今日、私たちはツールのメインで最大のグループであるイベントプロファイラーに精通します。
- 導入と理論 -なぜプロファイリング、異なるアプローチ、ツール、およびそれらの違いが必要なのですか?
- 手動および統計プロファイリング -実践に移りましょう
- イベントプロファイリング -ツールとそのアプリケーション
- デバッグ -何も機能しない場合の対処方法
トレーニングのタスク
前回の記事では、オイラープロジェクトの タスク3を分析しました。 変更のために、他の例をいくつか取り上げます。たとえば、同じタスクのコレクションからのタスク7です。
最初の6つの素数を書いたので、2、3、5、7、11、13になります。明らかに、6番目の素数は13です。
10001番目の素数は何ですか?
コードを書きます:
"""Project Euler problem 7 solve""" from __future__ import print_function import math import sys def is_prime(num): """Checks if num is prime number""" for i in range(2, int(math.sqrt(num)) + 1): if num % i == 0: return False return True def get_prime_numbers(count): """Get 'count' prime numbers""" prime_numbers = [2] next_number = 3 while len(prime_numbers) < count: if is_prime(next_number): prime_numbers.append(next_number) next_number += 1 return prime_numbers if __name__ == '__main__': try: count = int(sys.argv[1]) except (TypeError, ValueError, IndexError): sys.exit("Usage: euler_7.py number") if count < 1: sys.exit("Error: number must be greater than zero") prime_numbers = get_prime_numbers(count) print("Answer: %d" % prime_numbers[-1])
コードは完璧ではなく、多くのことをより簡単に、より良く、より速く行うことができます。 これがこの記事の目的です=)
前の記事で、私は恥ずかしくて、最も重要なことをしませんでした:テスト。 実際、リファクタリングまたは最適化中にプログラムを壊すことはこれまで以上に簡単であり、コードのプロファイリングとリライトの各サイクルは機能のテストを伴う必要があります(副作用はそのような副作用であるため、変更と他のすべての両方に直接影響します)。 それを修正して、プログラムにテストを追加してみましょう。 このような単純なスクリプトに最も簡単で最適なオプションは、 doctestモジュールを使用することです。 テストを追加して実行します。
テスト
"""Project Euler problem 7 solve""" from __future__ import print_function import math import sys def is_prime(num): """ Checks if num is prime number. >>> is_prime(2) True >>> is_prime(3) True >>> is_prime(4) False >>> is_prime(5) True >>> is_prime(41) True >>> is_prime(42) False >>> is_prime(43) True """ for i in range(2, int(math.sqrt(num)) + 1): if num % i == 0: return False return True def get_prime_numbers(count): """ Get 'count' prime numbers. >>> get_prime_numbers(1) [2] >>> get_prime_numbers(2) [2, 3] >>> get_prime_numbers(3) [2, 3, 5] >>> get_prime_numbers(6) [2, 3, 5, 7, 11, 13] >>> get_prime_numbers(9) [2, 3, 5, 7, 11, 13, 17, 19, 23] >>> get_prime_numbers(19) [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67] """ prime_numbers = [2] next_number = 3 while len(prime_numbers) < count: if is_prime(next_number): prime_numbers.append(next_number) next_number += 1 return prime_numbers if __name__ == '__main__': try: count = int(sys.argv[1]) except (TypeError, ValueError, IndexError): sys.exit("Usage: euler_7.py number") if count < 1: sys.exit("Error: number must be greater than zero") prime_numbers = get_prime_numbers(count) print("Answer: %d" % prime_numbers[-1])
テストと結果の実行
➜ python -m doctest -v euler_7.py Trying: get_prime_numbers(1) Expecting: [2] ok Trying: get_prime_numbers(2) Expecting: [2, 3] ok Trying: get_prime_numbers(3) Expecting: [2, 3, 5] ok Trying: get_prime_numbers(6) Expecting: [2, 3, 5, 7, 11, 13] ok Trying: get_prime_numbers(9) Expecting: [2, 3, 5, 7, 11, 13, 17, 19, 23] ok Trying: get_prime_numbers(19) Expecting: [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67] ok Trying: is_prime(2) Expecting: True ok Trying: is_prime(3) Expecting: True ok Trying: is_prime(4) Expecting: False ok Trying: is_prime(5) Expecting: True ok Trying: is_prime(41) Expecting: True ok Trying: is_prime(42) Expecting: False ok Trying: is_prime(43) Expecting: True ok 1 items had no tests: euler_7 2 items passed all tests: 6 tests in euler_7.get_prime_numbers 7 tests in euler_7.is_prime 13 tests in 3 items. 13 passed and 0 failed. Test passed.
コードを取得する速さを見てみましょう。
➜ python -m timeit -n 10 -s'import euler_7' 'euler_7.get_prime_numbers(10001)' 10 loops, best of 3: 1.27 sec per loop
はい、高速ではありません、最適化するものがあります=)
ツール
標準のPythonライブラリは、その多様性が際立っています。 開発者が必要とする可能性のあるものはすべて揃っているようで、プロファイラーも例外ではありません。 実際、「箱から出してすぐに」それらの3つがあります。
- cProfileは、Cで記述された比較的新しい(バージョン2.5以降)モジュールであるため、高速です
- profile-ネイティブプロファイラの実装(純粋なpythonで記述された)、遅い
- hotshot -Cの実験モジュール、非常に高速ですが、サポートされなくなり、いつでも標準ライブラリから削除できます
cProfile
標準のPythonモジュールの1つであるcProfileを説明せずに、Pythonプロファイリングについて語る
すべてのPythonプログラマーが少なくとも1回cProfileを実行しようとしたことがあると確信しています。
➜ python -m cProfile -s time euler_7.py 10001 428978 function calls in 1.552 seconds Ordered by: internal time ncalls tottime percall cumtime percall filename:lineno(function) 104741 0.955 0.000 1.361 0.000 euler_7.py:7(is_prime) 104741 0.367 0.000 0.367 0.000 {range} 1 0.162 0.162 1.550 1.550 euler_7.py:32(get_prime_numbers) 104741 0.039 0.000 0.039 0.000 {math.sqrt} 104742 0.024 0.000 0.024 0.000 {len} 10000 0.003 0.000 0.003 0.000 {method 'append' of 'list' objects} 1 0.001 0.001 1.552 1.552 euler_7.py:1(<module>) 1 0.000 0.000 0.000 0.000 {print} 1 0.000 0.000 0.000 0.000 __future__.py:48(<module>) 7 0.000 0.000 0.000 0.000 __future__.py:75(__init__) 1 0.000 0.000 0.000 0.000 __future__.py:74(_Feature) 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
プログラムの実行時間の違いにすぐに注意してください:プロファイラーなし:1.27秒、プロファイラーあり:1.55秒、つまり、特定のケースでは20%遅くなります。 そして、これは非常に良い結果です!
したがって、最長の(合計時間での)操作はis_prime関数であることがわかります。 プログラムは、この関数でほぼすべての時間を費やします。 次の「重大度」呼び出しは、is_prime関数から呼び出される範囲関数です。 ドキュメントを読んで、範囲が呼び出されると、指定された範囲のすべての数値を含むリストがメモリに作成されることを理解しています。 範囲関数が104741回呼び出され、範囲の上限が各呼び出しで増分されることを考慮して(数値を順番にソートします)、範囲関数によって作成されたリストの長さはプログラムの終わりまでに数十万アイテムに達し、リストは10万を超えて作成されると結論付けることができます回。 ドキュメントを読んだ後、このサイクルでxrange関数を使用する必要があることを学びます(Pythonの範囲はVS xrangeについて知っているので、注意深い読者はこの場所で皮肉を感じるはずです)。 範囲をxrangeに置き換えることの利点は、明らかにメモリを節約できることです(この理論は後で確認します)。 置き換えて、テストを実行します。すべてがOKで、プロファイラーを実行します
➜ python -m cProfile -s time euler_7.py 10001 324237 function calls in 1.010 seconds Ordered by: internal time ncalls tottime percall cumtime percall filename:lineno(function) 104741 0.825 0.000 0.857 0.000 euler_7.py:7(is_prime) 1 0.127 0.127 1.009 1.009 euler_7.py:32(get_prime_numbers) 104741 0.032 0.000 0.032 0.000 {math.sqrt} 104742 0.022 0.000 0.022 0.000 {len} 10000 0.003 0.000 0.003 0.000 {method 'append' of 'list' objects} 1 0.001 0.001 1.010 1.010 euler_7.py:1(<module>) 1 0.000 0.000 0.000 0.000 {print} 1 0.000 0.000 0.000 0.000 __future__.py:48(<module>) 7 0.000 0.000 0.000 0.000 __future__.py:75(__init__) 1 0.000 0.000 0.000 0.000 __future__.py:74(_Feature) 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1.552の代わりに1.010秒、つまり1.5倍高速です! わかった 現在、プログラムのボトルネックはis_prime関数そのものです。 他のツールを使用して、後で最適化します。
プロファイリング結果をコンソールに表示することは必ずしも便利ではありませんが、さらに分析するためにファイルに保存する方がはるかに便利です。 これを行うには、-oスイッチを使用します。
➜ python -m cProfile -o euler_7.prof euler_7.py 10001 ➜ ls euler_7.prof euler_7.py
または、最も単純なデコレータを使用できます。
import cProfile def profile(func): """Decorator for run function profile""" def wrapper(*args, **kwargs): profile_filename = func.__name__ + '.prof' profiler = cProfile.Profile() result = profiler.runcall(func, *args, **kwargs) profiler.dump_stats(profile_filename) return result return wrapper @profile def get_prime_numbers(count): ...
そして、foo関数を呼び出すたびに、プロファイル結果のファイルが保存されます(この例では「get_prime_numbers.prof」)。
ホットショット
hotshot-別の標準Pythonモジュールは現在サポートされておらず、標準ライブラリからいつでも削除できます。 しかし、プロファイラの下でプログラムを起動するときは非常に高速でオーバーヘッドが最小限であるため、それが使用されていれば使用できます。 使い方はとても簡単です。
import hotshot prof = hotshot.Profile("profile_name.prof") prof.start() # your code goes here prof.stop() prof.close()
またはデコレーターとして:
import hotshot def profile(func): """Decorator for run function profile""" def wrapper(*args, **kwargs): profile_filename = func.__name__ + '.prof' profiler = hotshot.Profile(profile_filename) profiler.start() result = func(*args, **kwargs) profiler.stop() profiler.close() return result return wrapper @profile def get_prime_numbers(count): ...
プロファイリング分析
プログラムの起動直後にプロファイリングの結果を画面に表示することが判明することはまれです。 はい、そのような結果にはほとんど意味がありません。最も単純なスクリプトのみを学習できます。 データを表示および分析するには、Pythonに組み込まれたpstatsモジュールを使用することをお勧めします(素晴らしいiPythonコンソールと組み合わせて使用すると便利です)。
➜ ipython In [1]: import pstats In [2]: p = pstats.Stats('get_prime_numbers.prof') In [3]: p.sort_stats('calls').print_stats() 324226 function calls in 1.018 seconds Ordered by: call count ncalls tottime percall cumtime percall filename:lineno(function) 104742 0.023 0.000 0.023 0.000 {len} 104741 0.821 0.000 0.854 0.000 euler_7.py:19(is_prime) 104741 0.034 0.000 0.034 0.000 {math.sqrt} 10000 0.003 0.000 0.003 0.000 {method 'append' of 'list' objects} 1 0.138 0.138 1.018 1.018 euler_7.py:44(get_prime_numbers)
もちろん、コンソールは良いことですが、あまり視覚的ではありません。 特に困難な状況では、数百および数千の課題を持つプログラムでは、結果の分析は困難です。 人々は、テキスト情報よりも(コンピューターとは異なり)グラフィック情報を知覚する方がはるかに簡単になるように配置されています。 プロファイリング結果を分析するためのさまざまなツールが役立ちます。
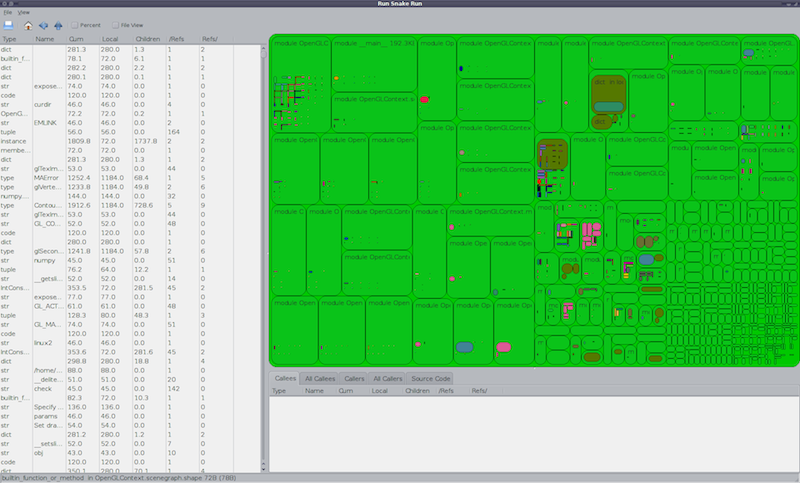
kcachegrind
おそらく、実際にはCallgrindユーティリティの結果を視覚化することを目的とするkcachegrindのような有名なツールから始めますが、Pythonプロファイラーの結果を変換することで、それらをkcachegrindで開くことができます。 変換は、 pyprof2calltreeユーティリティを使用して実行されます。
➜ pip install pyprof2calltree ➜ pyprof2calltree -i profile_results.prof -o profile_results.kgrind
ファイルに保存せずに、kcachegrindで結果をすぐに開くことができます。
➜ pyprof2calltree -i profile_results.prof -k
プログラムを使用すると、特定の呼び出しにかかった時間と、その中のすべての呼び出しを視覚的に確認できます。 また、コールツリーやその他の有用な情報を見ることができます。 インターフェイスは次のようになります。

RunSnakeRun
RunSnakeRunのプロファイリング結果を視覚化する別のプログラムは、元々pythonプロファイラーで動作するように作成されました(これはその名前からわかります)。 これはkcachegrindに似ていますが、著者が言うように、よりシンプルなインターフェイスと機能と比較して好意的です。 インストールは問題を引き起こしません:
➜ brew install wxwidgets ➜ pip install SquareMap RunSnakeRun
使用法も:
➜ runsnake profile_results.prof
同様に、正方形のマップが表示されます。正方形の面積が大きいほど、対応する関数が完了するまでに時間がかかりました。
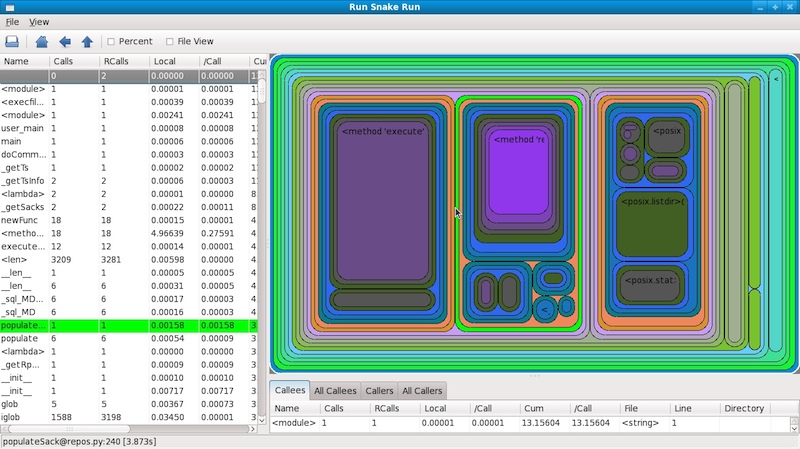
RunSnakeRunでは、Meliaeユーティリティを使用して、メモリ消費のプロファイリングの結果を視覚化することもできます。
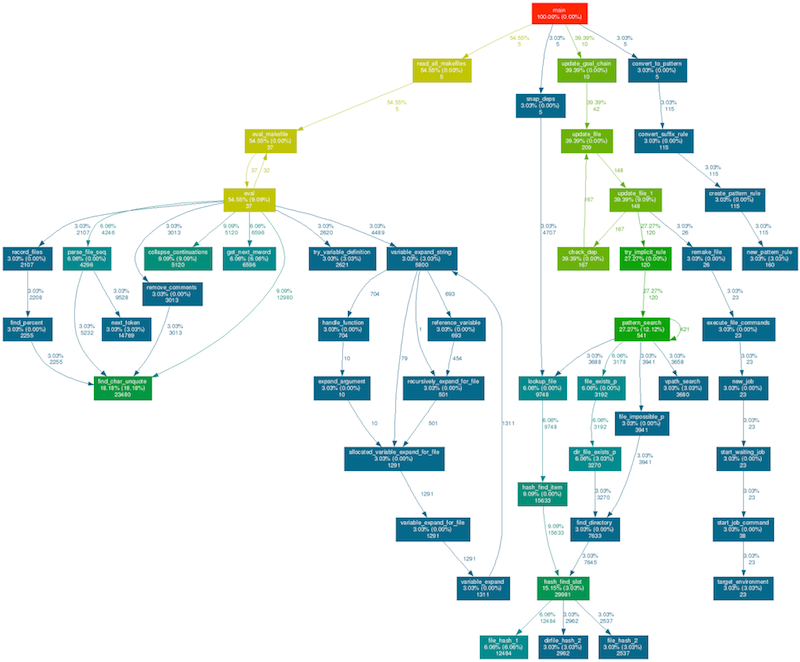
gprof2dot
gprof2dotユーティリティは、関数呼び出しのツリーとその実行時間に関する情報を含む画像を生成します。 ほとんどの場合、これはプログラムのボトルネックを見つけるのに十分です。 画像を設定および生成します。
➜ brew install graphviz ➜ pip install gprof2dot ➜ gprof2dot -f pstats profile_results.prof | dot -Tpng -o profile_results.png
結果:
ジャンゴプロファイリング
Djangoのプロファイリングには、 django-extensionsモジュールを使用すると便利です。django -extensionsモジュールには、さまざまな便利な機能に加えて、便利なrunprofileserverコマンドがあります。 使い方は簡単です。 私たちは置きます:
➜ pip install django-extensions
アプリケーションをsettings.pyに追加します。
INSTALLED_APPS += ('django_extensions',)
以下を開始します。
➜ python manage.py runprofileserver --use-cprofile --prof-path=/tmp/prof/
/ tmp / prof /ディレクトリに、アプリケーションへの各リクエストのプロファイリング結果を含むファイルが作成されます。
➜ ls /tmp/prof/ admin.000276ms.1374075009.prof admin.account.user.000278ms.1374075014.prof admin.jsi18n.000185ms.1374075018.prof favicon.ico.000017ms.1374075001.prof root.000073ms.1374075004.prof static.admin.css.base.css.000011ms.1374075010.prof static.admin.css.forms.css.000013ms.1374075017.prof static.admin.img.icon-yes.gif.000001ms.1374075015.prof static.admin.img.sorting-icons.gif.000001ms.1374075015.prof static.admin.js.core.js.000018ms.1374075014.prof static.admin.js.jquery.js.000003ms.1374075014.prof static.css.bootstrap-2.3.2.min.css.000061ms.1374074996.prof static.img.glyphicons-halflings.png.000001ms.1374075005.prof static.js.bootstrap-2.3.2.min.js.000004ms.1374074996.prof static.js.jquery-2.0.2.min.js.000001ms.1374074996.prof user.login.000187ms.1374075001.prof
上記のツールのいずれかを使用して、さらに分析を実行できます:pstats、kcachegrind、RunSnakeRunまたはgprof2dot。 または他の=)
Pythonに組み込まれているプロファイラーに加えて、シンプルで複雑な、便利であまり役に立たない大量のサードパーティプログラムもあります。
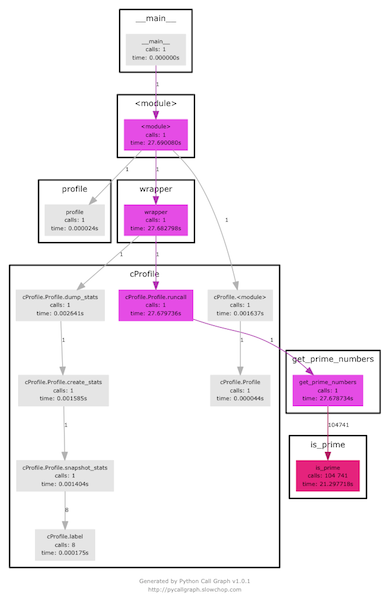
パイコールグラフ
pycallgraphを使用すると、Pythonプログラムの呼び出しツリーを構築できます 。 私たちは置きます:
➜ brew install graphviz ➜ pip install pycallgraph
開始して結果を確認します。
➜ pycallgraph graphviz -- euler_7.py 10001 ➜ open pycallgraph.png
line_profiler
line_profilerは、その名前が示すように、コードの必要なセクションの行ごとのプロファイリングを許可します。 私たちは置きます:
➜ pip install line_profiler
「プロファイル」デコレータを適切な場所に追加します(結果をよりコンパクトに出力するために一時的にドックストリングを削除しました)
@profile def is_prime(num): for i in xrange(2, int(math.sqrt(num)) + 1): if num % i == 0: return False return True @profile def get_prime_numbers(count): prime_numbers = [2] next_number = 3 while len(prime_numbers) < count: if is_prime(next_number): prime_numbers.append(next_number) next_number += 1 return prime_numbers
プロファイリングを開始します。
➜ kernprof.py -v -l euler_7.py 10001 Wrote profile results to euler_7.py.lprof Timer unit: 1e-06 s File: euler_7.py Function: is_prime at line 7 Total time: 10.7963 s Line # Hits Time Per Hit % Time Line Contents ============================================================== 7 @profile 8 def is_prime(num): 9 2935963 5187211 1.8 48.0 for i in xrange(2, int(math.sqrt(num)) + 1): 10 2925963 5421919 1.9 50.2 if num % i == 0: 11 94741 169309 1.8 1.6 return False 12 10000 17904 1.8 0.2 return True File: euler_7.py Function: get_prime_numbers at line 15 Total time: 23.263 s Line # Hits Time Per Hit % Time Line Contents ============================================================== 15 @profile 16 def get_prime_numbers(count): 17 1 5 5.0 0.0 prime_numbers = [2] 18 1 3 3.0 0.0 next_number = 3 19 20 104742 208985 2.0 0.9 while len(prime_numbers) < count: 21 104741 22843717 218.1 98.2 if is_prime(next_number): 22 10000 22405 2.2 0.1 prime_numbers.append(next_number) 23 104741 187927 1.8 0.8 next_number += 1 24 25 1 2 2.0 0.0 return prime_numbers
プロファイラがなければ、1秒よりも速く動作するという事実にもかかわらず、プログラムは30秒以上実行されました。
結果を分析すると、プログラムは9行目と10行目で最大の時間を費やし、数の約数をチェックしてその「単純さ」を判断していると結論付けることができます。 そして、後続の各番号について、すべて同じチェックが行われます。 プログラムの論理的な最適化は、以前に単純として定義された数値のみを除数としてチェックすることです。
def is_prime(num, prime_numbers): """ Checks if num is prime number. >>> is_prime(2, []) True >>> is_prime(3, [2]) True >>> is_prime(4, [2, 3]) False >>> is_prime(5, [2, 3]) True >>> is_prime(41, [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]) True >>> is_prime(42, [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41]) False >>> is_prime(43, [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41]) True """ limit = int(math.sqrt(num)) + 1 for i in prime_numbers: if i > limit: break if num % i == 0: return False return True def get_prime_numbers(count): """ Get 'count' prime numbers. >>> get_prime_numbers(1) [2] >>> get_prime_numbers(2) [2, 3] >>> get_prime_numbers(3) [2, 3, 5] >>> get_prime_numbers(6) [2, 3, 5, 7, 11, 13] >>> get_prime_numbers(9) [2, 3, 5, 7, 11, 13, 17, 19, 23] >>> get_prime_numbers(19) [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67] """ prime_numbers = [2] next_number = 3 while len(prime_numbers) < count: if is_prime(next_number, prime_numbers): prime_numbers.append(next_number) next_number += 1 return prime_numbers
テストを実行し、すべてが正しく機能することを確認し、プログラムの実行時間を測定します。
➜ python -m timeit -n 10 -s'import euler_7' 'euler_7.get_prime_numbers(10001)' 10 loops, best of 3: 390 msec per loop
彼らは仕事をほぼ3回加速しましたが、悪くはありませんでした。 プロファイリングをもう一度実行します。
➜ kernprof.py -v -l euler_7.py 10001 Wrote profile results to euler_7.py.lprof Timer unit: 1e-06 s File: euler_7.py Function: is_prime at line 7 Total time: 4.54317 s Line # Hits Time Per Hit % Time Line Contents ============================================================== 7 @profile 8 def is_prime(num, prime_numbers): 9 104741 310160 3.0 6.8 limit = int(math.sqrt(num)) + 1 10 800694 1296045 1.6 28.5 for i in prime_numbers: 11 800692 1327770 1.7 29.2 if i > limit: 12 9998 17109 1.7 0.4 break 13 790694 1409731 1.8 31.0 if num % i == 0: 14 94741 165761 1.7 3.6 return False 15 10000 16599 1.7 0.4 return True File: euler_7.py Function: get_prime_numbers at line 18 Total time: 10.5464 s Line # Hits Time Per Hit % Time Line Contents ============================================================== 18 @profile 19 def get_prime_numbers(count): 20 1 4 4.0 0.0 prime_numbers = [2] 21 1 2 2.0 0.0 next_number = 3 22 23 104742 202443 1.9 1.9 while len(prime_numbers) < count: 24 104741 10143489 96.8 96.2 if is_prime(next_number, prime_numbers): 25 10000 22374 2.2 0.2 prime_numbers.append(next_number) 26 104741 178074 1.7 1.7 next_number += 1 27 28 1 1 1.0 0.0 return prime_numbers
ご覧のとおり、プログラムははるかに高速に実行され始めました。
memory_profiler
memory_profilerを使用して、メモリのプロファイルを作成できます。 これの使用は、line_profilerと同じくらい簡単です。 私たちは置きます:
➜ pip install psutil memory_profiler
以下を開始します。
➜ python -m memory_profiler euler_7.py 10001 Filename: euler_7.py Line # Mem usage Increment Line Contents ================================================ 18 8.441 MiB -0.531 MiB @profile 19 def get_prime_numbers(count): 20 8.445 MiB 0.004 MiB prime_numbers = [2] 21 8.445 MiB 0.000 MiB next_number = 3 22 23 8.973 MiB 0.527 MiB while len(prime_numbers) < count: 24 if is_prime(next_number, prime_numbers): 25 8.973 MiB 0.000 MiB prime_numbers.append(next_number) 26 8.973 MiB 0.000 MiB next_number += 1 27 28 8.973 MiB 0.000 MiB return prime_numbers Filename: euler_7.py Line # Mem usage Increment Line Contents ================================================ 7 8.973 MiB 0.000 MiB @profile 8 def is_prime(num, prime_numbers): 9 8.973 MiB 0.000 MiB limit = int(math.sqrt(num)) + 1 10 8.973 MiB 0.000 MiB for i in prime_numbers: 11 8.973 MiB 0.000 MiB if i > limit: 12 8.973 MiB 0.000 MiB break 13 8.973 MiB 0.000 MiB if num % i == 0: 14 8.973 MiB 0.000 MiB return False 15 8.973 MiB 0.000 MiB return True
ご覧のとおり、メモリに特別な問題はありません。 すべてが通常の制限内です。
その他のツール
残念ながら、プロファイリング用のツールをさらにいくつかリストしますが、残念なことに、この記事は巨大であり、すべてを解析することはできません。
- Dowser-優れたメモリプロファイリングツール
- グッピーは別のメモリプロファイリングプログラムです
- Meliaeは、前述のメモリプロファイリングツールで、RunSnakeRunで使用できます。
- muppy-メモリリーク検出
- memprof-メモリプロファイリングを再度
- objgraphはオブジェクトを探索するための興味深いツールです
Pythonコードプロファイリングツールを導入しました。 それらの多くが舞台裏に残ったので、コメントで私の同僚が私を補完することを願っています。
次の記事では、Pythonプログラムをデバッグするためのメソッドとツールを紹介します。 連絡を取り合いましょう!
統計の瞬間:pythonプロファイリングに関する3つの記事で、「プロファイリング」という言葉を100回以上使用しました。