システムビューの本体とその他のスクリプトオブジェクトを表示するには、関数-OBJECT_DEFINITIONを使用します。
PRINT OBJECT_DEFINITION(OBJECT_ID('sys.objects'))
ただし、 OBJECT_DEFINITIONとその対応するsp_helptextには重大な欠点があります。これらを使用して、テーブルオブジェクトのスクリプト記述を返すことはできません。
IF OBJECT_ID('dbo.Table1', 'U') IS NOT NULL DROP TABLE dbo.Table1 GO CREATE TABLE dbo.Table1 (ColumnID INT PRIMARY KEY) GO EXEC sys.sp_helptext 'dbo.Table1' SELECT OBJECT_DEFINITION(OBJECT_ID('dbo.Table1', 'U'))
sp_helptextを実行すると、エラーが発生します。
メッセージ15197、レベル16、状態1、プロシージャsp_helptext、行107
オブジェクト 'dbo.Table1'のテキストはありません。
同じ条件下で、 OBJECT_DEFINITIONシステム関数はNULLを返します 。
また、このシステムビュー内ではOBJECT_DEFINITION関数への同じ呼び出しが使用されるため、 sys.sql_modulesからフェッチしても問題は解決しません。
CREATE VIEW sys.sql_modules AS SELECT object_id = o.id, definition = object_definition(o.id), ... FROM sys.sysschobjs o
いくつかのシナリオでは、テーブルのスクリプトの説明を取得すると役立つ場合があるため、この動作は非常に悲しいです。 さて、システムビューを見て、テーブルオブジェクトを操作するためのOBJECT_DEFINITION関数の類似物を作成してください。
最初に、スクリプトを記述するプロセスがより視覚的になるようにテストテーブルを作成します。
IF OBJECT_ID('dbo.WorkOut', 'U') IS NOT NULL DROP TABLE dbo.WorkOut GO CREATE TABLE dbo.WorkOut ( WorkOutID BIGINT IDENTITY(1,1) NOT NULL, TimeSheetDate AS DATEADD(DAY, -(DAY(DateOut) - 1), DateOut), DateOut DATETIME NOT NULL, EmployeeID INT NOT NULL, IsMainWorkPlace BIT NOT NULL DEFAULT 1, DepartmentUID UNIQUEIDENTIFIER NOT NULL, WorkShiftCD NVARCHAR(10) NULL, WorkHours REAL NULL, AbsenceCode VARCHAR(25) NULL, PaymentType CHAR(2) NULL, CONSTRAINT PK_WorkOut PRIMARY KEY CLUSTERED (WorkOutID) ) GO
そして、最初のステップに進みます-列とそのプロパティのリストを取得します:
原則として、いくつかのシステムビューの1つにアクセスするだけで、列のリストを取得できます。 同時に、クエリの実行時間が最小限になるように、最も軽いシステム表現から選択することが重要です。
実装の計画とともに、いくつかの例を示します。
--#1 SELECT * FROM INFORMATION_SCHEMA.COLUMNS c WHERE c.TABLE_SCHEMA = 'dbo' AND c.TABLE_NAME = 'WorkOut'
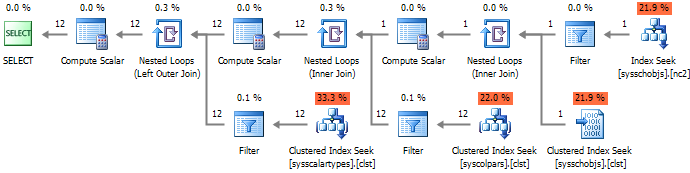
--#2 SELECT c.* FROM sys.columns c WITH(NOLOCK) JOIN sys.tables t WITH(NOLOCK) ON c.[object_id] = t.[object_id] JOIN sys.schemas s WITH(NOLOCK) ON t.[schema_id] = s.[schema_id] WHERE t.name = 'WorkOut' AND s.name = 'dbo'
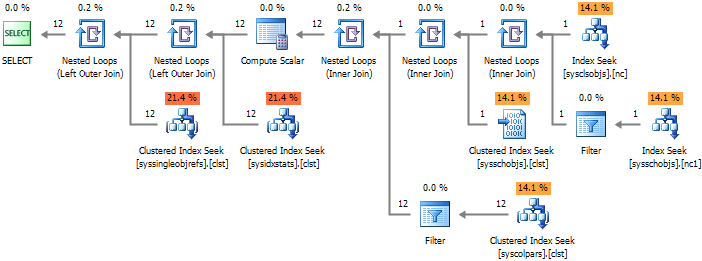
--#3 SELECT * FROM sys.columns c WITH(NOLOCK) WHERE OBJECT_NAME(c.[object_id]) = 'WorkOut' AND OBJECT_SCHEMA_NAME(c.[object_id]) = 'dbo'
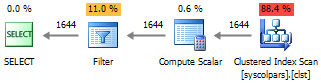
--#4 SELECT * FROM sys.columns c WITH(NOLOCK) WHERE c.[object_id] = OBJECT_ID('dbo.WorkOut', 'U')
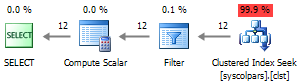
提示された実行計画から、オプション#1および#2にはクエリ実行時間を増加させる接続が過剰に含まれていることがわかりますが、#3のアプローチでは完全なインデックススキャンが行われ、すべての中で最も効率が低下します。
パフォーマンスの面では、#4オプションが最も魅力的です。
ただし、 sys.columns (およびINFORMATION_SCHEMA.COLUMNS )に含まれるデータは、テーブル構造を完全に説明するには不十分です。 これにより、他のシステムビューへの接続が強制されます。
SELECT c.name , [type_name] = tp.name , type_schema_name = s.name , c.max_length , c.[precision] , c.scale , c.collation_name , c.is_nullable , c.is_identity , ic.seed_value , ic.increment_value , computed_definition = cc.[definition] , default_definition = dc.[definition] FROM sys.columns c WITH(NOLOCK) JOIN sys.types tp WITH(NOLOCK) ON c.user_type_id = tp.user_type_id JOIN sys.schemas s WITH(NOLOCK) ON tp.[schema_id] = s.[schema_id] LEFT JOIN sys.computed_columns cc WITH(NOLOCK) ON c.[object_id] = cc.[object_id] AND c.column_id = cc.column_id LEFT JOIN sys.identity_columns ic WITH(NOLOCK) ON c.[object_id] = ic.[object_id] AND c.column_id = ic.column_id LEFT JOIN sys.default_constraints dc WITH(NOLOCK) ON dc.[object_id] = c.default_object_id WHERE c.[object_id] = OBJECT_ID('dbo.WorkOut', 'U')
したがって、実装計画は以前ほど明るく見えません。 注意を払うと、通常、列のリストを3回減算します。

sys.default_constraintsの中を見てください :
ALTER VIEW sys.default_constraints AS SELECT name, object_id, parent_object_id, ... object_definition(object_id) AS definition, is_system_named FROM sys.objects$ WHERE type = 'D ' AND parent_object_id > 0
システムビュー内では、デフォルトの定数の説明を取得するために、それぞれOBJECT_DEFINITIONの呼び出しを確認できます。接続する必要はありません。
Sys.computed_columnsは同じOBJECT_DEFINITIONを使用します 。
ALTER VIEW sys.computed_columns AS SELECT object_id = id, name = name, column_id = colid, system_type_id = xtype, user_type_id = utype, ... definition = object_definition(id, colid), ... FROM sys.syscolpars WHERE number = 0 AND (status & 16) = 16 -- CPM_COMPUTED AND has_access('CO', id) = 1
すでに2つの化合物を取り除いていることがわかりました。 sys.identity_columnsを使用すると、状況はさらに興味深いものになります。
ALTER VIEW sys.identity_columns AS SELECT object_id = id, name = name, column_id = colid, system_type_id = xtype, user_type_id = utype, ... seed_value = IdentityProperty(id, 'SeedValue'), increment_value = IdentityProperty(id, 'IncrementValue'), last_value = IdentityProperty(id, 'LastValue'), ... FROM sys.syscolpars WHERE number = 0 -- SOC_COLUMN AND (status & 4) = 4 -- CPM_IDENTCOL AND has_access('CO', id) = 1
IDENTITYPROPERTY文書化されていない関数は、 IDENTITYプロパティに関する情報を取得するために使用されます。 チェックの結果、 SQL Server 2005以降のバージョンでその変更されていない動作が確立されました。
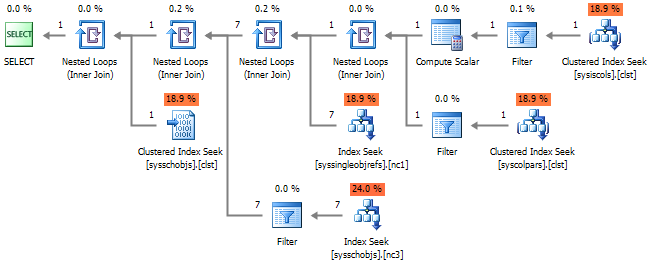
これらの関数を直接呼び出した結果、列のリストを取得する要求は著しく簡素化されました。
SELECT c.name , [type_name] = tp.name , type_schema_name = s.name , c.max_length , c.[precision] , c.scale , c.collation_name , c.is_nullable , c.is_identity , seed_value = CASE WHEN c.is_identity = 1 THEN IDENTITYPROPERTY(c.[object_id], 'SeedValue') END , increment_value = CASE WHEN c.is_identity = 1 THEN IDENTITYPROPERTY(c.[object_id], 'IncrementValue') END , computed_definition = OBJECT_DEFINITION(c.[object_id], c.column_id) , default_definition = OBJECT_DEFINITION(c.default_object_id) FROM sys.columns c WITH(NOLOCK) JOIN sys.types tp WITH(NOLOCK) ON c.user_type_id = tp.user_type_id JOIN sys.schemas s WITH(NOLOCK) ON tp.[schema_id] = s.[schema_id] WHERE c.[object_id] = OBJECT_ID('dbo.WorkOut', 'U')
そして、実装計画はより忠実になります。
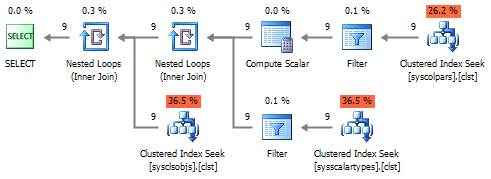
結論として、 sys.schemasに接続する代わりに、接続よりもはるかに高速に動作するシステム関数SCHEMA_NAMEを呼び出すことができます。 スキームの数がユーザーオブジェクトの数を超えない限り、このステートメントはtrueです。 そして、そのような状況はありそうもないので、無視することができます。
次に、主キーに含まれる列のリストを取得します。 最も明白なオプションはsys.key_constraintsを呼び出すことです :
SELECT pk_name = kc.name , column_name = c.name , ic.is_descending_key FROM sys.key_constraints kc WITH(NOLOCK) JOIN sys.index_columns ic WITH(NOLOCK) ON kc.parent_object_id = ic.object_id AND ic.index_id = kc.unique_index_id JOIN sys.columns c WITH(NOLOCK) ON ic.[object_id] = c.[object_id] AND ic.column_id = c.column_id WHERE kc.parent_object_id = OBJECT_ID('dbo.WorkOut', 'U') AND kc.[type] = 'PK'
理論を思い出すと、 PRIMARY KEYはクラスターインデックスおよび一意制約です。
メタデータレベルでは、 SQL Serverはすべてのクラスター化インデックスに対してindex_idを1に設定するため、 is_primary_key = 1でフィルター処理してsys.indexesから選択できます。
さらに、 sys.columnsとの接続を削除するには、システム関数COL_NAMEを使用できます。
SELECT pk_name = i.name , column_name = COL_NAME(ic.[object_id], ic.column_id) , ic.is_descending_key FROM sys.indexes i WITH(NOLOCK) JOIN sys.index_columns ic WITH(NOLOCK) ON i.[object_id] = ic.[object_id] AND i.index_id = ic.index_id WHERE i.is_primary_key = 1 AND i.[object_id] = object_id('dbo.WorkOut', 'U')

次に、取得したサンプルを1つに結合して、次のクエリを取得します。
DECLARE @object_name SYSNAME , @object_id INT , @SQL NVARCHAR(MAX) SELECT @object_name = '[' + OBJECT_SCHEMA_NAME(o.[object_id]) + '].[' + OBJECT_NAME([object_id]) + ']' , @object_id = [object_id] FROM (SELECT [object_id] = OBJECT_ID('dbo.WorkOut', 'U')) o SELECT @SQL = 'CREATE TABLE ' + @object_name + CHAR(13) + '(' + CHAR(13) + STUFF(( SELECT CHAR(13) + ' , [' + c.name + '] ' + CASE WHEN c.is_computed = 1 THEN 'AS ' + OBJECT_DEFINITION(c.[object_id], c.column_id) ELSE CASE WHEN c.system_type_id != c.user_type_id THEN '[' + SCHEMA_NAME(tp.[schema_id]) + '].[' + tp.name + ']' ELSE '[' + UPPER(tp.name) + ']' END + CASE WHEN tp.name IN ('varchar', 'char', 'varbinary', 'binary') THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length AS VARCHAR(5)) END + ')' WHEN tp.name IN ('nvarchar', 'nchar') THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length / 2 AS VARCHAR(5)) END + ')' WHEN tp.name IN ('datetime2', 'time2', 'datetimeoffset') THEN '(' + CAST(c.scale AS VARCHAR(5)) + ')' WHEN tp.name = 'decimal' THEN '(' + CAST(c.[precision] AS VARCHAR(5)) + ',' + CAST(c.scale AS VARCHAR(5)) + ')' ELSE '' END + CASE WHEN c.collation_name IS NOT NULL AND c.system_type_id = c.user_type_id THEN ' COLLATE ' + c.collation_name ELSE '' END + CASE WHEN c.is_nullable = 1 THEN ' NULL' ELSE ' NOT NULL' END + CASE WHEN c.default_object_id != 0 THEN ' CONSTRAINT [' + OBJECT_NAME(c.default_object_id) + ']' + ' DEFAULT ' + OBJECT_DEFINITION(c.default_object_id) ELSE '' END + CASE WHEN cc.[object_id] IS NOT NULL THEN ' CONSTRAINT [' + cc.name + '] CHECK ' + cc.[definition] ELSE '' END + CASE WHEN c.is_identity = 1 THEN ' IDENTITY(' + CAST(IDENTITYPROPERTY(c.[object_id], 'SeedValue') AS VARCHAR(5)) + ',' + CAST(IDENTITYPROPERTY(c.[object_id], 'IncrementValue') AS VARCHAR(5)) + ')' ELSE '' END END FROM sys.columns c WITH(NOLOCK) JOIN sys.types tp WITH(NOLOCK) ON c.user_type_id = tp.user_type_id LEFT JOIN sys.check_constraints cc WITH(NOLOCK) ON c.[object_id] = cc.parent_object_id AND cc.parent_column_id = c.column_id WHERE c.[object_id] = @object_id ORDER BY c.column_id FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 7, ' ') + ISNULL((SELECT ' , CONSTRAINT [' + i.name + '] PRIMARY KEY ' + CASE WHEN i.index_id = 1 THEN 'CLUSTERED' ELSE 'NONCLUSTERED' END +' (' + ( SELECT STUFF(CAST(( SELECT ', [' + COL_NAME(ic.[object_id], ic.column_id) + ']' + CASE WHEN ic.is_descending_key = 1 THEN ' DESC' ELSE '' END FROM sys.index_columns ic WITH(NOLOCK) WHERE i.[object_id] = ic.[object_id] AND i.index_id = ic.index_id FOR XML PATH(N''), TYPE) AS NVARCHAR(MAX)), 1, 2, '')) + ')' FROM sys.indexes i WITH(NOLOCK) WHERE i.[object_id] = @object_id AND i.is_primary_key = 1), '') + CHAR(13) + ');' PRINT @SQL
実行すると、テーブルに対して次のスクリプトが生成されます。
CREATE TABLE [dbo].[WorkOut] ( [WorkOutID] [BIGINT] NOT NULL IDENTITY(1,1) , [TimeSheetDate] AS (dateadd(day, -(datepart(day,[DateOut])-(1)),[DateOut])) , [DateOut] [DATETIME] NOT NULL , [EmployeeID] [INT] NOT NULL , [IsMainWorkPlace] [BIT] NOT NULL DEFAULT ((1)) , [DepartmentUID] [UNIQUEIDENTIFIER] NOT NULL , [WorkShiftCD] [NVARCHAR](10) COLLATE Cyrillic_General_CI_AI NULL , [WorkHours] [REAL] NULL , [AbsenceCode] [VARCHAR](25) COLLATE Cyrillic_General_CI_AI NULL , [PaymentType] [CHAR](2) COLLATE Cyrillic_General_CI_AI NULL , CONSTRAINT [PK_WorkOut] PRIMARY KEY CLUSTERED ([WorkOutID]) );
PS :テーブルのスクリプト記述の生成は、確かに列のリストと主キーに限定されません。 興味深い場合は、このトピックを続けて、インデックス、外部キー、およびその他の関連する構造の生成を表示できます。