
こんにちは、Habr!
これは、ページ上のコンテンツを強調表示するなどの問題を解決するためのベストプラクティスを共有したい最初の投稿です。 実際、パズルは長いこと頭の中で背景にぶら下がっています。 しかし、たまたまハブを使った記事habrahabr.ru/company/mailru/blog/200394に出くわしたので、今は自分でツールを必要としていたのです。 さあ、行きましょう。
思考の列車
実際、なぜ記事の冒頭にそのような写真があるのですか? 実際のところ、問題はまったく異なる方法で解決できます。 考えられる解決策、それらの長所と短所については長々と議論しません。 主なことは、この投稿では分類問題としてタスクにアプローチすることです。 だから、ここに思考の列があります:
- DOMの任意の要素をベクトル化できるように、一連の要因を考え出します。
- どういうわけか、ドキュメントのバンドルを収集しています。
- 各ドキュメントでは、ツリーのBODYの下にあるDOMのすべての要素をベクトル化します。 なんとなく再び。
- ベクトル化された要素ごとに、1または0のクラスを割り当てます。0はターゲットではなく、1はターゲットです。
- サンプルを50/50程度の割合で2つに分けます。
- 分類器を片方で訓練し、もう片方でそれをテストし、完全性、正確性という形で結果を取得します。 まあ、またはそれらのFスコアのようなメトリック。
賢明な読者は、最後の2つのポイントの代わりに、たとえば相互検証などを行う方が適切であり、正しいと言うでしょう。 一般に、この場合、これは重要ではありません。 この記事は、主にツールに専念するものであり、関連する数学的/アルゴリズムの詳細についてではありません。
物事のイデオロギー的な側面については、すべてが明確に思えます。 技術面を見てみましょう。
- 言語としてpythonを選択しました。 私はそれが好きだから(:
- Sklearnはすぐに学習用の数学ライブラリとして選択されました。
-
何らかの理由でJavaScriptページも正常に処理する必要があると判断したため、解析のエンジンとしてPyQt4が選択されました。 結局のところ、これは非常に良い選択です。
解決策
いつものように、アイデアはあらゆる種類の不快な「ささいなこと」を考慮していないことが判明しました。 しかし、実際には、前の段落ではすべてが素晴らしいように聞こえますが、サンプルをマークする方法は完全に明確ではありませんか? つまり さらなるトレーニングのためにDOMのターゲット要素を選択する方法は? そして、正しい考えが頭に浮かんだ。それをインタラクティブなブラウザにしよう。 マウスとキーボードを使用してターゲットブロックを選択します。 ブラウザを離れることなく視覚化された一種のマークアッププロセス。
次のように考えられていました:マウスで運転できるブラウザがあり、マウスの下の要素が「強調表示」されています。 目的の項目が選択されたら、ユーザーは特定のホットキーをクリックします。 その結果、ページが解析され、DOMがベクトル化され、選択された要素はクラス1を取得し、残りはクラス0を取得します。
結果
ここのコードからフットクロスをコピーしたくありません-すべてが明確でリポジトリにあります 。 それが必要な人に-そこを読んでください。 はい、 pipを使用して怠inessを設定できますが、Ubuntu> = 12.04でのみ書き込みとテストを行ってください。
その結果、3つの主要な機能を備えたライブラリができました。
- ブラウザでコンテンツを認識するためのインタラクティブな学習。 結果の分類子モデルはファイルにシリアル化されます。
- ブラウザ内のコンテンツの認識のインタラクティブなテスト。 ページでターゲットとして分類された要素が強調表示されます。
- 特定のURLおよびモデルファイルでターゲットDOM要素のhtmlを切り取ることができるコンソールツール。
ちなみに、constructorバッグをインストールすると、2つのスクリプトを起動できるようになります。
- constractor_train.pyは、インタラクティブなチュートリアル/テストです。 タルサは、マウスポインターの下の要素を強調表示し、ホットキーを押してページをベクトル化し、さまざまなページから受信したデータから学習し、ファクターとモデルをファイルに保存し、ファイルからそれらをロードし、現在のモデルに基づいて要素を強調表示します。
- constractor_predict.pyは、ターゲット要素のコンソールHTMLリッピングです。 一般に、これはtulzaが知っているすべてです(:
写真
非常に怠け者のために、私は写真で例を挙げます。 たとえば、Habrの上限を決定するためにtulzaを教える必要があります。
1)ヘッダーにマウスを向けます。 目的の領域が強調表示されたら(黒い背景)、Ctrl + Sを押します。 したがって、ベクトル化された要素を選択に追加しました。
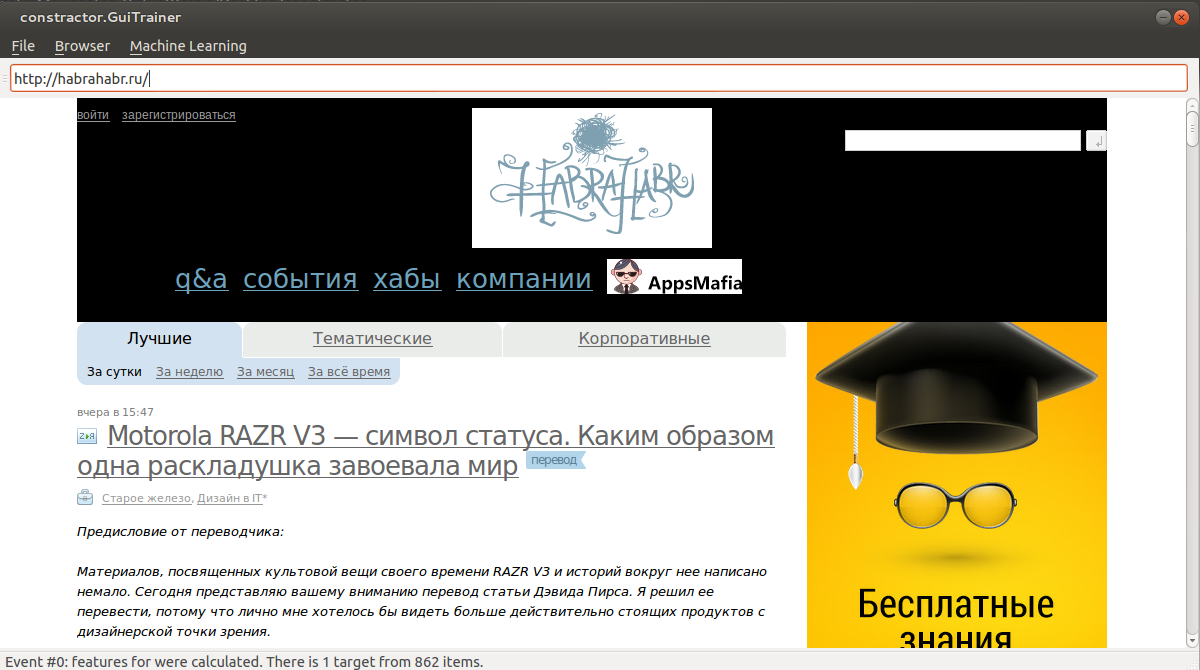
手順を数回繰り返します。

2)次に、Ctrl + Tを押して学習します。 ヘッダーのある任意のページに移動します。 Ctrl + Pを押して予測します。
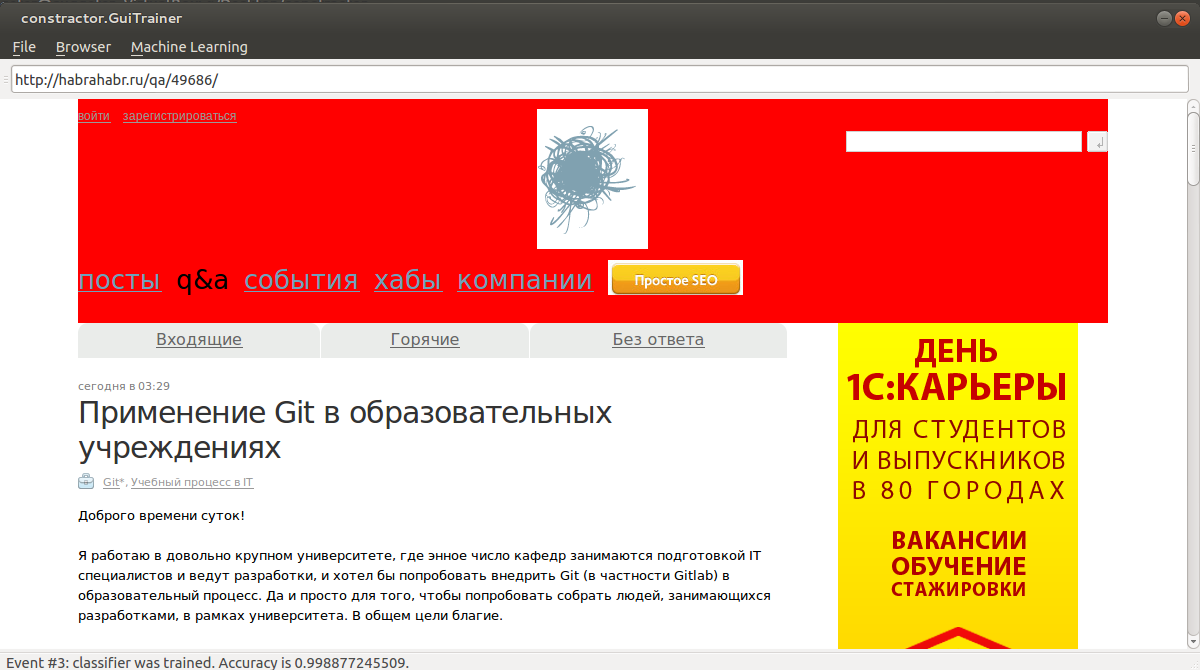
おわりに
ライブラリはまだ非常に未加工であり、多くの改善が必要です。
改善の計画:デフォルトファクターセットの拡張、さまざまなタイプのブロックを認識するための組み込みモデルの追加など。 もちろん、私は自由時間にこれらすべてを徐々に削減します。 ただし、自由時間に図書館に貢献する準備ができているhabrovoltsyがいる場合は非常に感謝します。
ご清聴ありがとうございました!