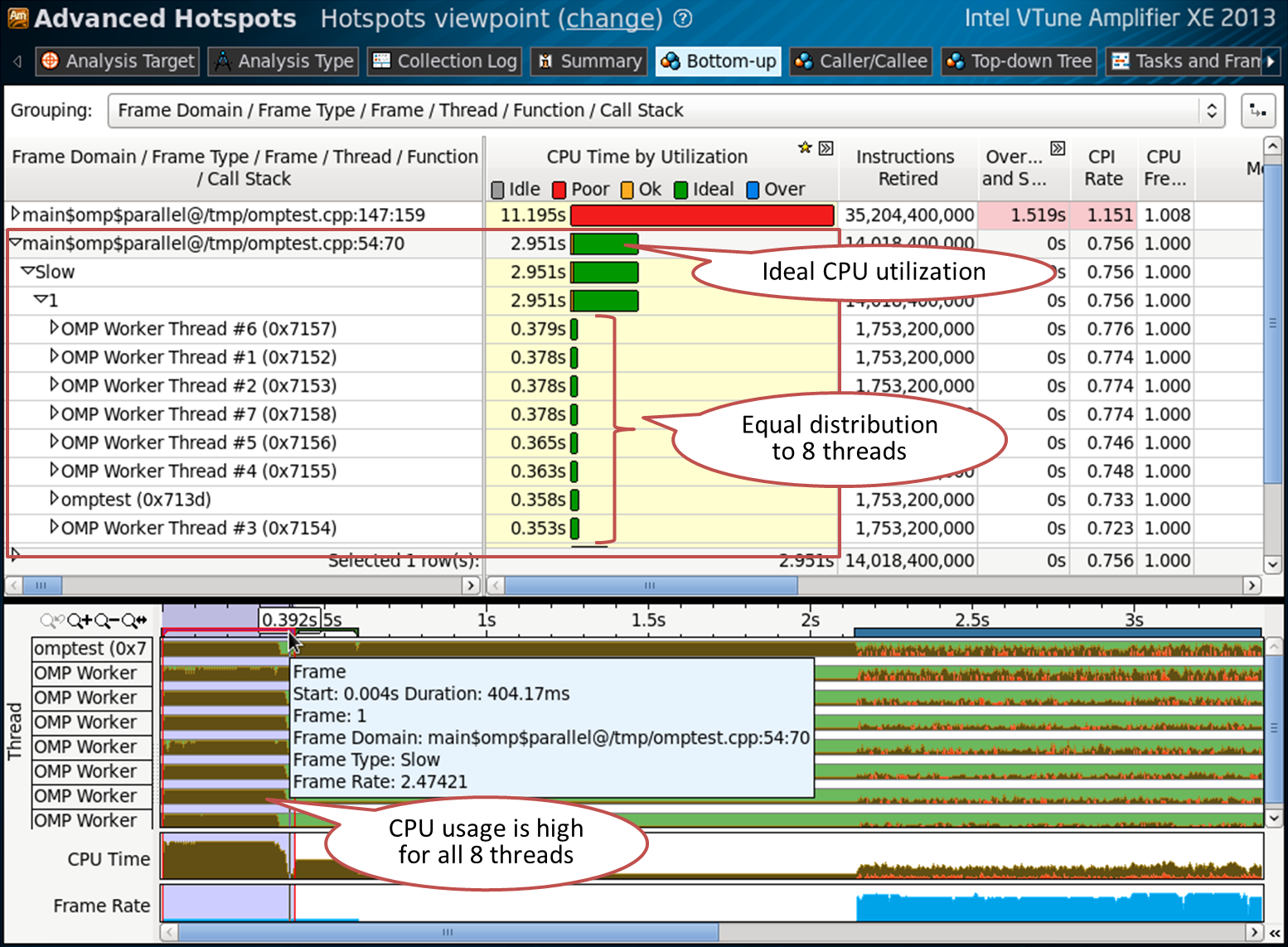
ドメインフレームに含まれるフレームは1つだけです。つまり、並列領域は1回だけ呼び出されました。 表の詳細を開くと、8つのスレッドが表示されます。 これは、テストが実施された4コアのハイパースレッディングマシンに適しています。 CPUは適切にロードされ(CPUタイムバーの緑色)、8つのスレッドすべてがこの領域でビジーであり、ほぼ同じ量の作業を実行します。 この並列領域はタイムライン上でマークされており、8つのスレッドすべてのCPU使用率が高いことも示しています。 これは、すべてが完璧であることを意味するものではありません。たとえば、キャッシュミスやSIMD命令の不十分な使用がある可能性があります。 しかし、OpenMPストリームとワークバランスの問題は見つかりませんでした。
54行目の例のコード:
#pragma omp parallel for schedule(static,1) // line 54 for (int index = 0 ; index < oloops ; index++) { double *a, *b, *c, *at ; int ick ; a = ga + index*84 ; c = gc + index*84 ; fillmat (a) ; ick = work (a, c,gmask) ; if (ick > 0) { printf("error ick failed\n") ; exit(1) ; } }
シナリオ2:不均衡な並列領域
行82の領域はそれほどバランスが取れていません。 使用可能な8つのスレッドのうち4つのみを使用し、残りの4つは待機しています。 これは、プロセッサの負荷レベル(赤)に反映されます。
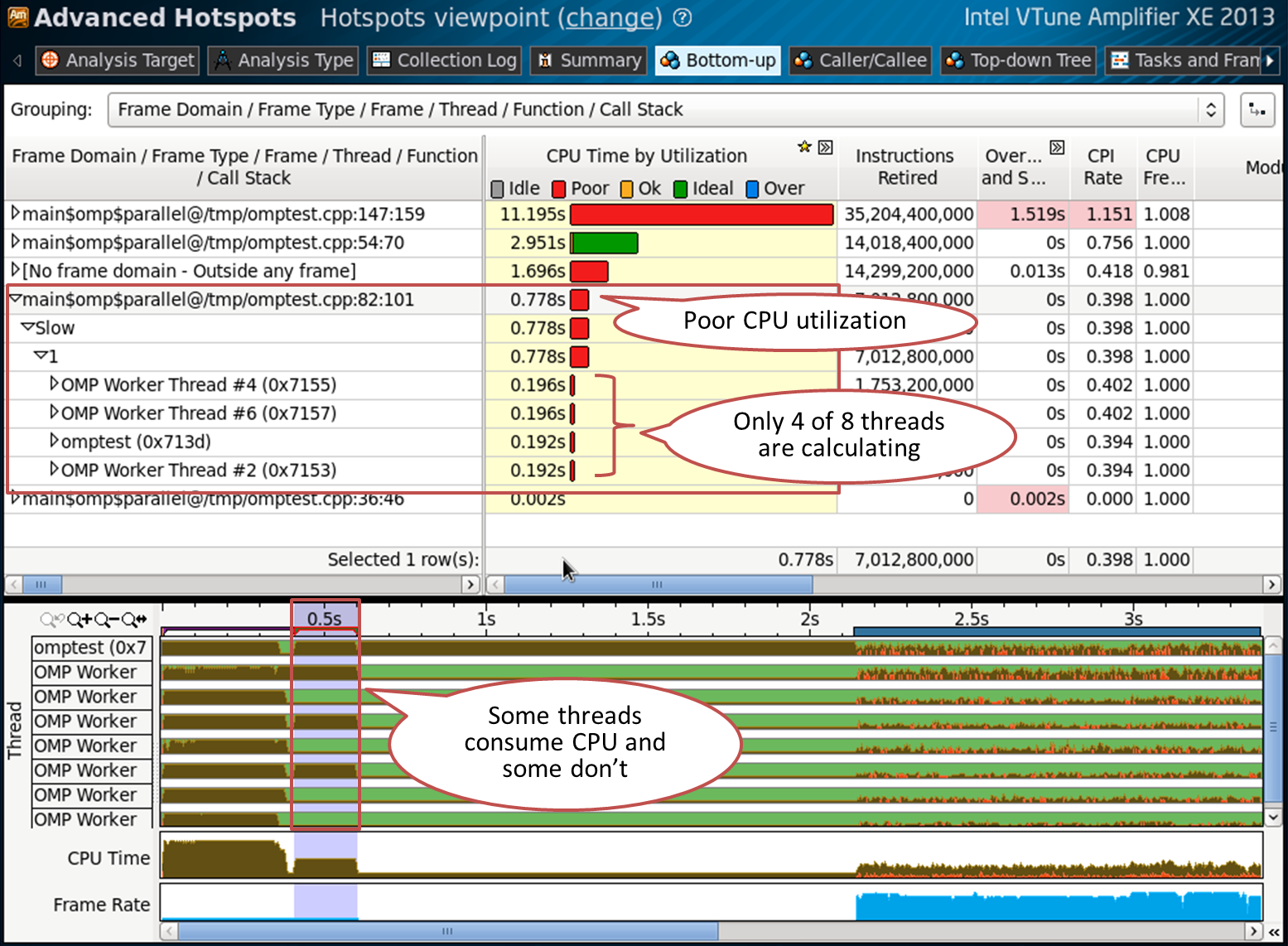
行82のコード(2回目の反復ごとにオフにする):
#pragma omp parallel for schedule(static,1) // line 82 for (int index = 0 ; index < oloops ; index++) { double *a, *b, *c, *at ; int ick ; if (index%2 == 0) { a = ga + index*84 ; c = gc + index*84 ; fillmat (a) ; ick = work (a, c, gmask) ; if (ick > 0) { printf("error ick failed\n") ; exit(1) ; } } }
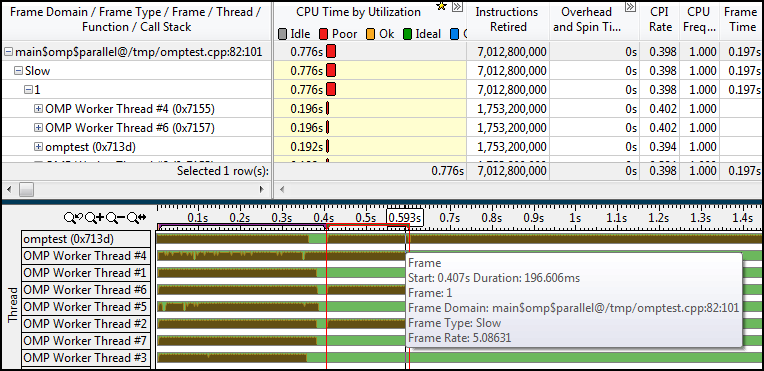
シナリオ3:粒度の問題
前の例には、1つのフレームドメインと1つのフレームがありました。 147行目の領域には多くのフレームが含まれています。
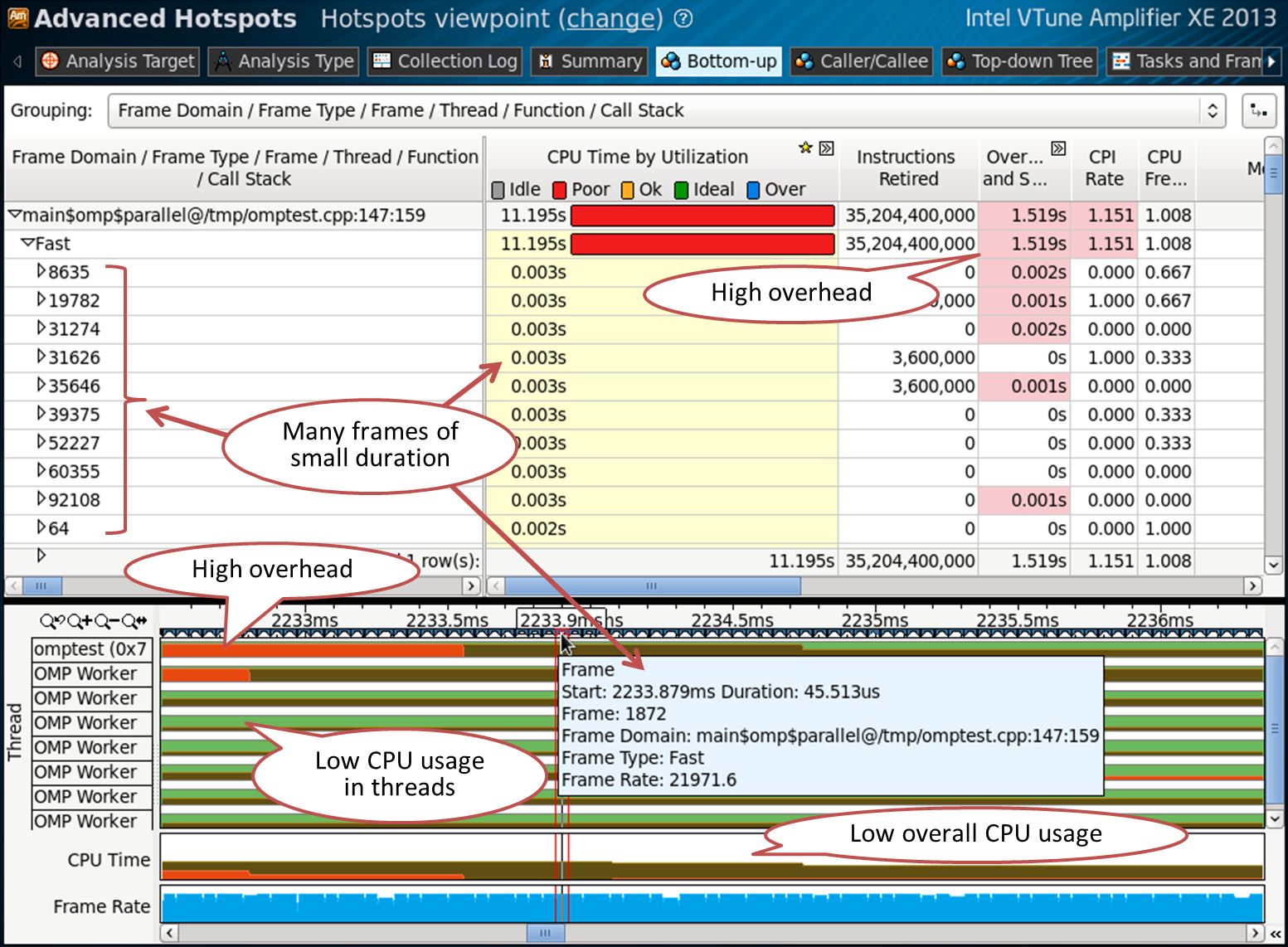
これは、並列領域が何度も呼び出されたことを意味します。 各フレームのCPU時間は非常に短いです。これは、タイムラインでフレームにカーソルを合わせるとポップアップウィンドウに表示されることもあります。 これは、非常に短い並列OpenMP領域を頻繁に実行するという意味で、粒度が高すぎることを示唆しています。 これにより、多くのオーバーヘッドと低いCPU使用率が得られます。
147行目のコード:
for (q = 0 ; q < LOOPS ; q++) { #pragma omp parallel for schedule(static,1) firstprivate(tcorrect) lastprivate(tcorrect) // line 147 for (int index = 0 ; index < oloops ; index++) { double *la, *lc; int lq,lmask ; la = ga + index*84 ; lc = gc + index*84 ; lq = q ; lmask = gmask ; ick = work1(ga, gc, lq,lmask) ; if (ick == VLEN) tcorrect++ ; } }
シナリオ4:オブジェクトとタイムアウトの同期
同期オブジェクトの待機は、パフォーマンスの重大なボトルネックになる可能性があります。 アプリケーションの同期と期待の全体像については、「ロックと待機」分析を収集します。 開始する前に、新しい分析の設定で「ユーザータスクの分析」および「Intelランタイムとユーザー同期の分析」チェックボックスを有効にします。
ボトムアップパネルには、タイムアウト順にソートされた同期オブジェクトのリストが表示されます。
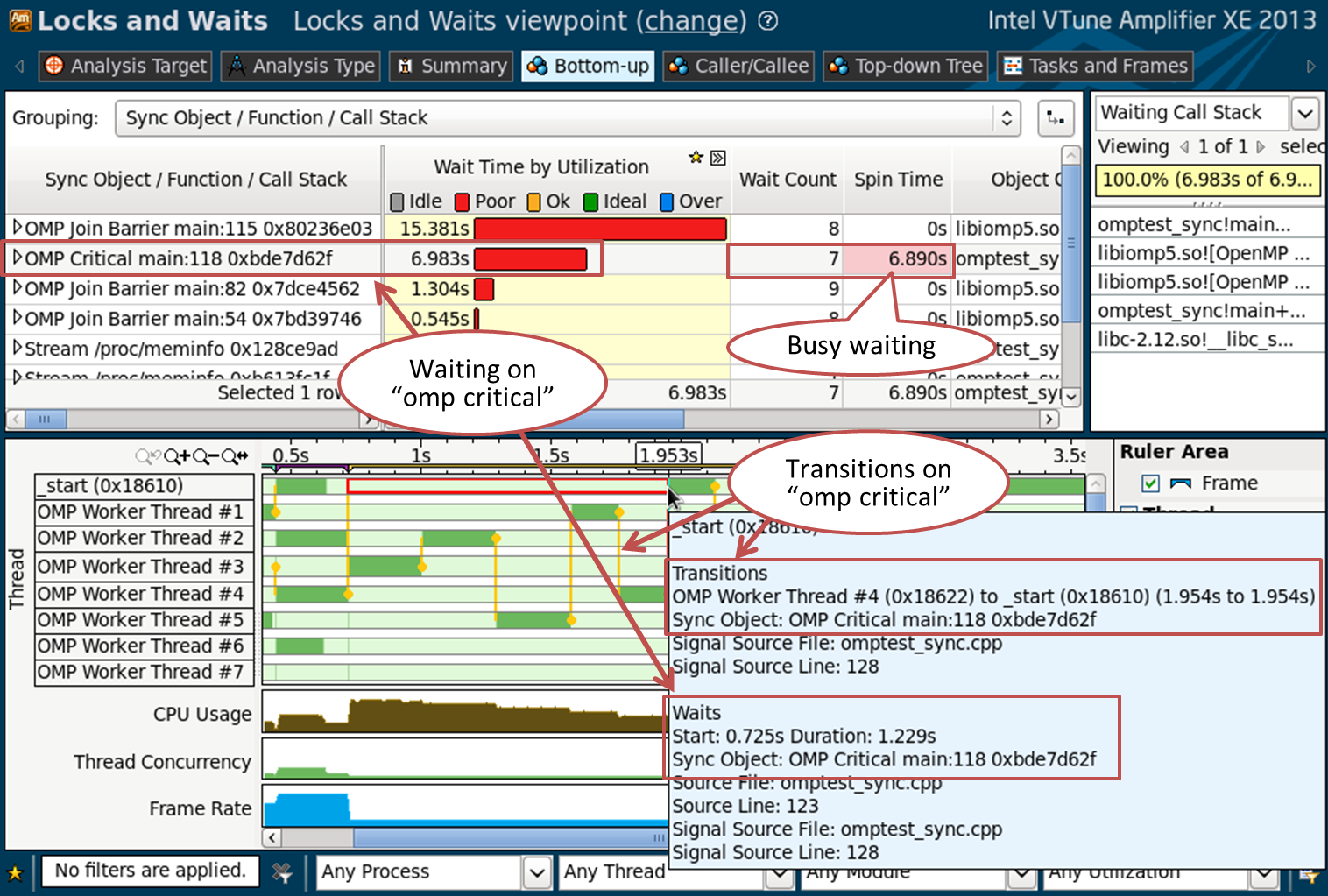
VTune Amplifier XEは、ompクリティカルコンストラクトなどのOpenMP同期プリミティブ、またはOpenMPランタイム内で使用される同期バリアを認識できます。 待機に費やされた時間とそれがどのように分配されているかを見ることができます。多くの短期間の期待、またはいくつかの長期の予想です。 VTune Amplifier XEは、スレッドがアクティブに待機していた(スピン待機)か、実際にスタンバイ状態になったかを示します。 タイムラインは、トランジションの画像-黄色の縦線を提供します。 それらから、どのフローが同期オブジェクトをインターセプトしたか、頻度、オブジェクトの種類、待機時間などを理解できます。
118行目のコード:
#pragma omp parallel for schedule(static,1) for (int index = 0 ; index < oloops ; index++) { #pragma omp critical (my_sync) // line 118 { double *a, *b, *c, *at ; int ick ; a = ga + index*84 ; c = gc + index*84 ; fillmat (a) ; ick = work (a, c,gmask) ; if (ick > 0) { printf("error ick failed\n") ; exit(1) ; } } }
まとめ
Intel VTune Amplifier XEを使用すると、OpenMPアプリケーションの内部を詳しく見ることができます。 シリアルコードとパラレルコードのバランス、および各並列領域でのプログラムの動作を評価できます。 Intel VTune Amplifier XEは、OpenMPストリーム間の負荷分散の問題、粒度の問題、オーバーヘッドの推定、タイミングパターンの理解に役立ちます。 プロセッサー使用量に関する詳細な統計を特定のOpenMPリージョンにリンクすると、アプリケーションの動作をよりよく理解できます。 Intel OpenMPランタイムを使用して最も詳細な情報を取得できますが、他の実装(GCCおよびMicrosoft OpenMP)のプロファイリングも可能です。