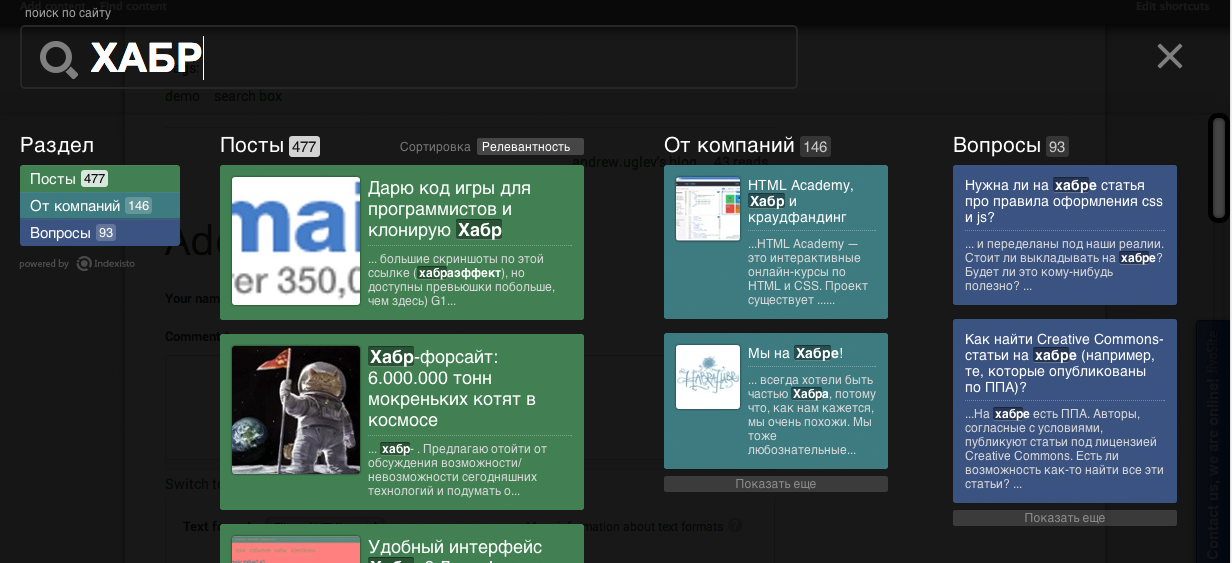
憂鬱な秋の朝、実験として、構造とスピードを備えたHabrの検索を撮影しました。 すべての作業には約10分かかりました。 新しい検索を表示するにはtykを読むのが面倒な人 (ブログエントリの本文に直接入力する検索)
このような検索を取得するために、データベースへのアクセス、またはAPIを介した記事のアップロードを求めませんでした。 すべては非常に簡単に通常のクローラーを介して行われます。 たとえば、約5,000件の記事を走り書きしました。
背景
みなさんこんにちは。 Indexistoサイトの迅速な構造化検索(+ ハブに関する投稿 )を行っていることを思い出させてください。 長い間、私たちから何も聞かれませんでしたが、ついにリリースを発表しました。
最初の公開後、多くの人が私たちがやっていることを気に入っており、多くの人が実装を望んでいました。 接続した最初の人々に非常に感謝しています-私たちは見つけられなかったであろう多くの「微妙さ」を見ました。 すべてをすばやく修復し、同時に単一の「ライブ」インデックスを削除しませんでした。 ただし、構造的な問題がありました。
-エントリのしきい値が非常に高い。 高度なデータベース接続、テンプレートの高度な設定、検索クエリ、アナライザーなど
クライアントの設定を手動で設定することでこの問題を解決しました(たとえば、 maximonline.ruで出力を確認できます)。また、早期導入者が必要であるという説明もあります。 同時に、(バグに加えて)開発がほぼ立ち上がったため、私たちはインテグレーターになるか、インターネットプロジェクトを維持するために何かを変更する必要があることに気付きました。
イベントの開発
今日は、接続の問題に対する根本的な解決策を提示したいと思います。サイトのURLを入力するだけで、検索結果をすぐに取得できます。 それだけです。
他のすべては自動的に行われます。 多くの複雑な設定が既製のテンプレートから取得され、インデックスに適用されます。 同時に、管理者パネルは完全に縮小されました-チェックボックスとドロップダウンリストに。 ハードコアのファンのために、アドバンスモードに切り替える機会を残しました。
クローラーとパーサー
これで、クローラーとコンテンツパーサーができました。 クローラーは、比較的合理的なページを提供します。ページ付け、さまざまなフィード、プレゼンテーションの変更(Sort = date.ascなど)を破棄することを多少なりとも学習しました。 しかし、クローラーが完全に機能していても、メニュー、右列と左列のブロックなど、大量の記事が含まれているページがあります。 それに直面してみましょう、私たちが私たちのポジショニングを固守するならば、私は本当に検索結果でこれをすべて見たくありません。
ここでは、間違いなくUberシステムにアクセスします。パーサーは、ページから任意のデータを抽出できるようにします。
概念的には、システムは2つのアプローチを組み合わせます。
- 浅いテキスト機能を使用したこのボイラープレート検出などのアルゴリズムに基づいてコンテンツを自動的に取得します 。 それについては別の投稿になります。
- xpathを使用した「額」内のデータの抽出。 単純な理由で、 xpathを使用すると、特定のタグ内のテキストを検索できます。たとえば、
//span[contains(@class, 'post_title')]
- post_titleクラスを使用してspanタグからヘッダーを引き出します。
システムは、追加設定なしで、または特定のサイトの手動設定を使用して、両方で動作できます。
コンテンツを抽出するためのパーサーマスク
マスクに保存するすべてのxpath設定
パーサーは入り口でページを受け取り、別のマスクでページを実行し始めます。 各マスクは、HTMLページから何かを分離し、受信したドキュメントに追加しようとします:タイトル、画像、記事テキスト。 たとえば、Open Graphタグを抽出し、その内容をドキュメントに追加するマスクがあります。
<mask name="ogHighPrecision" level="0.50123"> <document name="ogHighPrecisionTags"> <field name="_url">//meta[contains(@property, 'og:url')]/@content</field> <field name="_subtype">//meta[contains(@property, 'og:type')]/@content</field> <field name="_image">//meta[contains(@property, 'og:image')]/@content</field> <field name="title">//meta[contains(@property, 'og:title')]/@content</field> <field name="description">//meta[contains(@property, 'og:description')]/@content</field> <field name="siteName">//meta[contains(@property, 'og:site_name')]/@content</field> </document> </mask>
すでに理解しているように、マスクはXMLで記述します。 コードには特別な説明は必要ありません)
OG、microdata、noindexのページの破棄など、このようなマスクは非常に多くあります。
したがって、原則として、サイトのアドレスを入力し、受け入れ可能な返品を得ることができます。
しかし、多くの人は受け入れられるだけでなく、完璧であることを望んでいます。 そしてここで、 xpathを自分で書く機会を提供します。
カスタムマスク
余分な水なしで、Habrからデータを抽出する方法を見てみましょう
<?xml version="1.0" encoding="UTF-8"?> <mask name="habrahabrBody" level="0.21"> <allowUrl>/company/</allowUrl> <allowUrl>/events/</allowUrl> <allowUrl>/post/</allowUrl> <allowUrl>/qa/</allowUrl> <document name="habrahabrBody"> <field name="body" required="true">//div[contains(@class, 'html_format')]</field> <field name="title" required="true">//span[contains(@class, 'post_title')]</field> </document> </mask>
コードには説明は必要ありません)実際、このマスクに伝えました:投稿、企業、イベント、質問のページでのみ動作し、 html_formatクラスでdivから記事の本文を取得し、 post_titleクラスでspanからヘッダーを取得します
画像の抽出は、Open Graphタグを使用してシステム(組み込み)マスクのレベルで行われるため、マスク内の画像については何も覚えていません。
将来的には、Googleがウェブマスターパネルにあるように、このプロセスをさらに簡単にしようとします( ビデオ )