注:後で判明したrmqユーザーの記事には、このエラーは含まれていません。 そこでどのように解決されるかを以下に説明します。 そして彼に感謝します。もし彼の話題がなかったら、私は自分で書いてなかったでしょうし、招待を受けなかったでしょう!
開始する前に、ターゲットオーディエンスについて一言:おそらく、Aho-Korasikアルゴリズムに長い間精通している人は、その機能に長い間気付いていたので、私の記事に興味がないでしょう。 少なくとも、このアルゴリズムを使用している私の馴染みのあるプログラマーはすべて、その誤った解釈の存在を直接知っています。 しかし、初心者や実際に頻繁に使用することができなかった人にとっては、この記事は非常に役立ちます。
それでは始めましょう。
読者の時間を無駄にしないために、アルゴリズムの詳細な説明を見逃し(これは元の記事で読むことができます)、すぐに用語を読み、「1つの言語で」さらに話すために、例と写真から始めます。
次のサンプル文字列のリストを探してみましょう:{"HE"、 "SHE"、 "HIS"、 "HER"}。 まず、オートマトンを作成する必要があります。 Aho-Korasikアルゴリズムの構築に基づいて、状態と遷移を備えた非常に有限な状態マシン。 黒い円は、オートマトンの初期状態を示しています。 青い丸はオートマトンの次の状態を示しますが、その達成はサンプル文字列の検出の事実を意味しません。 そして最後に、十字線の付いた青い円-これはマシンの次の状態であり、その達成はラインパターンを検出するという事実を意味します。 当然、トランジションはそれらの間で広がります-黒い矢印が文字で署名されており、これがトランジションの条件です。 それらをメイン遷移と呼びます。 次の入力シンボルのメイン遷移がない場合、マシンは初期状態になります。 それらをゼロ遷移と呼びます。 写真が乱雑にならないように、これらの移行を具体的に示していません。 ゼロトランジションについては、クリックしたときに入力シンボルが吸収されない、つまり、入力ラインに残り、トランジション後に再び使用されることに注意してください。 例外は初期状態からのゼロ遷移であり、実際には状態は変化せず、入力シンボルは吸収されます。
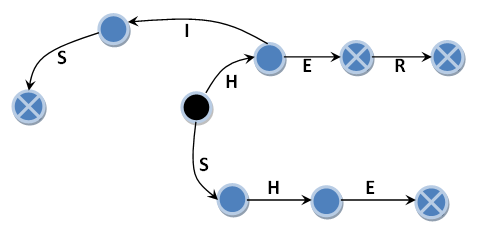
この図は、十字線の付いた4つの青い円を示しており、それぞれがサンプルの線の1つに対応しています。 実際、この例にはすでにこのエラーが内在しています。 元のアルゴリズムは、オートマトンを少し異なる方法で説明します。 しかし、まず最初に。
いわゆるサフィックスリンクを思い出してください。 これらは、入力行の次の文字に主な遷移がない場合に切り替える状態を示す遷移です。 次の図では、それらは点線の黒い矢印で示されています。 それらを接尾辞遷移または接尾辞リンクと呼びます。 ヌル遷移との類推による接尾辞リンクの通過は、入力文字を吸収しません。 最初のケースのように、メイン遷移がない場合に初期状態に至る遷移を示していません。
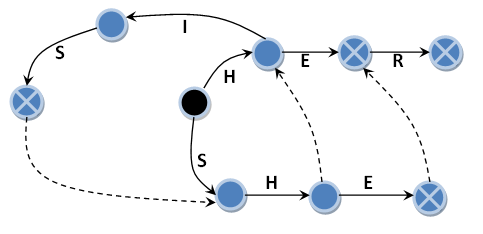
接尾辞リンクはないが、遷移がゼロの例では、すべての出現(「HE」、「HER」、「HE」、「HIS」)は「HERHEHIS」行にあります。 ただし、入力文字列「HISHER」では3つのエントリ(「HIS」、「HE」、「HER」)のみが検出され、マシンはパターン文字列「SHE」の発生を検出しないため、確認が容易です。 文字列「HERHEHIS」のサフィックスリンクの場合、結果は同じになり、文字列「HISHER」の場合、結果は4つの見つかったエントリのリストになります(「HIS」、「SHE」、「HE」、「HER」)。 つまり、後者の場合、すべての発生が見つかりました。 いいえ、いいえ、これは私が話したかった間違いではありません。 決してそうは思わない。 誰かが接尾辞リンクを忘れるのは、これを見たことがない。 まだ来ています。
オートマトンを構築するためのアルゴリズムの詳細については説明しませんでしたが、上記のケースの検索アルゴリズムをより詳細に検討します。 これを行うために、便宜上、最初に接尾辞リンクのないオートマトンを提供します。このオートマトンでは、状態(対応する円の近くの青い数字)に番号を付けます。
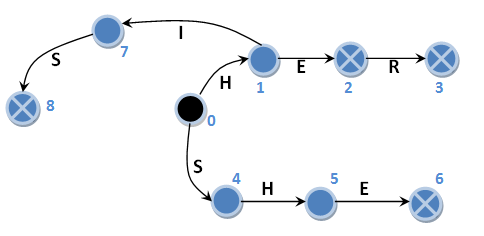
はい、ちなみに、サフィックスリンクがないにもかかわらず、このマシンは入力シンボルを保持しながら、主方向がないときに初期状態になります。 これらの遷移は図には示されていません。 始めましょう。 初期状態0、入力文字列「HERHEHIS」:
0 H -> 1 ERHEHIS 1 E -> 2 RHEHIS (“HE”) 2 R -> 3 HEHIS (“HER”) 3 H -> 0 HEHIS // , 0 H -> 1 EHIS 1 E -> 2 HIS (“HE”) 2 H -> 0 HIS // 0 H -> 1 IS 1 I -> 7 S 7 S -> 8 (“HIS”)
ここにあります-4つの出現すべて。 「HISHER」行でも同じことをしましょう。
0 H -> 1 ISHER 1 I -> 7 SHER 7 S -> 8 HER (“HIS”) 8 H -> 0 HER 0 H -> 1 ER 1 E -> 2 R (“HE”) 2 R -> 3 (“HER”)
予想どおり、3つのオカレンスのみが見つかりました。 これで、例の本質を掘り下げ、次のステートメントを定式化できます。「重複するサンプル文字列を含む入力文字列のサフィックスリンクがないマシンでは、すべてのオカレンスが検出されるわけではありません。」 私たちは、オーバーラップ(「ヒッシュ」の「HIS」と「SHE」)について話しているが、お互いに入ることはない(「HER」の「HE」と「HER」)。
もちろん、接尾辞リンクがあるマシンでは、これは起こりません。 同じ例を確認しましょう。 オートマトンの状態にサフィックスリンクを付けて番号を付けます。
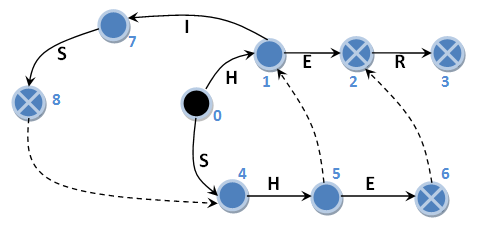
入力文字列「HERHEHIS」を取得します。
0 H -> 1 ERHEHIS 1 E -> 2 RHEHIS (“HE”) 2 R -> 3 HEHIS (“HER”) 3 H -> 0 HEHIS // 0 H -> 1 EHIS 1 E -> 2 HIS (“HE”) 2 H -> 0 HIS // 0 H -> 1 IS 1 I -> 7 S 7 S -> 8 (“HIS”)
この入力行では、マシンの進行状況は、サフィックスリンクのないマシンの進行状況とまったく同じです。 次に、「HISHER」という行をマシンにスリップします。
0 H -> 1 ISHER 1 I -> 7 SHER 7 S -> 8 HER (“HIS”) 8 H -> 4 HER // 4 H -> 5 ER 5 E -> 6 R (“SHE”) 6 R -> 2 R (“HE”) // 2 R -> 3 (“HER”)
確かに、4つの発生すべてが発見されました。 ここで何を定式化できるか:「接尾辞リンクなしでは、サンプル文字列のすべての出現を見つける希望はゼロになる傾向があります。」
多くの場合、Aho-Korasikアルゴリズムの説明に出くわしました。 ツリーを構築するためのアルゴリズムは詳細に記述されており、検索アルゴリズムについても記述されています。「基本的なことです。状態を調べて結果を出します」。 そして、これらの作品の作者は、彼らが間違っていなければ絶対に正しいでしょう。 まず、接尾辞リンクを持つオートマトンでさえ処理できない例を示します。 同様のオートマトンを構築しますが、2つの追加のサンプル文字列「I」と「IS」を導入します。 概略的に、そのようなオートマトンとメインおよびサフィックスの遷移は、次のように表すことができます。
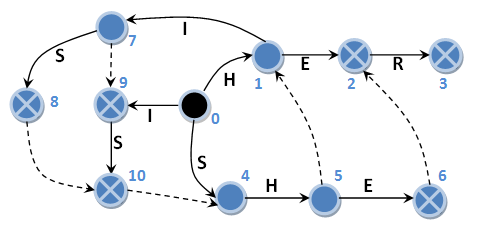
入力行として、私たちが知っているすべての同じ「ヒッシャー」を使用します。 それでは、行きましょう:
0 H -> 1 ISHER 1 I -> 7 SHER 7 S -> 8 HER (“HIS”) 8 H -> 10 HER (“IS”) 10 H -> 4 HER 4 H -> 5 ER 5 E -> 6 R (“SHE”) 6 R -> 2 R (“HE”) 2 R -> 3 (“HER”)
合計で、5つのオカレンスが見つかりました。 しかし、それらの中にはパターン文字列「I」はありません。 問題は何ですか? どうして起こったの? 実際、すべてが基本です。 接尾辞のリンクをたどると、状態7と0からしかアクセスできない状態9が渡されました。したがって、部分文字列「HIS」があるところはどこでも、サンプル文字列「I」は見つかりません。 同様に、入力行「HISHER」では、サンプル文字列「H」を一度だけ検索します。これは以前にリストに追加し、対応するオートマトンを作成しました。 そして、ここでのポイントは、行「I」と「H」が1文字で構成されているということではありません。 自分で確認してください:リストの「HIS」を「HIPS」に、「IS」を「IPS」に、「I」を「IP」に置き換え、入力ライン「HIPSHER」をマシンに送ります。 同じ理由で、パターン文字列「IP」は見つかりません。 それで、何が間違っていたのか:オートマトンの構造または検索アルゴリズム?
この問題を解決するためのオプションには、明らかなお気に入りが1つあります。 同様の例に直面し、その理由を整理するために、開発者は最も明白な正面ソリューションを選択します。「接尾辞リンクをクリックした後、初期状態への主要な遷移に戻ります」。 確かに、これは問題から私たちを救います、そしてそのような実装は生命に対する権利を持っています。 ここで注意できるのは2つだけです。
- アルゴリズムの複雑さ(時間コスト)の評価は悪化しています。
- 本当に問題はありませんでした。
上記のrmqユーザーの記事では、別のソリューションを使用しています。メイントランジションではなく、初期状態へのサフィックスリンクによって、「適切なサフィックスリンク」、つまり固定パターン文字列の状態につながるリンクによってのみ実行します。 このようなアプローチは、「ファフォリティック」ソリューションよりも桁違いに優れていますが、それでも状態に対して余分な実行を強制します。 それにもかかわらず、実際の実装では、このアルゴリズムは元のアルゴリズムと同時に動作します。 興味深い解決策をありがとうrmq 。
元のアルゴリズムに戻りましょう。 元の記事に精通している人、または少なくとも正しい翻訳に精通している人にとっては、最初のマシンでエラーを見つけることができます。 特定の状態について、(初期状態から)完全に見つかったパターン文字列だけでなく、パターン文字列でもあるすべての接尾辞も検出したという事実を記録すると、すべてが正しく機能します。
いくつかの変更を加えた最後のオートマトンの図をもう一度示します。
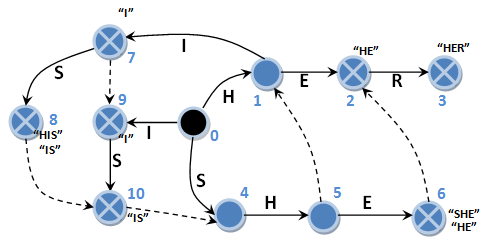
状態6に到達すると、「SHE」と「HE」の発生を修正します。 サフィックスリンクをたどった後ではなく、状態6にあります。 同様に、状態7はパターン文字列「I」の出現を記録し、状態8は「HIS」と「IS」を記録します。 この場合、検索アルゴリズムは、接尾辞リンクをたどった後にエントリの固定を削除する必要があります。そうしないと、同じエントリが2回修正されます。 たとえば、6番目の状態から2番目の状態に遷移した後、「HE」の発生を修正する必要はありません。5番目の状態から6番目の状態に遷移した後、これを以前に行いました。 これで、初期状態に戻る必要はありません。 検索は本当にシンプルで簡単です。 入力文字列「HISHER」の解析は、次のようになります。
0 H -> 1 ISHER 1 I -> 7 SHER (“I”) 7 S -> 8 HER (“HIS”, “IS”) 8 H -> 10 HER 10 H -> 4 HER 4 H -> 5 ER 5 E -> 6 R (“SHE”, “HE”) 6 R -> 2 R 2 R -> 3 (“HER”)
これで、6つの出現すべてが検出されました。 これによりオートマトンの構築が複雑になると思われるかもしれませんが、そうではありません。 前の例ほど複雑ではありません。 オートマトンを構築するためのアルゴリズムを最初から説明しなかったため、ここでは説明しません。 アルフレッド・アホとマーガレット・コラシクによるオリジナルの記事で美しく説明されています。おそらく誰かが読むべきでしょう。
結論として、元のソースからではない何かを読んでいる人に、その不正確さの可能性に気付くようアドバイスしたいと思います。 そして、可能であれば、実装で別の間違いを犯す前に真実を理解してください。 そして、「適応した」声明を書く人のために、他の人を誤解させることなく、あなたの仕事をより責任を持って受け入れてください。