Oracleクラスターは死んでおり、長期にわたるクラスタリングです!
以下では、Oracle Real Application Custerではなくクラスタデータストレージを参照します
発行
大規模な情報システムの特徴は、さまざまな情報が絶え間なく流れ、蓄積され、計算され、アーカイブされることです。 Oracle RDBMSサーバーに格納された構造化データのオプションを検討し、通信事業者の加入者のCDRレコード(つまり、コールレコード)を含むテーブルを例として取り上げます。
呼び出しデータはランダムに受信されます。 ご承知のとおり、サブスクライバーの属性によって順序付けされていません。 すべてのデータには独自のライフサイクルがあります-運用、関連、アーカイブ。 時間が経つにつれて、呼び出しの頻度とデータアクセス速度の要件が変化します(つまり、低下します)。 T.O. 1年前のレコードは遅いディスクに、アクティブなレコードはアクセス速度が高く、書き込み操作のパフォーマンスを主張せずにディスクに保存できますが、通常、新しいデータには最高の書き込みおよび読み取り速度の要件があります。
クラスタテーブルにデータを保存するオプションを検討する
データは共通ベースで統合されます。 サブスクライバーの識別子に基づいて構築されたクラスターに1つ以上のテーブルを配置できます。1つの識別子でデータにアクセスすると、このサブスクライバーのすべてのデータはクラスターチャンクのサイズに正確な同じ場所に保存されます。 つまり すべてのデータが2つのデータベースブロックにある2つのチャンクに注がれている場合、指定されたユーザーの100行のデータを取得するには、2つのデータベースブロックのみを差し引くだけで十分です。 データがテーブルに従って分散されている場合、100データベースブロックを読み取って同じ100行を取得できます。 データアクセスレベルでの利点は明らかです。
次の特性は、クラスターストレージに起因します。
- データは共通ベースで統合されます。
- クラスターキーでアクセスする場合、ディスクIOは最小化されます。
- テーブルを一緒に格納するときにクラスターキーと結合すると、ディスクIOは最小化されます。
- 充填時に高いディスクIOが特徴です。
- パラレルDMLにはあまり適していません-高レベルのシリアル化。
通常のテーブルにデータを保存するオプションを検討してください
- データは通常、受信した順序で保存されます。
- 高い充填速度が特徴です。
- 並列DMLに優しい。
- データ量が増加すると、インデックスにより挿入率の低下が始まる場合があります。
- (インデックスによる)選択性の高いサンプリングでは、高いDiskIOが観察されます。
データ編成の要件
一般に、顧客はデータの正しい編成から次の特性を期待します。
- 特に高速DMLおよび挿入。
- 高いサンプリングレート。
- 優れたスケーラビリティ。
- 管理が簡単。
データ分割
ストレージの効率を高める1つの方法は、Oracle Partitioning Optionを使用することです。
- 長さの内訳(挿入パフォーマンスの低下時間の短縮)。
- 幅の内訳(スケーラビリティの向上)。
- 各セグメントを個別に管理する機能。
- セグメント化されたオブジェクトに対する高効率の並列操作。
たとえば、幅のセグメントに分割する場合、インデックスセグメントの予想は、このオブジェクトで競合するDML操作の数が増加する通常のテーブルと比較して減少します。
2つのEQテーブルがハッシュ(N)によって何らかの識別子によってセグメント化されているとします。 この識別子を使用したEQパーティション結合操作中、HASH JOIN操作はテーブルレベルではなく、同じハッシュ値を持つセクションのレベルで実行されます。 これにより、特定の量のデータに対して指定された操作を実行するのに必要な時間が大幅に短縮されます。
また、データアクセスのクラスター効率をパーティションテーブルに付与したいと思います...
データクラスタリング
テーブルを取得してクラスター効率でデータを配信する最良の方法は、クラスターと同じ方法でテーブルを整理することです。
持っているデータの長さを受信日(期間ごとに1つのセクション)で分割し、幅をサブスクライバーIDでハッシュしたセクションを想像してください。 すべてのインデックスはローカルです。 データは順番に(日付で)受信され、サブスクライバーIDでランダムに受信されます。
メインセクションでは、期間のリクエストにパーティションプルーニングを使用でき、指定した期間のデータを含むセクションのみが含まれます。サブスクライバーIDからの追加のハッシュセグメンテーションにより、指定したサブスクライバーのデータを含むセクションのみを選択できます。 しかし、その後、データはセクションに分散され、たとえば、1日にサブスクライバあたり100レコードを受信するために、100のディスク読み取り操作を実行します。
ただし、1つの「BUT」があります。1日が過ぎて、昨日のデータがまだ到着する可能性がありますが、昨日の前日はすでにありそうにありません。 したがって、これを行うことができます:
- 次のように、テーブルと同じハッシュセグメンテーション原理を使用して、セグメント化されたテーブルと同じフィールドセットを持つテーブルを作成します。
create table TBL1 as select * from table %TBL% partition(P1) order by subscriber_id, record_date...
- テーブルセクションと同じインデックスを作成します。
- 操作を実行する
alter table %TBL% exchange partition P1 with table TBL1
PS> dbms_redefinitionパッケージを使用して、このプロセスを自動化できます。
すべてがシンプルに見えますが、あなたは何を求めますか?
次に、4つのケースを検討します。
- データは再編成されません。
- 作成されたインデックスの再構築。
- 再編成。
- データ圧縮で再編成。
高物理IOクラスタリング
したがって、約100のプロセスを同時に開始し、指定された期間にランダムなサブスクライバIDでデータにアクセスすると、1つのプロセスの平均生産性は、データの組織に応じて次のように異なります。
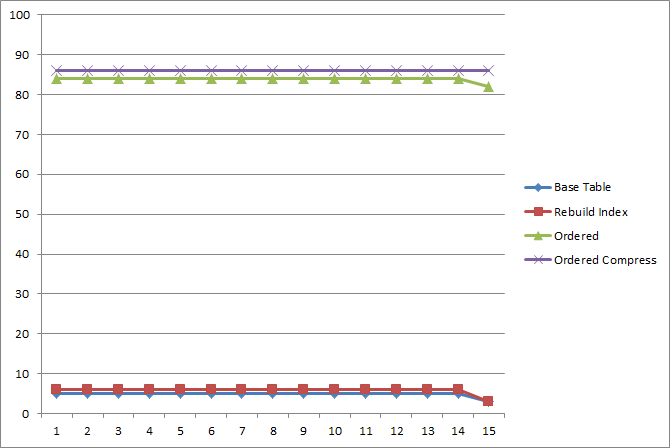
つまり 1セクションの期間、クライアントごとに約13〜19レコードの特性を持つデータについて、ディスクIOのパフォーマンスを大幅に向上させることができました。
以下は、I / Oの期待値と応答時間に関するデータです。
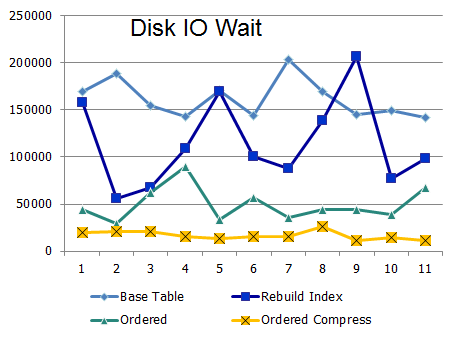

高論理IOクラスタリング
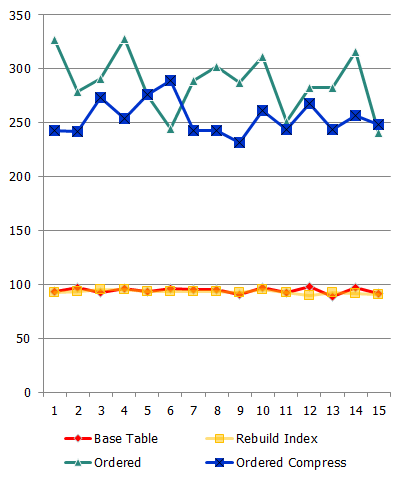
今、Oracleサーバーのメモリにあり、ディスクから読み取られていないデータにアクセスしていると想像してください。 論理IOのみが使用されている場合、そのような組織で得られる(および得られる)ものは何ですか。
プロセスパフォーマンス(要求/秒):
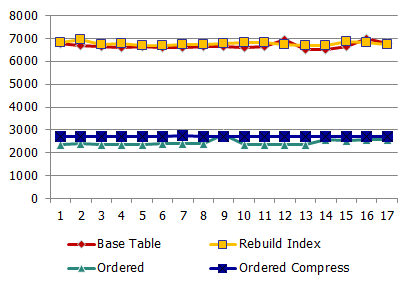
待機時間:
および応答時間:
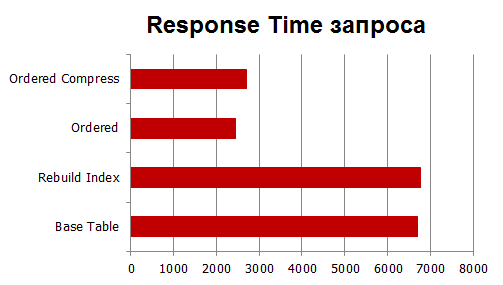
ご覧のとおり、増加は物理IOの場合よりも小さいですが、とにかく、増加は時々発生します。
データボリューム管理
通常の再構築インデックスの操作でさえ、そのサイズを縮小します。 データ再編成中のディスク容量と圧縮の使用はどうなりますか?
圧縮の効果(圧縮):
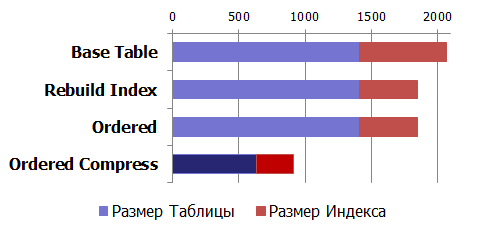

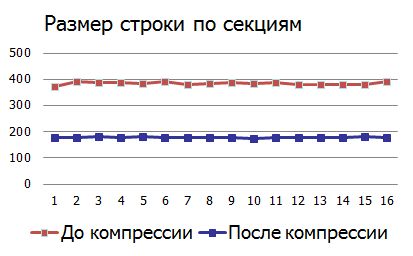
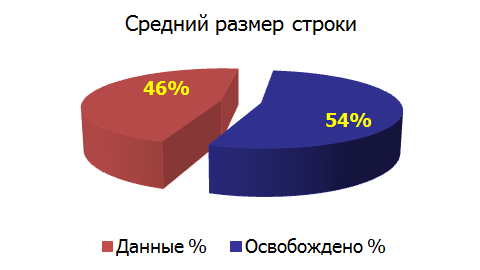
おわりに
データ再編成による特定の情報システムのデータ構造の詳細を考えると、次のことを実現できます。
- 個々の操作のパフォーマンスを改善します。
- リソースが解放されるため、システム全体のパフォーマンスが向上します。
- 消費されるリソースの量の減少、すなわち ソリューションのコストを節約できます。
- ...
PS>大量のデータの再編成は非常に費用のかかる操作のように思えるかもしれません。 もちろん、これは可能ですが、最終的には、I / O操作の量を減らすことができます。 例として顧客データを使用すると、セルフサービスシステム(テーブルの半分以下の負荷)によってのみ1時間以内にこの方法で再編成されたテーブルにアクセスすると、1日あたりのすべてのセクションのサイズよりも大きいこのテーブルへの入出力ボリュームが作成されたと言えます。 したがって、DBAにとって追加の作業を作成しますが、ゲームはろうそくの価値があります。